 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDLF: Disentangled-Language-Focused Multimodal Sentiment Analysis
Dec 16, 2024
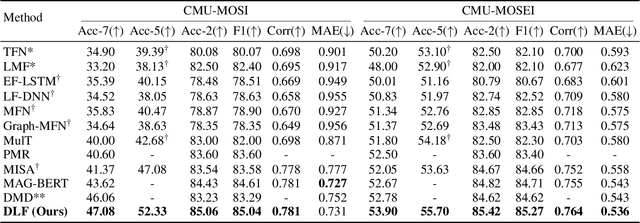
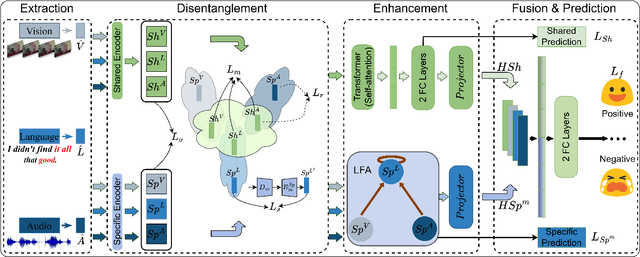
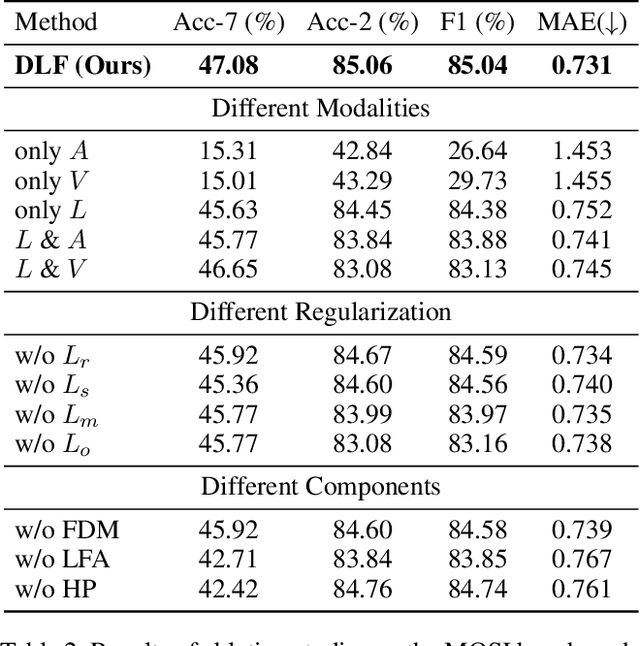
Multimodal Sentiment Analysis (MSA) leverages heterogeneous modalities, such as language, vision, and audio, to enhance the understanding of human sentiment. While existing models often focus on extracting shared information across modalities or directly fusing heterogeneous modalities, such approaches can introduce redundancy and conflicts due to equal treatment of all modalities and the mutual transfer of information between modality pairs. To address these issues, we propose a Disentangled-Language-Focused (DLF) multimodal representation learning framework, which incorporates a feature disentanglement module to separate modality-shared and modality-specific information. To further reduce redundancy and enhance language-targeted features, four geometric measures are introduced to refine the disentanglement process. A Language-Focused Attractor (LFA) is further developed to strengthen language representation by leveraging complementary modality-specific information through a language-guided cross-attention mechanism. The framework also employs hierarchical predictions to improve overall accuracy. Extensive experiments on two popular MSA datasets, CMU-MOSI and CMU-MOSEI, demonstrate the significant performance gains achieved by the proposed DLF framework. Comprehensive ablation studies further validate the effectiveness of the feature disentanglement module, language-focused attractor, and hierarchical predictions. Our code is available at https://github.com/pwang322/DLF.
KAAE: Numerical Reasoning for Knowledge Graphs via Knowledge-aware Attributes Learning
Nov 20, 2024



