 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond CLIP Generalization: Against Forward&Backward Forgetting Adapter for Continual Learning of Vision-Language Models
May 12, 2025This study aims to address the problem of multi-domain task incremental learning~(MTIL), which requires that vision-language models~(VLMs) continuously acquire new knowledge while maintaining their inherent zero-shot recognition capability. Existing paradigms delegate the testing of unseen-domain samples to the original CLIP, which only prevents the degradation of the model's zero-shot capability but fails to enhance the generalization of the VLM further. To this end, we propose a novel MTIL framework, named AFA, which comprises two core modules: (1) an against forward-forgetting adapter that learns task-invariant information for each dataset in the incremental tasks to enhance the zero-shot recognition ability of VLMs; (2) an against backward-forgetting adapter that strengthens the few-shot learning capability of VLMs while supporting incremental learning. Extensive experiments demonstrate that the AFA method significantly outperforms existing state-of-the-art approaches, especially in few-shot MTIL tasks, and surpasses the inherent zero-shot performance of CLIP in terms of transferability. The code is provided in the Supplementary Material.
Likelihood-Free Variational Autoencoders
Apr 24, 2025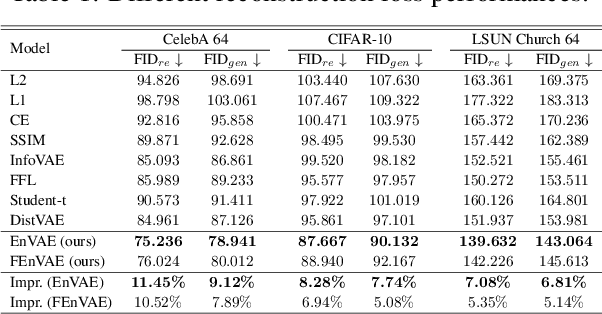
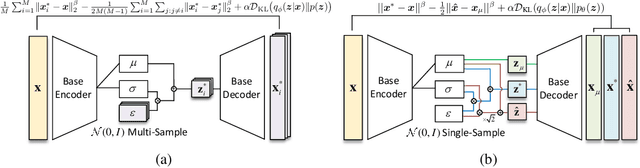
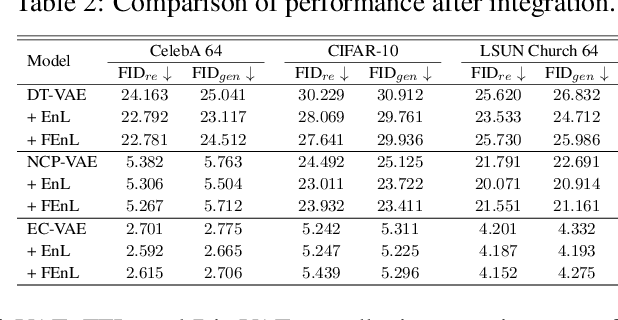
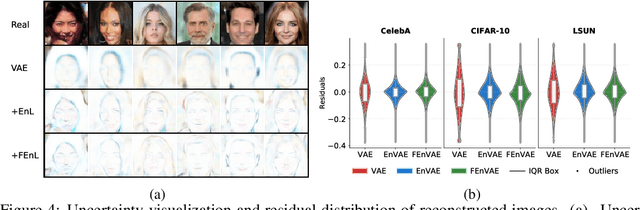
Variational Autoencoders (VAEs) typically rely on a probabilistic decoder with a predefined likelihood, most commonly an isotropic Gaussian, to model the data conditional on latent variables. While convenient for optimization, this choice often leads to likelihood misspecification, resulting in blurry reconstructions and poor data fidelity, especially for high-dimensional data such as images. In this work, we propose \textit{EnVAE}, a novel likelihood-free generative framework that has a deterministic decoder and employs the energy score -- a proper scoring rule -- to build the reconstruction loss. This enables likelihood-free inference without requiring explicit parametric density functions. To address the computational inefficiency of the energy score, we introduce a fast variant, \textit{FEnVAE}, based on the local smoothness of the decoder and the sharpness of the posterior distribution of latent variables. This yields an efficient single-sample training objective that integrates seamlessly into existing VAE pipelines with minimal overhead. Empirical results on standard benchmarks demonstrate that \textit{EnVAE} achieves superior reconstruction and generation quality compared to likelihood-based baselines. Our framework offers a general, scalable, and statistically principled alternative for flexible and nonparametric distribution learning in generative modeling.
