 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompassAD: Intent-Driven 3D Affordance Grounding in Functionally Competing Objects
Apr 02, 2026When told to "cut the apple," a robot must choose the knife over nearby scissors, despite both objects affording the same cutting function. In real-world scenes, multiple objects may share identical affordances, yet only one is appropriate under the given task context. We call such cases confusing pairs. However, existing 3D affordance methods largely sidestep this challenge by evaluating isolated single objects, often with explicit category names provided in the query. We formalize Multi-Object Affordance Grounding under Intent-Driven Instructions, a new 3D affordance setting that requires predicting a per-point affordance mask on the correct object within a cluttered multi-object point cloud, conditioned on implicit natural language intent. To study this problem, we construct CompassAD, the first benchmark centered on implicit intent in confusable multi-object scenes. It comprises 30 confusing object pairs spanning 16 affordance types, 6,422 scenes, and 88K+ query-answer pairs. Furthermore, we propose CompassNet, a framework that incorporates two dedicated modules tailored to this task. Instance-bounded Cross Injection (ICI) constrains language-geometry alignment within object boundaries to prevent cross-object semantic leakage. Bi-level Contrastive Refinement (BCR) enforces discrimination at both geometric-group and point levels, sharpening distinctions between target and confusable surfaces. Extensive experiments demonstrate state-of-the-art results on both seen and unseen queries, and deployment on a robotic manipulator confirms effective transfer to real-world grasping in confusing multi-object scenes.
Action-to-Action Flow Matching
Feb 07, 2026Diffusion-based policies have recently achieved remarkable success in robotics by formulating action prediction as a conditional denoising process. However, the standard practice of sampling from random Gaussian noise often requires multiple iterative steps to produce clean actions, leading to high inference latency that incurs a major bottleneck for real-time control. In this paper, we challenge the necessity of uninformed noise sampling and propose Action-to-Action flow matching (A2A), a novel policy paradigm that shifts from random sampling to initialization informed by the previous action. Unlike existing methods that treat proprioceptive action feedback as static conditions, A2A leverages historical proprioceptive sequences, embedding them into a high-dimensional latent space as the starting point for action generation. This design bypasses costly iterative denoising while effectively capturing the robot's physical dynamics and temporal continuity. Extensive experiments demonstrate that A2A exhibits high training efficiency, fast inference speed, and improved generalization. Notably, A2A enables high-quality action generation in as few as a single inference step (0.56 ms latency), and exhibits superior robustness to visual perturbations and enhanced generalization to unseen configurations. Lastly, we also extend A2A to video generation, demonstrating its broader versatility in temporal modeling. Project site: https://lorenzo-0-0.github.io/A2A_Flow_Matching.
ES-MVSNet: Efficient Framework for End-to-end Self-supervised Multi-View Stereo
Aug 04, 2023



Compared to the multi-stage self-supervised multi-view stereo (MVS) method, the end-to-end (E2E) approach has received more attention due to its concise and efficient training pipeline. Recent E2E self-supervised MVS approaches have integrated third-party models (such as optical flow models, semantic segmentation models, NeRF models, etc.) to provide additional consistency constraints, which grows GPU memory consumption and complicates the model's structure and training pipeline. In this work, we propose an efficient framework for end-to-end self-supervised MVS, dubbed ES-MVSNet. To alleviate the high memory consumption of current E2E self-supervised MVS frameworks, we present a memory-efficient architecture that reduces memory usage by 43% without compromising model performance. Furthermore, with the novel design of asymmetric view selection policy and region-aware depth consistency, we achieve state-of-the-art performance among E2E self-supervised MVS methods, without relying on third-party models for additional consistency signals. Extensive experiments on DTU and Tanks&Temples benchmarks demonstrate that the proposed ES-MVSNet approach achieves state-of-the-art performance among E2E self-supervised MVS methods and competitive performance to many supervised and multi-stage self-supervised methods.