Numerical reasoning is pivotal in various artificial intelligence applications, such as natural language processing and recommender systems, where it involves using entities, relations, and attribute values (e.g., weight, length) to infer new factual relations (e.g., the Nile is longer than the Amazon). However, existing approaches encounter two critical challenges in modeling: (1) semantic relevance-the challenge of insufficiently capturing the necessary contextual interactions among entities, relations, and numerical attributes, often resulting in suboptimal inference; and (2) semantic ambiguity-the difficulty in accurately distinguishing ordinal relationships during numerical reasoning, which compromises the generation of high-quality samples and limits the effectiveness of contrastive learning. To address these challenges, we propose the novel Knowledge-Aware Attributes Embedding model (KAAE) for knowledge graph embeddings in numerical reasoning. Specifically, to overcome the challenge of semantic relevance, we introduce a Mixture-of-Experts-Knowledge-Aware (MoEKA) Encoder, designed to integrate the semantics of entities, relations, and numerical attributes into a joint semantic space. To tackle semantic ambiguity, we implement a new ordinal knowledge contrastive learning (OKCL) strategy that generates high-quality ordinal samples from the original data with the aid of ordinal relations, capturing fine-grained semantic nuances essential for accurate numerical reasoning. Experiments on three public benchmark datasets demonstrate the superior performance of KAAE across various attribute value distributions.
Motion Control for Enhanced Complex Action Video Generation
Nov 13, 2024



Existing text-to-video (T2V) models often struggle with generating videos with sufficiently pronounced or complex actions. A key limitation lies in the text prompt's inability to precisely convey intricate motion details. To address this, we propose a novel framework, MVideo, designed to produce long-duration videos with precise, fluid actions. MVideo overcomes the limitations of text prompts by incorporating mask sequences as an additional motion condition input, providing a clearer, more accurate representation of intended actions. Leveraging foundational vision models such as GroundingDINO and SAM2, MVideo automatically generates mask sequences, enhancing both efficiency and robustness. Our results demonstrate that, after training, MVideo effectively aligns text prompts with motion conditions to produce videos that simultaneously meet both criteria. This dual control mechanism allows for more dynamic video generation by enabling alterations to either the text prompt or motion condition independently, or both in tandem. Furthermore, MVideo supports motion condition editing and composition, facilitating the generation of videos with more complex actions. MVideo thus advances T2V motion generation, setting a strong benchmark for improved action depiction in current video diffusion models. Our project page is available at https://mvideo-v1.github.io/.
Multimodal LLM Enhanced Cross-lingual Cross-modal Retrieval
Sep 30, 2024



Cross-lingual cross-modal retrieval (CCR) aims to retrieve visually relevant content based on non-English queries, without relying on human-labeled cross-modal data pairs during training. One popular approach involves utilizing machine translation (MT) to create pseudo-parallel data pairs, establishing correspondence between visual and non-English textual data. However, aligning their representations poses challenges due to the significant semantic gap between vision and text, as well as the lower quality of non-English representations caused by pre-trained encoders and data noise. To overcome these challenges, we propose LECCR, a novel solution that incorporates the multi-modal large language model (MLLM) to improve the alignment between visual and non-English representations. Specifically, we first employ MLLM to generate detailed visual content descriptions and aggregate them into multi-view semantic slots that encapsulate different semantics. Then, we take these semantic slots as internal features and leverage them to interact with the visual features. By doing so, we enhance the semantic information within the visual features, narrowing the semantic gap between modalities and generating local visual semantics for subsequent multi-level matching. Additionally, to further enhance the alignment between visual and non-English features, we introduce softened matching under English guidance. This approach provides more comprehensive and reliable inter-modal correspondences between visual and non-English features. Extensive experiments on four CCR benchmarks, \ie Multi30K, MSCOCO, VATEX, and MSR-VTT-CN, demonstrate the effectiveness of our proposed method. Code: \url{https://github.com/LiJiaBei-7/leccr}.
I2EBench: A Comprehensive Benchmark for Instruction-based Image Editing
Aug 26, 2024