Distribution-aware Forgetting Compensation for Exemplar-Free Lifelong Person Re-identification
Apr 22, 2025Lifelong Person Re-identification (LReID) suffers from a key challenge in preserving old knowledge while adapting to new information. The existing solutions include rehearsal-based and rehearsal-free methods to address this challenge. Rehearsal-based approaches rely on knowledge distillation, continuously accumulating forgetting during the distillation process. Rehearsal-free methods insufficiently learn the distribution of each domain, leading to forgetfulness over time. To solve these issues, we propose a novel Distribution-aware Forgetting Compensation (DAFC) model that explores cross-domain shared representation learning and domain-specific distribution integration without using old exemplars or knowledge distillation. We propose a Text-driven Prompt Aggregation (TPA) that utilizes text features to enrich prompt elements and guide the prompt model to learn fine-grained representations for each instance. This can enhance the differentiation of identity information and establish the foundation for domain distribution awareness. Then, Distribution-based Awareness and Integration (DAI) is designed to capture each domain-specific distribution by a dedicated expert network and adaptively consolidate them into a shared region in high-dimensional space. In this manner, DAI can consolidate and enhance cross-domain shared representation learning while alleviating catastrophic forgetting. Furthermore, we develop a Knowledge Consolidation Mechanism (KCM) that comprises instance-level discrimination and cross-domain consistency alignment strategies to facilitate model adaptive learning of new knowledge from the current domain and promote knowledge consolidation learning between acquired domain-specific distributions, respectively. Experimental results show that our DAFC outperforms state-of-the-art methods. Our code is available at https://github.com/LiuShiBen/DAFC.
FantasyTalking: Realistic Talking Portrait Generation via Coherent Motion Synthesis
Apr 07, 2025Creating a realistic animatable avatar from a single static portrait remains challenging. Existing approaches often struggle to capture subtle facial expressions, the associated global body movements, and the dynamic background. To address these limitations, we propose a novel framework that leverages a pretrained video diffusion transformer model to generate high-fidelity, coherent talking portraits with controllable motion dynamics. At the core of our work is a dual-stage audio-visual alignment strategy. In the first stage, we employ a clip-level training scheme to establish coherent global motion by aligning audio-driven dynamics across the entire scene, including the reference portrait, contextual objects, and background. In the second stage, we refine lip movements at the frame level using a lip-tracing mask, ensuring precise synchronization with audio signals. To preserve identity without compromising motion flexibility, we replace the commonly used reference network with a facial-focused cross-attention module that effectively maintains facial consistency throughout the video. Furthermore, we integrate a motion intensity modulation module that explicitly controls expression and body motion intensity, enabling controllable manipulation of portrait movements beyond mere lip motion. Extensive experimental results show that our proposed approach achieves higher quality with better realism, coherence, motion intensity, and identity preservation. Ours project page: https://fantasy-amap.github.io/fantasy-talking/.
Pay More Attention to the Robustness of Prompt for Instruction Data Mining
Mar 31, 2025Instruction tuning has emerged as a paramount method for tailoring the behaviors of LLMs. Recent work has unveiled the potential for LLMs to achieve high performance through fine-tuning with a limited quantity of high-quality instruction data. Building upon this approach, we further explore the impact of prompt's robustness on the selection of high-quality instruction data. This paper proposes a pioneering framework of high-quality online instruction data mining for instruction tuning, focusing on the impact of prompt's robustness on the data mining process. Our notable innovation, is to generate the adversarial instruction data by conducting the attack for the prompt of online instruction data. Then, we introduce an Adversarial Instruction-Following Difficulty metric to measure how much help the adversarial instruction data can provide to the generation of the corresponding response. Apart from it, we propose a novel Adversarial Instruction Output Embedding Consistency approach to select high-quality online instruction data. We conduct extensive experiments on two benchmark datasets to assess the performance. The experimental results serve to underscore the effectiveness of our proposed two methods. Moreover, the results underscore the critical practical significance of considering prompt's robustness.
Learn by Reasoning: Analogical Weight Generation for Few-Shot Class-Incremental Learning
Mar 27, 2025Few-shot class-incremental Learning (FSCIL) enables models to learn new classes from limited data while retaining performance on previously learned classes. Traditional FSCIL methods often require fine-tuning parameters with limited new class data and suffer from a separation between learning new classes and utilizing old knowledge. Inspired by the analogical learning mechanisms of the human brain, we propose a novel analogical generative method. Our approach includes the Brain-Inspired Analogical Generator (BiAG), which derives new class weights from existing classes without parameter fine-tuning during incremental stages. BiAG consists of three components: Weight Self-Attention Module (WSA), Weight & Prototype Analogical Attention Module (WPAA), and Semantic Conversion Module (SCM). SCM uses Neural Collapse theory for semantic conversion, WSA supplements new class weights, and WPAA computes analogies to generate new class weights. Experiments on miniImageNet, CUB-200, and CIFAR-100 datasets demonstrate that our method achieves higher final and average accuracy compared to SOTA methods.
