 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing In-Context Learning for Automatic Defect Labelling of Display Manufacturing Data
Jun 05, 2025This paper presents an AI-assisted auto-labeling system for display panel defect detection that leverages in-context learning capabilities. We adopt and enhance the SegGPT architecture with several domain-specific training techniques and introduce a scribble-based annotation mechanism to streamline the labeling process. Our two-stage training approach, validated on industrial display panel datasets, demonstrates significant improvements over the baseline model, achieving an average IoU increase of 0.22 and a 14% improvement in recall across multiple product types, while maintaining approximately 60% auto-labeling coverage. Experimental results show that models trained on our auto-labeled data match the performance of those trained on human-labeled data, offering a practical solution for reducing manual annotation efforts in industrial inspection systems.
PDE-Transformer: Efficient and Versatile Transformers for Physics Simulations
May 30, 2025



We introduce PDE-Transformer, an improved transformer-based architecture for surrogate modeling of physics simulations on regular grids. We combine recent architectural improvements of diffusion transformers with adjustments specific for large-scale simulations to yield a more scalable and versatile general-purpose transformer architecture, which can be used as the backbone for building large-scale foundation models in physical sciences. We demonstrate that our proposed architecture outperforms state-of-the-art transformer architectures for computer vision on a large dataset of 16 different types of PDEs. We propose to embed different physical channels individually as spatio-temporal tokens, which interact via channel-wise self-attention. This helps to maintain a consistent information density of tokens when learning multiple types of PDEs simultaneously. We demonstrate that our pre-trained models achieve improved performance on several challenging downstream tasks compared to training from scratch and also beat other foundation model architectures for physics simulations.
Divide-Then-Align: Honest Alignment based on the Knowledge Boundary of RAG
May 27, 2025



Large language models (LLMs) augmented with retrieval systems have significantly advanced natural language processing tasks by integrating external knowledge sources, enabling more accurate and contextually rich responses. To improve the robustness of such systems against noisy retrievals, Retrieval-Augmented Fine-Tuning (RAFT) has emerged as a widely adopted method. However, RAFT conditions models to generate answers even in the absence of reliable knowledge. This behavior undermines their reliability in high-stakes domains, where acknowledging uncertainty is critical. To address this issue, we propose Divide-Then-Align (DTA), a post-training approach designed to endow RAG systems with the ability to respond with "I don't know" when the query is out of the knowledge boundary of both the retrieved passages and the model's internal knowledge. DTA divides data samples into four knowledge quadrants and constructs tailored preference data for each quadrant, resulting in a curated dataset for Direct Preference Optimization (DPO). Experimental results on three benchmark datasets demonstrate that DTA effectively balances accuracy with appropriate abstention, enhancing the reliability and trustworthiness of retrieval-augmented systems.
REACT: Representation Extraction And Controllable Tuning to Overcome Overfitting in LLM Knowledge Editing
May 25, 2025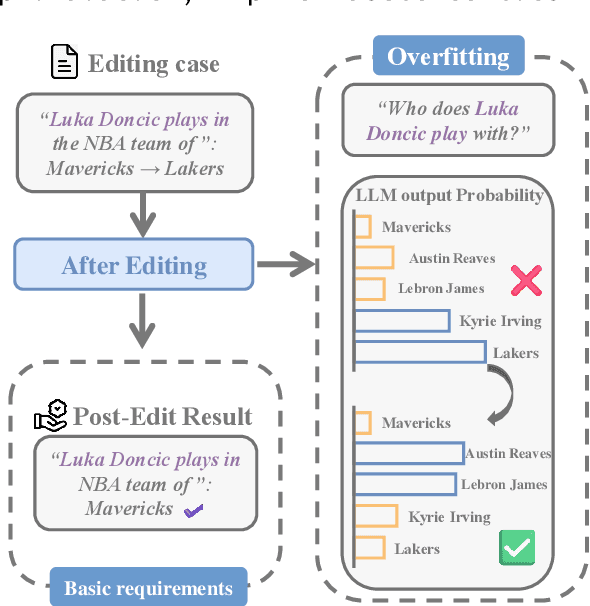
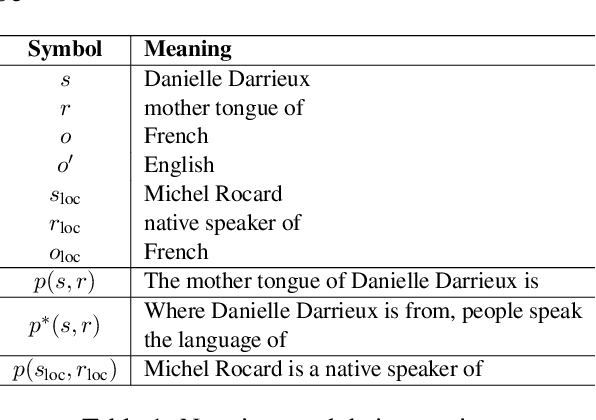
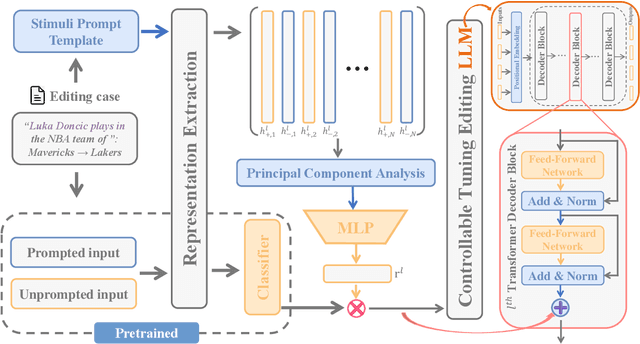
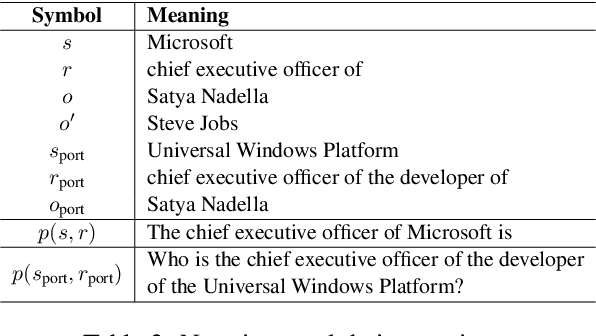
