 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurriculum Learning for ab initio Deep Learned Refractive Optics
Feb 09, 2023Deep lens optimization has recently emerged as a new paradigm for designing computational imaging systems, however it has been limited to either simple optical systems consisting of a single DOE or metalens, or the fine-tuning of compound lenses from good initial designs. Here we present a deep lens design method based on curriculum learning, which is able to learn optical designs of compound lenses ab initio from randomly initialized surfaces, therefore overcoming the need for a good initial design. We demonstrate this approach with the fully-automatic design of an extended depth-of-field computational camera in a cellphone-style form factor, highly aspherical surfaces, and a short back focal length.
Joint Acoustic Echo Cancellation and Speech Dereverberation Using Kalman filters
Feb 09, 2023



This paper proposes a joint acoustic echo cancellation (AEC) and speech dereverberation (DR) algorithm in the short-time Fourier transform domain. The reverberant microphone signals are described using an auto-regressive (AR) model. The AR coefficients and the loudspeaker-to-microphone acoustic transfer functions (ATFs) are considered time-varying and are modeled simultaneously using a first-order Markov process. This leads to a solution where these parameters can be optimally estimated using Kalman filters. It is shown that the proposed algorithm outperforms vanilla solutions that solve AEC and DR sequentially and one state-of-the-art joint DRAEC algorithm based on semi-blind source separation, in terms of both speech quality and echo reduction performance.
Sample Dropout: A Simple yet Effective Variance Reduction Technique in Deep Policy Optimization
Feb 05, 2023Recent success in Deep Reinforcement Learning (DRL) methods has shown that policy optimization with respect to an off-policy distribution via importance sampling is effective for sample reuse. In this paper, we show that the use of importance sampling could introduce high variance in the objective estimate. Specifically, we show in a principled way that the variance of importance sampling estimate grows quadratically with importance ratios and the large ratios could consequently jeopardize the effectiveness of surrogate objective optimization. We then propose a technique called sample dropout to bound the estimation variance by dropping out samples when their ratio deviation is too high. We instantiate this sample dropout technique on representative policy optimization algorithms, including TRPO, PPO, and ESPO, and demonstrate that it consistently boosts the performance of those DRL algorithms on both continuous and discrete action controls, including MuJoCo, DMControl and Atari video games. Our code is open-sourced at \url{https://github.com/LinZichuan/sdpo.git}.
Revisiting Estimation Bias in Policy Gradients for Deep Reinforcement Learning
Jan 20, 2023We revisit the estimation bias in policy gradients for the discounted episodic Markov decision process (MDP) from Deep Reinforcement Learning (DRL) perspective. The objective is formulated theoretically as the expected returns discounted over the time horizon. One of the major policy gradient biases is the state distribution shift: the state distribution used to estimate the gradients differs from the theoretical formulation in that it does not take into account the discount factor. Existing discussion of the influence of this bias was limited to the tabular and softmax cases in the literature. Therefore, in this paper, we extend it to the DRL setting where the policy is parameterized and demonstrate how this bias can lead to suboptimal policies theoretically. We then discuss why the empirically inaccurate implementations with shifted state distribution can still be effective. We show that, despite such state distribution shift, the policy gradient estimation bias can be reduced in the following three ways: 1) a small learning rate; 2) an adaptive-learning-rate-based optimizer; and 3) KL regularization. Specifically, we show that a smaller learning rate, or, an adaptive learning rate, such as that used by Adam and RSMProp optimizers, makes the policy optimization robust to the bias. We further draw connections between optimizers and the optimization regularization to show that both the KL and the reverse KL regularization can significantly rectify this bias. Moreover, we provide extensive experiments on continuous control tasks to support our analysis. Our paper sheds light on how successful PG algorithms optimize policies in the DRL setting, and contributes insights into the practical issues in DRL.