Improved Neural Radiance Fields Using Pseudo-depth and Fusion
Jul 27, 2023Since the advent of Neural Radiance Fields, novel view synthesis has received tremendous attention. The existing approach for the generalization of radiance field reconstruction primarily constructs an encoding volume from nearby source images as additional inputs. However, these approaches cannot efficiently encode the geometric information of real scenes with various scale objects/structures. In this work, we propose constructing multi-scale encoding volumes and providing multi-scale geometry information to NeRF models. To make the constructed volumes as close as possible to the surfaces of objects in the scene and the rendered depth more accurate, we propose to perform depth prediction and radiance field reconstruction simultaneously. The predicted depth map will be used to supervise the rendered depth, narrow the depth range, and guide points sampling. Finally, the geometric information contained in point volume features may be inaccurate due to occlusion, lighting, etc. To this end, we propose enhancing the point volume feature from depth-guided neighbor feature fusion. Experiments demonstrate the superior performance of our method in both novel view synthesis and dense geometry modeling without per-scene optimization.
Points-to-3D: Bridging the Gap between Sparse Points and Shape-Controllable Text-to-3D Generation
Jul 26, 2023Text-to-3D generation has recently garnered significant attention, fueled by 2D diffusion models trained on billions of image-text pairs. Existing methods primarily rely on score distillation to leverage the 2D diffusion priors to supervise the generation of 3D models, e.g., NeRF. However, score distillation is prone to suffer the view inconsistency problem, and implicit NeRF modeling can also lead to an arbitrary shape, thus leading to less realistic and uncontrollable 3D generation. In this work, we propose a flexible framework of Points-to-3D to bridge the gap between sparse yet freely available 3D points and realistic shape-controllable 3D generation by distilling the knowledge from both 2D and 3D diffusion models. The core idea of Points-to-3D is to introduce controllable sparse 3D points to guide the text-to-3D generation. Specifically, we use the sparse point cloud generated from the 3D diffusion model, Point-E, as the geometric prior, conditioned on a single reference image. To better utilize the sparse 3D points, we propose an efficient point cloud guidance loss to adaptively drive the NeRF's geometry to align with the shape of the sparse 3D points. In addition to controlling the geometry, we propose to optimize the NeRF for a more view-consistent appearance. To be specific, we perform score distillation to the publicly available 2D image diffusion model ControlNet, conditioned on text as well as depth map of the learned compact geometry. Qualitative and quantitative comparisons demonstrate that Points-to-3D improves view consistency and achieves good shape controllability for text-to-3D generation. Points-to-3D provides users with a new way to improve and control text-to-3D generation.
Foundation Model Drives Weakly Incremental Learning for Semantic Segmentation
Feb 28, 2023



Modern incremental learning for semantic segmentation methods usually learn new categories based on dense annotations. Although achieve promising results, pixel-by-pixel labeling is costly and time-consuming. Weakly incremental learning for semantic segmentation (WILSS) is a novel and attractive task, which aims at learning to segment new classes from cheap and widely available image-level labels. Despite the comparable results, the image-level labels can not provide details to locate each segment, which limits the performance of WILSS. This inspires us to think how to improve and effectively utilize the supervision of new classes given image-level labels while avoiding forgetting old ones. In this work, we propose a novel and data-efficient framework for WILSS, named FMWISS. Specifically, we propose pre-training based co-segmentation to distill the knowledge of complementary foundation models for generating dense pseudo labels. We further optimize the noisy pseudo masks with a teacher-student architecture, where a plug-in teacher is optimized with a proposed dense contrastive loss. Moreover, we introduce memory-based copy-paste augmentation to improve the catastrophic forgetting problem of old classes. Extensive experiments on Pascal VOC and COCO datasets demonstrate the superior performance of our framework, e.g., FMWISS achieves 70.7% and 73.3% in the 15-5 VOC setting, outperforming the state-of-the-art method by 3.4% and 6.1%, respectively.