Large language model editing methods frequently suffer from overfitting, wherein factual updates can propagate beyond their intended scope, overemphasizing the edited target even when it's contextually inappropriate. To address this challenge, we introduce REACT (Representation Extraction And Controllable Tuning), a unified two-phase framework designed for precise and controllable knowledge editing. In the initial phase, we utilize tailored stimuli to extract latent factual representations and apply Principal Component Analysis with a simple learnbale linear transformation to compute a directional "belief shift" vector for each instance. In the second phase, we apply controllable perturbations to hidden states using the obtained vector with a magnitude scalar, gated by a pre-trained classifier that permits edits only when contextually necessary. Relevant experiments on EVOKE benchmarks demonstrate that REACT significantly reduces overfitting across nearly all evaluation metrics, and experiments on COUNTERFACT and MQuAKE shows that our method preserves balanced basic editing performance (reliability, locality, and generality) under diverse editing scenarios.
Disentangling Knowledge Representations for Large Language Model Editing
May 24, 2025Knowledge Editing has emerged as a promising solution for efficiently updating embedded knowledge in large language models (LLMs). While existing approaches demonstrate effectiveness in integrating new knowledge and preserving the original capabilities of LLMs, they fail to maintain fine-grained irrelevant knowledge facts that share the same subject as edited knowledge but differ in relation and object. This challenge arises because subject representations inherently encode multiple attributes, causing the target and fine-grained irrelevant knowledge to become entangled in the representation space, and thus vulnerable to unintended alterations during editing. To address this, we propose DiKE, a novel approach that Disentangles Knowledge representations for LLM Editing (DiKE). DiKE consists of two key components: a Knowledge Representation Disentanglement (KRD) module that decomposes the subject representation into target-knowledgerelated and -unrelated components, and a Disentanglement-based Knowledge Edit (DKE) module that updates only the target-related component while explicitly preserving the unrelated one. We further derive a closed-form, rank-one parameter update based on matrix theory to enable efficient and minimally invasive edits. To rigorously evaluate fine-grained irrelevant knowledge preservation, we construct FINE-KED, a new benchmark comprising fine-grained irrelevant knowledge at different levels of relational similarity to the edited knowledge. Extensive experiments across multiple LLMs demonstrate that DiKE substantially improves fine-grained irrelevant knowledge preservation while maintaining competitive general editing performance.
Materials Generation in the Era of Artificial Intelligence: A Comprehensive Survey
May 22, 2025



Materials are the foundation of modern society, underpinning advancements in energy, electronics, healthcare, transportation, and infrastructure. The ability to discover and design new materials with tailored properties is critical to solving some of the most pressing global challenges. In recent years, the growing availability of high-quality materials data combined with rapid advances in Artificial Intelligence (AI) has opened new opportunities for accelerating materials discovery. Data-driven generative models provide a powerful tool for materials design by directly create novel materials that satisfy predefined property requirements. Despite the proliferation of related work, there remains a notable lack of up-to-date and systematic surveys in this area. To fill this gap, this paper provides a comprehensive overview of recent progress in AI-driven materials generation. We first organize various types of materials and illustrate multiple representations of crystalline materials. We then provide a detailed summary and taxonomy of current AI-driven materials generation approaches. Furthermore, we discuss the common evaluation metrics and summarize open-source codes and benchmark datasets. Finally, we conclude with potential future directions and challenges in this fast-growing field. The related sources can be found at https://github.com/ZhixunLEE/Awesome-AI-for-Materials-Generation.
