 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Causal Framework for Mitigating Data Shifts in Healthcare
Mar 13, 2026Developing predictive models that perform reliably across diverse patient populations and heterogeneous environments is a core aim of medical research. However, generalization is only possible if the learned model is robust to statistical differences between data used for training and data seen at the time and place of deployment. Domain generalization methods provide strategies to address data shifts, but each method comes with its own set of assumptions and trade-offs. To apply these methods in healthcare, we must understand how domain shifts arise, what assumptions we prefer to make, and what our design constraints are. This article proposes a causal framework for the design of predictive models to improve generalization. Causality provides a powerful language to characterize and understand diverse domain shifts, regardless of data modality. This allows us to pinpoint why models fail to generalize, leading to more principled strategies to prepare for and adapt to shifts. We recommend general mitigation strategies, discussing trade-offs and highlighting existing work. Our causality-based perspective offers a critical foundation for developing robust, interpretable, and clinically relevant AI solutions in healthcare, paving the way for reliable real-world deployment.
Segment Anyword: Mask Prompt Inversion for Open-Set Grounded Segmentation
May 23, 2025Open-set image segmentation poses a significant challenge because existing methods often demand extensive training or fine-tuning and generally struggle to segment unified objects consistently across diverse text reference expressions. Motivated by this, we propose Segment Anyword, a novel training-free visual concept prompt learning approach for open-set language grounded segmentation that relies on token-level cross-attention maps from a frozen diffusion model to produce segmentation surrogates or mask prompts, which are then refined into targeted object masks. Initial prompts typically lack coherence and consistency as the complexity of the image-text increases, resulting in suboptimal mask fragments. To tackle this issue, we further introduce a novel linguistic-guided visual prompt regularization that binds and clusters visual prompts based on sentence dependency and syntactic structural information, enabling the extraction of robust, noise-tolerant mask prompts, and significant improvements in segmentation accuracy. The proposed approach is effective, generalizes across different open-set segmentation tasks, and achieves state-of-the-art results of 52.5 (+6.8 relative) mIoU on Pascal Context 59, 67.73 (+25.73 relative) cIoU on gRefCOCO, and 67.4 (+1.1 relative to fine-tuned methods) mIoU on GranDf, which is the most complex open-set grounded segmentation task in the field.
BOTM: Echocardiography Segmentation via Bi-directional Optimal Token Matching
May 23, 2025Existed echocardiography segmentation methods often suffer from anatomical inconsistency challenge caused by shape variation, partial observation and region ambiguity with similar intensity across 2D echocardiographic sequences, resulting in false positive segmentation with anatomical defeated structures in challenging low signal-to-noise ratio conditions. To provide a strong anatomical guarantee across different echocardiographic frames, we propose a novel segmentation framework named BOTM (Bi-directional Optimal Token Matching) that performs echocardiography segmentation and optimal anatomy transportation simultaneously. Given paired echocardiographic images, BOTM learns to match two sets of discrete image tokens by finding optimal correspondences from a novel anatomical transportation perspective. We further extend the token matching into a bi-directional cross-transport attention proxy to regulate the preserved anatomical consistency within the cardiac cyclic deformation in temporal domain. Extensive experimental results show that BOTM can generate stable and accurate segmentation outcomes (e.g. -1.917 HD on CAMUS2H LV, +1.9% Dice on TED), and provide a better matching interpretation with anatomical consistency guarantee.
High Resolution Tree Height Mapping of the Amazon Forest using Planet NICFI Images and LiDAR-Informed U-Net Model
Jan 17, 2025



Tree canopy height is one of the most important indicators of forest biomass, productivity, and ecosystem structure, but it is challenging to measure accurately from the ground and from space. Here, we used a U-Net model adapted for regression to map the mean tree canopy height in the Amazon forest from Planet NICFI images at ~4.78 m spatial resolution for the period 2020-2024. The U-Net model was trained using canopy height models computed from aerial LiDAR data as a reference, along with their corresponding Planet NICFI images. Predictions of tree heights on the validation sample exhibited a mean error of 3.68 m and showed relatively low systematic bias across the entire range of tree heights present in the Amazon forest. Our model successfully estimated canopy heights up to 40-50 m without much saturation, outperforming existing canopy height products from global models in this region. We determined that the Amazon forest has an average canopy height of ~22 m. Events such as logging or deforestation could be detected from changes in tree height, and encouraging results were obtained to monitor the height of regenerating forests. These findings demonstrate the potential for large-scale mapping and monitoring of tree height for old and regenerating Amazon forests using Planet NICFI imagery.
DOR3D-Net: Dense Ordinal Regression Network for 3D Hand Pose Estimation
Mar 20, 2024