RLogist: Fast Observation Strategy on Whole-slide Images with Deep Reinforcement Learning
Dec 13, 2022Whole-slide images (WSI) in computational pathology have high resolution with gigapixel size, but are generally with sparse regions of interest, which leads to weak diagnostic relevance and data inefficiency for each area in the slide. Most of the existing methods rely on a multiple instance learning framework that requires densely sampling local patches at high magnification. The limitation is evident in the application stage as the heavy computation for extracting patch-level features is inevitable. In this paper, we develop RLogist, a benchmarking deep reinforcement learning (DRL) method for fast observation strategy on WSIs. Imitating the diagnostic logic of human pathologists, our RL agent learns how to find regions of observation value and obtain representative features across multiple resolution levels, without having to analyze each part of the WSI at the high magnification. We benchmark our method on two whole-slide level classification tasks, including detection of metastases in WSIs of lymph node sections, and subtyping of lung cancer. Experimental results demonstrate that RLogist achieves competitive classification performance compared to typical multiple instance learning algorithms, while having a significantly short observation path. In addition, the observation path given by RLogist provides good decision-making interpretability, and its ability of reading path navigation can potentially be used by pathologists for educational/assistive purposes. Our code is available at: \url{https://github.com/tencent-ailab/RLogist}.
DGI: Easy and Efficient Inference for GNNs
Nov 28, 2022While many systems have been developed to train Graph Neural Networks (GNNs), efficient model inference and evaluation remain to be addressed. For instance, using the widely adopted node-wise approach, model evaluation can account for up to 94% of the time in the end-to-end training process due to neighbor explosion, which means that a node accesses its multi-hop neighbors. On the other hand, layer-wise inference avoids the neighbor explosion problem by conducting inference layer by layer such that the nodes only need their one-hop neighbors in each layer. However, implementing layer-wise inference requires substantial engineering efforts because users need to manually decompose a GNN model into layers for computation and split workload into batches to fit into device memory. In this paper, we develop Deep Graph Inference (DGI) -- a system for easy and efficient GNN model inference, which automatically translates the training code of a GNN model for layer-wise execution. DGI is general for various GNN models and different kinds of inference requests, and supports out-of-core execution on large graphs that cannot fit in CPU memory. Experimental results show that DGI consistently outperforms layer-wise inference across different datasets and hardware settings, and the speedup can be over 1,000x.
Honor of Kings Arena: an Environment for Generalization in Competitive Reinforcement Learning
Oct 09, 2022
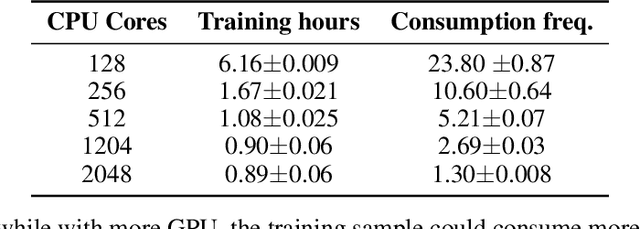

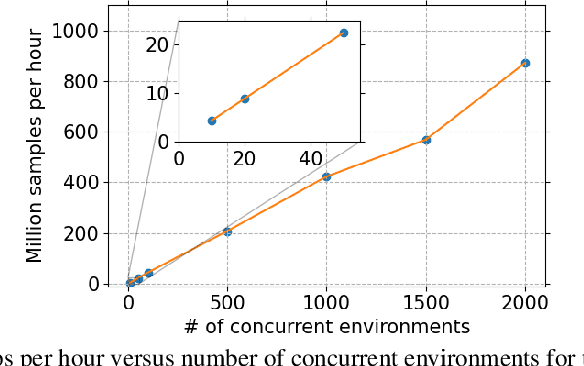
This paper introduces Honor of Kings Arena, a reinforcement learning (RL) environment based on Honor of Kings, one of the world's most popular games at present. Compared to other environments studied in most previous work, ours presents new generalization challenges for competitive reinforcement learning. It is a multi-agent problem with one agent competing against its opponent; and it requires the generalization ability as it has diverse targets to control and diverse opponents to compete with. We describe the observation, action, and reward specifications for the Honor of Kings domain and provide an open-source Python-based interface for communicating with the game engine. We provide twenty target heroes with a variety of tasks in Honor of Kings Arena and present initial baseline results for RL-based methods with feasible computing resources. Finally, we showcase the generalization challenges imposed by Honor of Kings Arena and possible remedies to the challenges. All of the software, including the environment-class, are publicly available at https://github.com/tencent-ailab/hok_env . The documentation is available at https://aiarena.tencent.com/hok/doc/ .