PoisonArena: Uncovering Competing Poisoning Attacks in Retrieval-Augmented Generation
May 18, 2025



Retrieval-Augmented Generation (RAG) systems, widely used to improve the factual grounding of large language models (LLMs), are increasingly vulnerable to poisoning attacks, where adversaries inject manipulated content into the retriever's corpus. While prior research has predominantly focused on single-attacker settings, real-world scenarios often involve multiple, competing attackers with conflicting objectives. In this work, we introduce PoisonArena, the first benchmark to systematically study and evaluate competing poisoning attacks in RAG. We formalize the multi-attacker threat model, where attackers vie to control the answer to the same query using mutually exclusive misinformation. PoisonArena leverages the Bradley-Terry model to quantify each method's competitive effectiveness in such adversarial environments. Through extensive experiments on the Natural Questions and MS MARCO datasets, we demonstrate that many attack strategies successful in isolation fail under competitive pressure. Our findings highlight the limitations of conventional evaluation metrics like Attack Success Rate (ASR) and F1 score and underscore the need for competitive evaluation to assess real-world attack robustness. PoisonArena provides a standardized framework to benchmark and develop future attack and defense strategies under more realistic, multi-adversary conditions. Project page: https://github.com/yxf203/PoisonArena.
Fair-PP: A Synthetic Dataset for Aligning LLM with Personalized Preferences of Social Equity
May 17, 2025Human preference plays a crucial role in the refinement of large language models (LLMs). However, collecting human preference feedback is costly and most existing datasets neglect the correlation between personalization and preferences. To address this issue, we introduce Fair-PP, a synthetic dataset of personalized preferences targeting social equity, derived from real-world social survey data, which includes 28 social groups, 98 equity topics, and 5 personal preference dimensions. Leveraging GPT-4o-mini, we engage in role-playing based on seven representative persona portrayals guided by existing social survey data, yielding a total of 238,623 preference records. Through Fair-PP, we also contribute (i) An automated framework for generating preference data, along with a more fine-grained dataset of personalized preferences; (ii) analysis of the positioning of the existing mainstream LLMs across five major global regions within the personalized preference space; and (iii) a sample reweighting method for personalized preference alignment, enabling alignment with a target persona while maximizing the divergence from other personas. Empirical experiments show our method outperforms the baselines.
Steepest Descent Density Control for Compact 3D Gaussian Splatting
May 08, 20253D Gaussian Splatting (3DGS) has emerged as a powerful technique for real-time, high-resolution novel view synthesis. By representing scenes as a mixture of Gaussian primitives, 3DGS leverages GPU rasterization pipelines for efficient rendering and reconstruction. To optimize scene coverage and capture fine details, 3DGS employs a densification algorithm to generate additional points. However, this process often leads to redundant point clouds, resulting in excessive memory usage, slower performance, and substantial storage demands - posing significant challenges for deployment on resource-constrained devices. To address this limitation, we propose a theoretical framework that demystifies and improves density control in 3DGS. Our analysis reveals that splitting is crucial for escaping saddle points. Through an optimization-theoretic approach, we establish the necessary conditions for densification, determine the minimal number of offspring Gaussians, identify the optimal parameter update direction, and provide an analytical solution for normalizing off-spring opacity. Building on these insights, we introduce SteepGS, incorporating steepest density control, a principled strategy that minimizes loss while maintaining a compact point cloud. SteepGS achieves a ~50% reduction in Gaussian points without compromising rendering quality, significantly enhancing both efficiency and scalability.
Graffe: Graph Representation Learning via Diffusion Probabilistic Models
May 08, 2025Diffusion probabilistic models (DPMs), widely recognized for their potential to generate high-quality samples, tend to go unnoticed in representation learning. While recent progress has highlighted their potential for capturing visual semantics, adapting DPMs to graph representation learning remains in its infancy. In this paper, we introduce Graffe, a self-supervised diffusion model proposed for graph representation learning. It features a graph encoder that distills a source graph into a compact representation, which, in turn, serves as the condition to guide the denoising process of the diffusion decoder. To evaluate the effectiveness of our model, we first explore the theoretical foundations of applying diffusion models to representation learning, proving that the denoising objective implicitly maximizes the conditional mutual information between data and its representation. Specifically, we prove that the negative logarithm of the denoising score matching loss is a tractable lower bound for the conditional mutual information. Empirically, we conduct a series of case studies to validate our theoretical insights. In addition, Graffe delivers competitive results under the linear probing setting on node and graph classification tasks, achieving state-of-the-art performance on 9 of the 11 real-world datasets. These findings indicate that powerful generative models, especially diffusion models, serve as an effective tool for graph representation learning.