Depth-based 3D hand pose estimation is an important but challenging research task in human-machine interaction community. Recently, dense regression methods have attracted increasing attention in 3D hand pose estimation task, which provide a low computational burden and high accuracy regression way by densely regressing hand joint offset maps. However, large-scale regression offset values are often affected by noise and outliers, leading to a significant drop in accuracy. To tackle this, we re-formulate 3D hand pose estimation as a dense ordinal regression problem and propose a novel Dense Ordinal Regression 3D Pose Network (DOR3D-Net). Specifically, we first decompose offset value regression into sub-tasks of binary classifications with ordinal constraints. Then, each binary classifier can predict the probability of a binary spatial relationship relative to joint, which is easier to train and yield much lower level of noise. The estimated hand joint positions are inferred by aggregating the ordinal regression results at local positions with a weighted sum. Furthermore, both joint regression loss and ordinal regression loss are used to train our DOR3D-Net in an end-to-end manner. Extensive experiments on public datasets (ICVL, MSRA, NYU and HANDS2017) show that our design provides significant improvements over SOTA methods.
DVI-SLAM: A Dual Visual Inertial SLAM Network
Sep 25, 2023



Recent deep learning based visual simultaneous localization and mapping (SLAM) methods have made significant progress. However, how to make full use of visual information as well as better integrate with inertial measurement unit (IMU) in visual SLAM has potential research value. This paper proposes a novel deep SLAM network with dual visual factors. The basic idea is to integrate both photometric factor and re-projection factor into the end-to-end differentiable structure through multi-factor data association module. We show that the proposed network dynamically learns and adjusts the confidence maps of both visual factors and it can be further extended to include the IMU factors as well. Extensive experiments validate that our proposed method significantly outperforms the state-of-the-art methods on several public datasets, including TartanAir, EuRoC and ETH3D-SLAM. Specifically, when dynamically fusing the three factors together, the absolute trajectory error for both monocular and stereo configurations on EuRoC dataset has reduced by 45.3% and 36.2% respectively.
Medical Image Analysis using Deep Relational Learning
Mar 28, 2023