Revisiting Discrete Soft Actor-Critic
Sep 22, 2022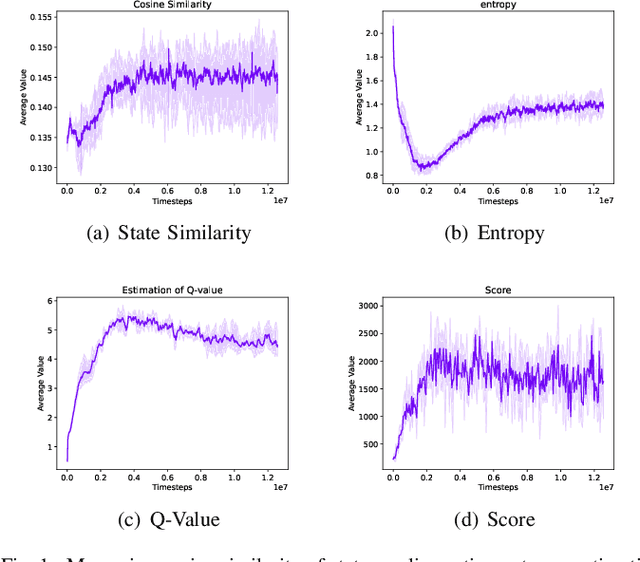
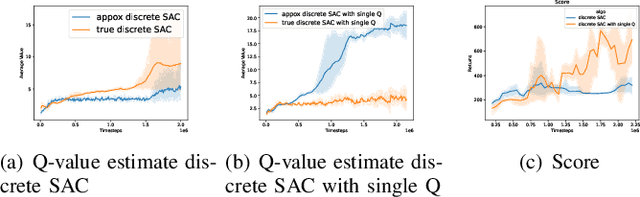
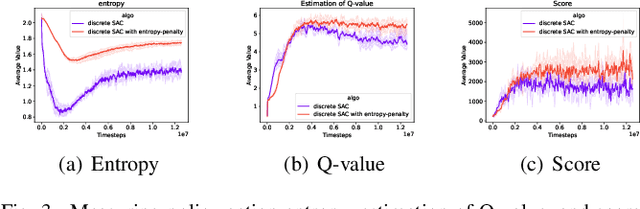
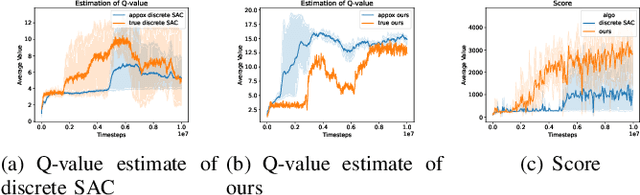
We study the adaption of soft actor-critic (SAC) from continuous action space to discrete action space. We revisit vanilla SAC and provide an in-depth understanding of its Q value underestimation and performance instability issues when applied to discrete settings. We thereby propose entropy-penalty and double average Q-learning with Q-clip to address these issues. Extensive experiments on typical benchmarks with discrete action space, including Atari games and a large-scale MOBA game, show the efficacy of our proposed method. Our code is at:https://github.com/coldsummerday/Revisiting-Discrete-SAC.
Make Heterophily Graphs Better Fit GNN: A Graph Rewiring Approach
Sep 17, 2022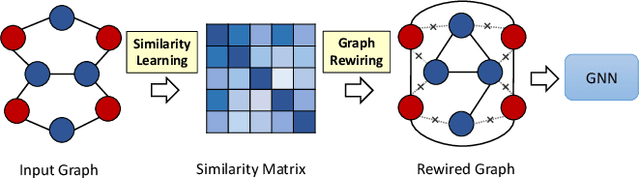

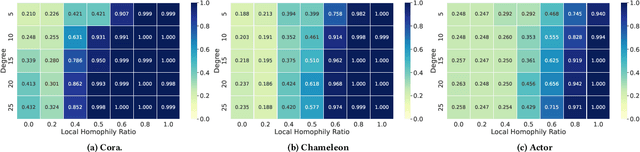
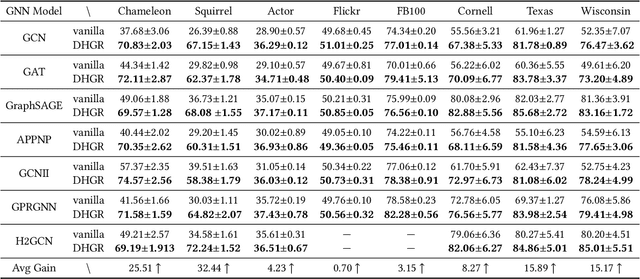
Graph Neural Networks (GNNs) are popular machine learning methods for modeling graph data. A lot of GNNs perform well on homophily graphs while having unsatisfactory performance on heterophily graphs. Recently, some researchers turn their attention to designing GNNs for heterophily graphs by adjusting the message passing mechanism or enlarging the receptive field of the message passing. Different from existing works that mitigate the issues of heterophily from model design perspective, we propose to study heterophily graphs from an orthogonal perspective by rewiring the graph structure to reduce heterophily and making the traditional GNNs perform better. Through comprehensive empirical studies and analysis, we verify the potential of the rewiring methods. To fully exploit its potential, we propose a method named Deep Heterophily Graph Rewiring (DHGR) to rewire graphs by adding homophilic edges and pruning heterophilic edges. The detailed way of rewiring is determined by comparing the similarity of label/feature-distribution of node neighbors. Besides, we design a scalable implementation for DHGR to guarantee high efficiency. DHRG can be easily used as a plug-in module, i.e., a graph pre-processing step, for any GNNs, including both GNN for homophily and heterophily, to boost their performance on the node classification task. To the best of our knowledge, it is the first work studying graph rewiring for heterophily graphs. Extensive experiments on 11 public graph datasets demonstrate the superiority of our proposed methods.