Significant progress has been made in the field of Instruction-based Image Editing (IIE). However, evaluating these models poses a significant challenge. A crucial requirement in this field is the establishment of a comprehensive evaluation benchmark for accurately assessing editing results and providing valuable insights for its further development. In response to this need, we propose I2EBench, a comprehensive benchmark designed to automatically evaluate the quality of edited images produced by IIE models from multiple dimensions. I2EBench consists of 2,000+ images for editing, along with 4,000+ corresponding original and diverse instructions. It offers three distinctive characteristics: 1) Comprehensive Evaluation Dimensions: I2EBench comprises 16 evaluation dimensions that cover both high-level and low-level aspects, providing a comprehensive assessment of each IIE model. 2) Human Perception Alignment: To ensure the alignment of our benchmark with human perception, we conducted an extensive user study for each evaluation dimension. 3) Valuable Research Insights: By analyzing the advantages and disadvantages of existing IIE models across the 16 dimensions, we offer valuable research insights to guide future development in the field. We will open-source I2EBench, including all instructions, input images, human annotations, edited images from all evaluated methods, and a simple script for evaluating the results from new IIE models. The code, dataset and generated images from all IIE models are provided in github: https://github.com/cocoshe/I2EBench.
INF-LLaVA: Dual-perspective Perception for High-Resolution Multimodal Large Language Model
Jul 23, 2024With advancements in data availability and computing resources, Multimodal Large Language Models (MLLMs) have showcased capabilities across various fields. However, the quadratic complexity of the vision encoder in MLLMs constrains the resolution of input images. Most current approaches mitigate this issue by cropping high-resolution images into smaller sub-images, which are then processed independently by the vision encoder. Despite capturing sufficient local details, these sub-images lack global context and fail to interact with one another. To address this limitation, we propose a novel MLLM, INF-LLaVA, designed for effective high-resolution image perception. INF-LLaVA incorporates two innovative components. First, we introduce a Dual-perspective Cropping Module (DCM), which ensures that each sub-image contains continuous details from a local perspective and comprehensive information from a global perspective. Second, we introduce Dual-perspective Enhancement Module (DEM) to enable the mutual enhancement of global and local features, allowing INF-LLaVA to effectively process high-resolution images by simultaneously capturing detailed local information and comprehensive global context. Extensive ablation studies validate the effectiveness of these components, and experiments on a diverse set of benchmarks demonstrate that INF-LLaVA outperforms existing MLLMs. Code and pretrained model are available at https://github.com/WeihuangLin/INF-LLaVA.
Gaussian Process Model with Tensorial Inputs and Its Application to the Design of 3D Printed Antennas
Jul 19, 2024



In simulation-based engineering design with time-consuming simulators, Gaussian process (GP) models are widely used as fast emulators to speed up the design optimization process. In its most commonly used form, the input of GP is a simple list of design parameters. With rapid development of additive manufacturing (also known as 3D printing), design inputs with 2D/3D spatial information become prevalent in some applications, for example, neighboring relations between pixels/voxels and material distributions in heterogeneous materials. Such spatial information, vital to 3D printed designs, is hard to incorporate into existing GP models with common kernels such as squared exponential or Mat\'ern. In this work, we propose to embed a generalized distance measure into a GP kernel, offering a novel and convenient technique to incorporate spatial information from freeform 3D printed designs into the GP framework. The proposed method allows complex design problems for 3D printed objects to take advantage of a plethora of tools available from the GP surrogate-based simulation optimization such as designed experiments and GP-based optimizations including Bayesian optimization. We investigate the properties of the proposed method and illustrate its performance by several numerical examples of 3D printed antennas. The dataset is publicly available at: https://github.com/xichennn/GP_dataset.
Training LLMs to Better Self-Debug and Explain Code
May 28, 2024



