 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlignGS: Aligning Geometry and Semantics for Robust Indoor Reconstruction from Sparse Views
Paper and Code
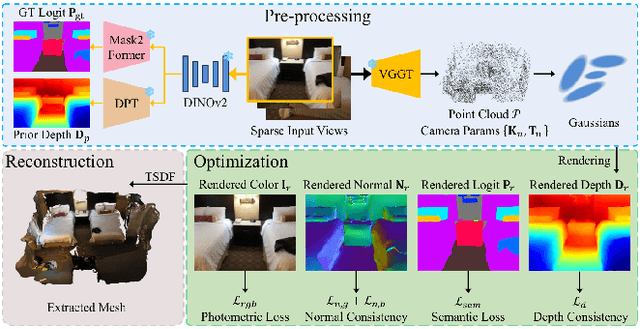
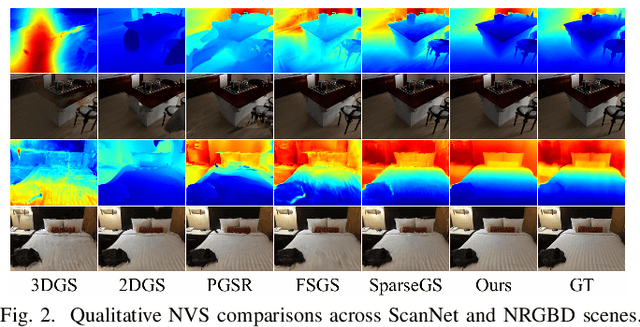
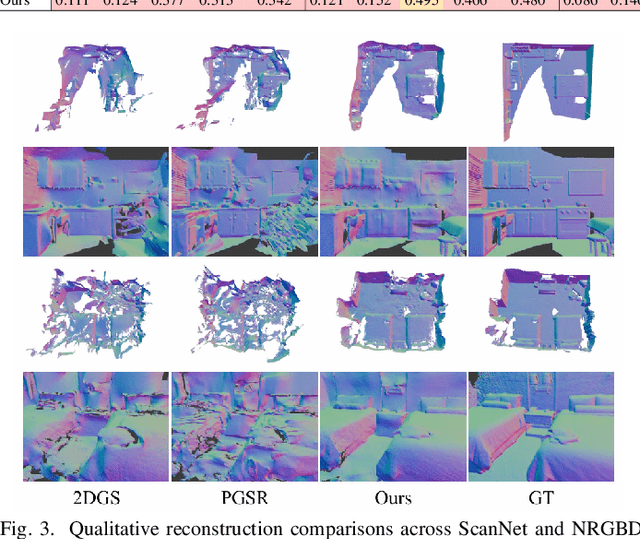
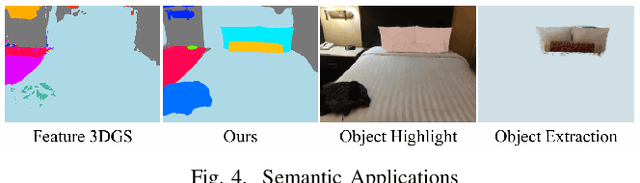
The demand for semantically rich 3D models of indoor scenes is rapidly growing, driven by applications in augmented reality, virtual reality, and robotics. However, creating them from sparse views remains a challenge due to geometric ambiguity. Existing methods often treat semantics as a passive feature painted on an already-formed, and potentially flawed, geometry. We posit that for robust sparse-view reconstruction, semantic understanding instead be an active, guiding force. This paper introduces AlignGS, a novel framework that actualizes this vision by pioneering a synergistic, end-to-end optimization of geometry and semantics. Our method distills rich priors from 2D foundation models and uses them to directly regularize the 3D representation through a set of novel semantic-to-geometry guidance mechanisms, including depth consistency and multi-faceted normal regularization. Extensive evaluations on standard benchmarks demonstrate that our approach achieves state-of-the-art results in novel view synthesis and produces reconstructions with superior geometric accuracy. The results validate that leveraging semantic priors as a geometric regularizer leads to more coherent and complete 3D models from limited input views. Our code is avaliable at https://github.com/MediaX-SJTU/AlignGS .