LMSeg: Language-guided Multi-dataset Segmentation
Feb 27, 2023



It's a meaningful and attractive topic to build a general and inclusive segmentation model that can recognize more categories in various scenarios. A straightforward way is to combine the existing fragmented segmentation datasets and train a multi-dataset network. However, there are two major issues with multi-dataset segmentation: (1) the inconsistent taxonomy demands manual reconciliation to construct a unified taxonomy; (2) the inflexible one-hot common taxonomy causes time-consuming model retraining and defective supervision of unlabeled categories. In this paper, we investigate the multi-dataset segmentation and propose a scalable Language-guided Multi-dataset Segmentation framework, dubbed LMSeg, which supports both semantic and panoptic segmentation. Specifically, we introduce a pre-trained text encoder to map the category names to a text embedding space as a unified taxonomy, instead of using inflexible one-hot label. The model dynamically aligns the segment queries with the category embeddings. Instead of relabeling each dataset with the unified taxonomy, a category-guided decoding module is designed to dynamically guide predictions to each datasets taxonomy. Furthermore, we adopt a dataset-aware augmentation strategy that assigns each dataset a specific image augmentation pipeline, which can suit the properties of images from different datasets. Extensive experiments demonstrate that our method achieves significant improvements on four semantic and three panoptic segmentation datasets, and the ablation study evaluates the effectiveness of each component.
DS-MVSNet: Unsupervised Multi-view Stereo via Depth Synthesis
Aug 13, 2022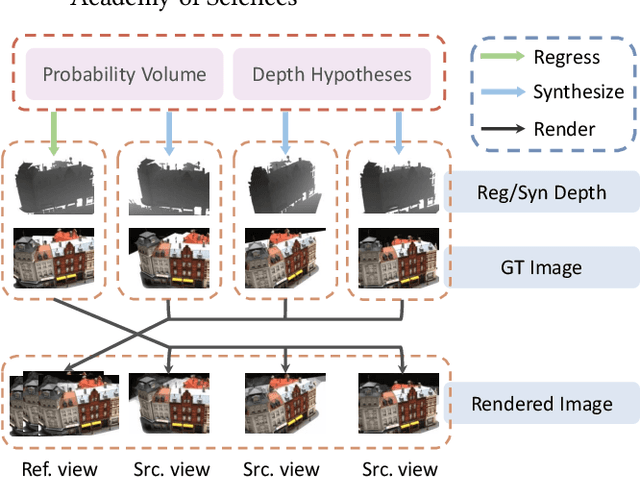
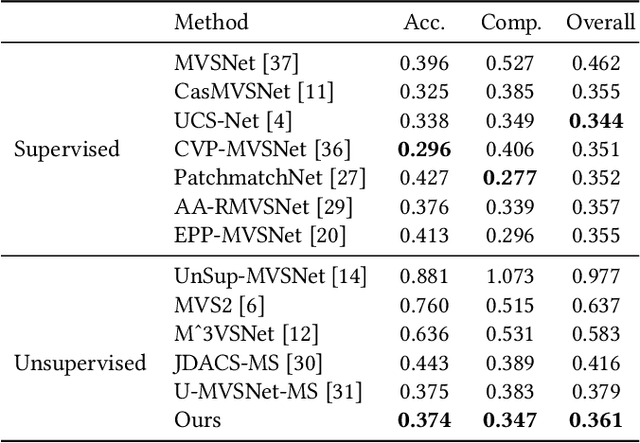


In recent years, supervised or unsupervised learning-based MVS methods achieved excellent performance compared with traditional methods. However, these methods only use the probability volume computed by cost volume regularization to predict reference depths and this manner cannot mine enough information from the probability volume. Furthermore, the unsupervised methods usually try to use two-step or additional inputs for training which make the procedure more complicated. In this paper, we propose the DS-MVSNet, an end-to-end unsupervised MVS structure with the source depths synthesis. To mine the information in probability volume, we creatively synthesize the source depths by splattering the probability volume and depth hypotheses to source views. Meanwhile, we propose the adaptive Gaussian sampling and improved adaptive bins sampling approach that improve the depths hypotheses accuracy. On the other hand, we utilize the source depths to render the reference images and propose depth consistency loss and depth smoothness loss. These can provide additional guidance according to photometric and geometric consistency in different views without additional inputs. Finally, we conduct a series of experiments on the DTU dataset and Tanks & Temples dataset that demonstrate the efficiency and robustness of our DS-MVSNet compared with the state-of-the-art methods.