In the domain of code generation, self-debugging is crucial. It allows LLMs to refine their generated code based on execution feedback. This is particularly important because generating correct solutions in one attempt proves challenging for complex tasks. Prior works on self-debugging mostly focus on prompting methods by providing LLMs with few-shot examples, which work poorly on small open-sourced LLMs. In this work, we propose a training framework that significantly improves self-debugging capability of LLMs. Intuitively, we observe that a chain of explanations on the wrong code followed by code refinement helps LLMs better analyze the wrong code and do refinement. We thus propose an automated pipeline to collect a high-quality dataset for code explanation and refinement by generating a number of explanations and refinement trajectories and filtering via execution verification. We perform supervised fine-tuning (SFT) and further reinforcement learning (RL) on both success and failure trajectories with a novel reward design considering code explanation and refinement quality. SFT improves the pass@1 by up to 15.92% and pass@10 by 9.30% over four benchmarks. RL training brings additional up to 3.54% improvement on pass@1 and 2.55% improvement on pass@10. The trained LLMs show iterative refinement ability, and can keep refining code continuously. Lastly, our human evaluation shows that the LLMs trained with our framework generate more useful code explanations and help developers better understand bugs in source code.
Continuous-Multiple Image Outpainting in One-Step via Positional Query and A Diffusion-based Approach
Jan 28, 2024Image outpainting aims to generate the content of an input sub-image beyond its original boundaries. It is an important task in content generation yet remains an open problem for generative models. This paper pushes the technical frontier of image outpainting in two directions that have not been resolved in literature: 1) outpainting with arbitrary and continuous multiples (without restriction), and 2) outpainting in a single step (even for large expansion multiples). Moreover, we develop a method that does not depend on a pre-trained backbone network, which is in contrast commonly required by the previous SOTA outpainting methods. The arbitrary multiple outpainting is achieved by utilizing randomly cropped views from the same image during training to capture arbitrary relative positional information. Specifically, by feeding one view and positional embeddings as queries, we can reconstruct another view. At inference, we generate images with arbitrary expansion multiples by inputting an anchor image and its corresponding positional embeddings. The one-step outpainting ability here is particularly noteworthy in contrast to previous methods that need to be performed for $N$ times to obtain a final multiple which is $N$ times of its basic and fixed multiple. We evaluate the proposed approach (called PQDiff as we adopt a diffusion-based generator as our embodiment, under our proposed \textbf{P}ositional \textbf{Q}uery scheme) on public benchmarks, demonstrating its superior performance over state-of-the-art approaches. Specifically, PQDiff achieves state-of-the-art FID scores on the Scenery (\textbf{21.512}), Building Facades (\textbf{25.310}), and WikiArts (\textbf{36.212}) datasets. Furthermore, under the 2.25x, 5x and 11.7x outpainting settings, PQDiff only takes \textbf{40.6\%}, \textbf{20.3\%} and \textbf{10.2\%} of the time of the benchmark state-of-the-art (SOTA) method.
DMT: Comprehensive Distillation with Multiple Self-supervised Teachers
Dec 19, 2023



Numerous self-supervised learning paradigms, such as contrastive learning and masked image modeling, have been proposed to acquire powerful and general representations from unlabeled data. However, these models are commonly pretrained within their specific framework alone, failing to consider the complementary nature of visual representations. To tackle this issue, we introduce Comprehensive Distillation with Multiple Self-supervised Teachers (DMT) for pretrained model compression, which leverages the strengths of multiple off-the-shelf self-supervised models. Our experimental results on prominent benchmark datasets exhibit that the proposed method significantly surpasses state-of-the-art competitors while retaining favorable efficiency metrics. On classification tasks, our DMT framework utilizing three different self-supervised ViT-Base teachers enhances the performance of both small/tiny models and the base model itself. For dense tasks, DMT elevates the AP/mIoU of standard SSL models on MS-COCO and ADE20K datasets by 4.0%.