Space Rotation with Basis Transformation for Training-free Test-Time Adaptation
Feb 27, 2025With the development of visual-language models (VLM) in downstream task applications, test-time adaptation methods based on VLM have attracted increasing attention for their ability to address changes distribution in test-time. Although prior approaches have achieved some progress, they typically either demand substantial computational resources or are constrained by the limitations of the original feature space, rendering them less effective for test-time adaptation tasks. To address these challenges, we propose a training-free feature space rotation with basis transformation for test-time adaptation. By leveraging the inherent distinctions among classes, we reconstruct the original feature space and map it to a new representation, thereby enhancing the clarity of class differences and providing more effective guidance for the model during testing. Additionally, to better capture relevant information from various classes, we maintain a dynamic queue to store representative samples. Experimental results across multiple benchmarks demonstrate that our method outperforms state-of-the-art techniques in terms of both performance and efficiency.
FantasyID: Face Knowledge Enhanced ID-Preserving Video Generation
Feb 19, 2025



Tuning-free approaches adapting large-scale pre-trained video diffusion models for identity-preserving text-to-video generation (IPT2V) have gained popularity recently due to their efficacy and scalability. However, significant challenges remain to achieve satisfied facial dynamics while keeping the identity unchanged. In this work, we present a novel tuning-free IPT2V framework by enhancing face knowledge of the pre-trained video model built on diffusion transformers (DiT), dubbed FantasyID. Essentially, 3D facial geometry prior is incorporated to ensure plausible facial structures during video synthesis. To prevent the model from learning copy-paste shortcuts that simply replicate reference face across frames, a multi-view face augmentation strategy is devised to capture diverse 2D facial appearance features, hence increasing the dynamics over the facial expressions and head poses. Additionally, after blending the 2D and 3D features as guidance, instead of naively employing cross-attention to inject guidance cues into DiT layers, a learnable layer-aware adaptive mechanism is employed to selectively inject the fused features into each individual DiT layers, facilitating balanced modeling of identity preservation and motion dynamics. Experimental results validate our model's superiority over the current tuning-free IPT2V methods.
SphereFusion: Efficient Panorama Depth Estimation via Gated Fusion
Feb 09, 2025Due to the rapid development of panorama cameras, the task of estimating panorama depth has attracted significant attention from the computer vision community, especially in applications such as robot sensing and autonomous driving. However, existing methods relying on different projection formats often encounter challenges, either struggling with distortion and discontinuity in the case of equirectangular, cubemap, and tangent projections, or experiencing a loss of texture details with the spherical projection. To tackle these concerns, we present SphereFusion, an end-to-end framework that combines the strengths of various projection methods. Specifically, SphereFusion initially employs 2D image convolution and mesh operations to extract two distinct types of features from the panorama image in both equirectangular and spherical projection domains. These features are then projected onto the spherical domain, where a gate fusion module selects the most reliable features for fusion. Finally, SphereFusion estimates panorama depth within the spherical domain. Meanwhile, SphereFusion employs a cache strategy to improve the efficiency of mesh operation. Extensive experiments on three public panorama datasets demonstrate that SphereFusion achieves competitive results with other state-of-the-art methods, while presenting the fastest inference speed at only 17 ms on a 512$\times$1024 panorama image.
CPRM: A LLM-based Continual Pre-training Framework for Relevance Modeling in Commercial Search
Dec 03, 2024



Relevance modeling between queries and items stands as a pivotal component in commercial search engines, directly affecting the user experience. Given the remarkable achievements of large language models (LLMs) in various natural language processing (NLP) tasks, LLM-based relevance modeling is gradually being adopted within industrial search systems. Nevertheless, foundational LLMs lack domain-specific knowledge and do not fully exploit the potential of in-context learning. Furthermore, structured item text remains underutilized, and there is a shortage in the supply of corresponding queries and background knowledge. We thereby propose CPRM (Continual Pre-training for Relevance Modeling), a framework designed for the continual pre-training of LLMs to address these issues. Our CPRM framework includes three modules: 1) employing both queries and multi-field item to jointly pre-train for enhancing domain knowledge, 2) applying in-context pre-training, a novel approach where LLMs are pre-trained on a sequence of related queries or items, and 3) conducting reading comprehension on items to produce associated domain knowledge and background information (e.g., generating summaries and corresponding queries) to further strengthen LLMs. Results on offline experiments and online A/B testing demonstrate that our model achieves convincing performance compared to strong baselines.