In the past ten years, with the help of deep learning, especially the rapid development of deep neural networks, medical image analysis has made remarkable progress. However, how to effectively use the relational information between various tissues or organs in medical images is still a very challenging problem, and it has not been fully studied. In this thesis, we propose two novel solutions to this problem based on deep relational learning. First, we propose a context-aware fully convolutional network that effectively models implicit relation information between features to perform medical image segmentation. The network achieves the state-of-the-art segmentation results on the Multi Modal Brain Tumor Segmentation 2017 (BraTS2017) and Multi Modal Brain Tumor Segmentation 2018 (BraTS2018) data sets. Subsequently, we propose a new hierarchical homography estimation network to achieve accurate medical image mosaicing by learning the explicit spatial relationship between adjacent frames. We use the UCL Fetoscopy Placenta dataset to conduct experiments and our hierarchical homography estimation network outperforms the other state-of-the-art mosaicing methods while generating robust and meaningful mosaicing result on unseen frames.
LSDM: Long-Short Diffeomorphic Motion for Weakly-Supervised Ultrasound Landmark Tracking
Jan 11, 2023Accurate tracking of an anatomical landmark over time has been of high interests for disease assessment such as minimally invasive surgery and tumor radiation therapy. Ultrasound imaging is a promising modality benefiting from low-cost and real-time acquisition. However, generating a precise landmark tracklet is very challenging, as attempts can be easily distorted by different interference such as landmark deformation, visual ambiguity and partial observation. In this paper, we propose a long-short diffeomorphic motion network, which is a multi-task framework with a learnable deformation prior to search for the plausible deformation of landmark. Specifically, we design a novel diffeomorphism representation in both long and short temporal domains for delineating motion margins and reducing long-term cumulative tracking errors. To further mitigate local anatomical ambiguity, we propose an expectation maximisation motion alignment module to iteratively optimize both long and short deformation, aligning to the same directional and spatial representation. The proposed multi-task system can be trained in a weakly-supervised manner, which only requires few landmark annotations for tracking and zero annotation for long-short deformation learning. We conduct extensive experiments on two ultrasound landmark tracking datasets. Experimental results show that our proposed method can achieve better or competitive landmark tracking performance compared with other state-of-the-art tracking methods, with a strong generalization capability across different scanner types and different ultrasound modalities.
Thinking Clearly, Talking Fast: Concept-Guided Non-Autoregressive Generation for Open-Domain Dialogue Systems
Sep 09, 2021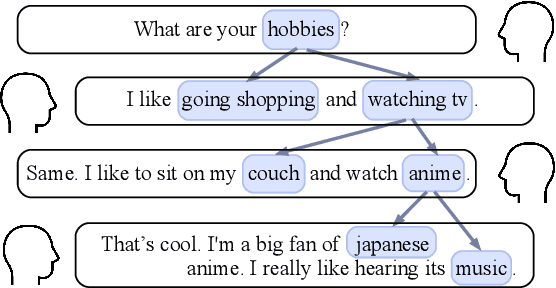
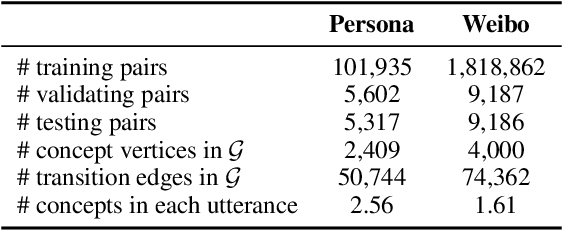
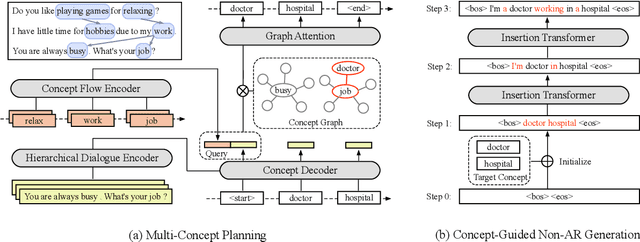
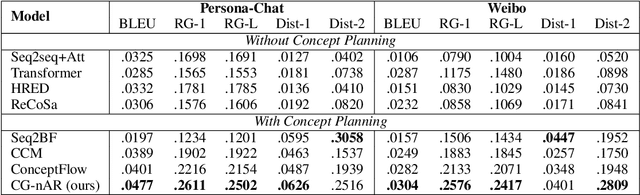
Human dialogue contains evolving concepts, and speakers naturally associate multiple concepts to compose a response. However, current dialogue models with the seq2seq framework lack the ability to effectively manage concept transitions and can hardly introduce multiple concepts to responses in a sequential decoding manner. To facilitate a controllable and coherent dialogue, in this work, we devise a concept-guided non-autoregressive model (CG-nAR) for open-domain dialogue generation. The proposed model comprises a multi-concept planning module that learns to identify multiple associated concepts from a concept graph and a customized Insertion Transformer that performs concept-guided non-autoregressive generation to complete a response. The experimental results on two public datasets show that CG-nAR can produce diverse and coherent responses, outperforming state-of-the-art baselines in both automatic and human evaluations with substantially faster inference speed.
TextFlint: Unified Multilingual Robustness Evaluation Toolkit for Natural Language Processing
Apr 06, 2021



Various robustness evaluation methodologies from different perspectives have been proposed for different natural language processing (NLP) tasks. These methods have often focused on either universal or task-specific generalization capabilities. In this work, we propose a multilingual robustness evaluation platform for NLP tasks (TextFlint) that incorporates universal text transformation, task-specific transformation, adversarial attack, subpopulation, and their combinations to provide comprehensive robustness analysis. TextFlint enables practitioners to automatically evaluate their models from all aspects or to customize their evaluations as desired with just a few lines of code. To guarantee user acceptability, all the text transformations are linguistically based, and we provide a human evaluation for each one. TextFlint generates complete analytical reports as well as targeted augmented data to address the shortcomings of the model's robustness. To validate TextFlint's utility, we performed large-scale empirical evaluations (over 67,000 evaluations) on state-of-the-art deep learning models, classic supervised methods, and real-world systems. Almost all models showed significant performance degradation, including a decline of more than 50% of BERT's prediction accuracy on tasks such as aspect-level sentiment classification, named entity recognition, and natural language inference. Therefore, we call for the robustness to be included in the model evaluation, so as to promote the healthy development of NLP technology.