Learning Rate Perturbation: A Generic Plugin of Learning Rate Schedule towards Flatter Local Minima
Aug 25, 2022
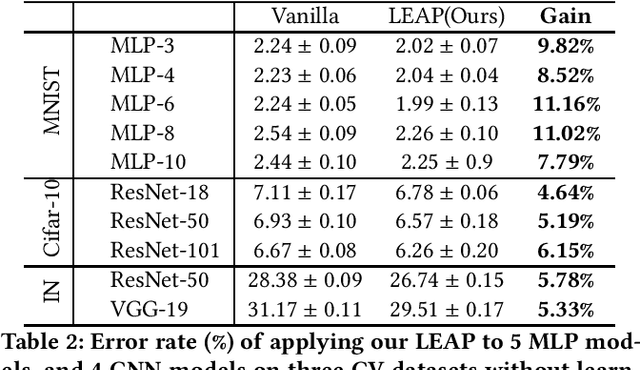
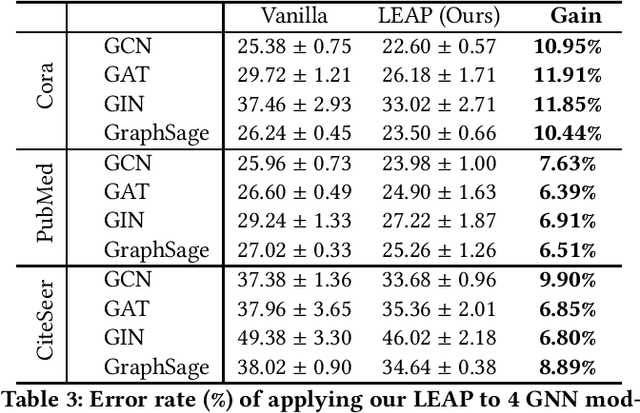
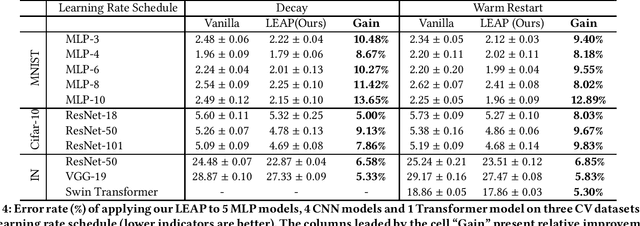
Learning rate is one of the most important hyper-parameters that has a significant influence on neural network training. Learning rate schedules are widely used in real practice to adjust the learning rate according to pre-defined schedules for fast convergence and good generalization. However, existing learning rate schedules are all heuristic algorithms and lack theoretical support. Therefore, people usually choose the learning rate schedules through multiple ad-hoc trials, and the obtained learning rate schedules are sub-optimal. To boost the performance of the obtained sub-optimal learning rate schedule, we propose a generic learning rate schedule plugin, called LEArning Rate Perturbation (LEAP), which can be applied to various learning rate schedules to improve the model training by introducing a certain perturbation to the learning rate. We found that, with such a simple yet effective strategy, training processing exponentially favors flat minima rather than sharp minima with guaranteed convergence, which leads to better generalization ability. In addition, we conduct extensive experiments which show that training with LEAP can improve the performance of various deep learning models on diverse datasets using various learning rate schedules (including constant learning rate).