 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYan: Foundational Interactive Video Generation
Aug 13, 2025We present Yan, a foundational framework for interactive video generation, covering the entire pipeline from simulation and generation to editing. Specifically, Yan comprises three core modules. AAA-level Simulation: We design a highly-compressed, low-latency 3D-VAE coupled with a KV-cache-based shift-window denoising inference process, achieving real-time 1080P/60FPS interactive simulation. Multi-Modal Generation: We introduce a hierarchical autoregressive caption method that injects game-specific knowledge into open-domain multi-modal video diffusion models (VDMs), then transforming the VDM into a frame-wise, action-controllable, real-time infinite interactive video generator. Notably, when the textual and visual prompts are sourced from different domains, the model demonstrates strong generalization, allowing it to blend and compose the style and mechanics across domains flexibly according to user prompts. Multi-Granularity Editing: We propose a hybrid model that explicitly disentangles interactive mechanics simulation from visual rendering, enabling multi-granularity video content editing during interaction through text. Collectively, Yan offers an integration of these modules, pushing interactive video generation beyond isolated capabilities toward a comprehensive AI-driven interactive creation paradigm, paving the way for the next generation of creative tools, media, and entertainment. The project page is: https://greatx3.github.io/Yan/.
Hokoff: Real Game Dataset from Honor of Kings and its Offline Reinforcement Learning Benchmarks
Aug 20, 2024



The advancement of Offline Reinforcement Learning (RL) and Offline Multi-Agent Reinforcement Learning (MARL) critically depends on the availability of high-quality, pre-collected offline datasets that represent real-world complexities and practical applications. However, existing datasets often fall short in their simplicity and lack of realism. To address this gap, we propose Hokoff, a comprehensive set of pre-collected datasets that covers both offline RL and offline MARL, accompanied by a robust framework, to facilitate further research. This data is derived from Honor of Kings, a recognized Multiplayer Online Battle Arena (MOBA) game known for its intricate nature, closely resembling real-life situations. Utilizing this framework, we benchmark a variety of offline RL and offline MARL algorithms. We also introduce a novel baseline algorithm tailored for the inherent hierarchical action space of the game. We reveal the incompetency of current offline RL approaches in handling task complexity, generalization and multi-task learning.
Honor of Kings Arena: an Environment for Generalization in Competitive Reinforcement Learning
Oct 09, 2022
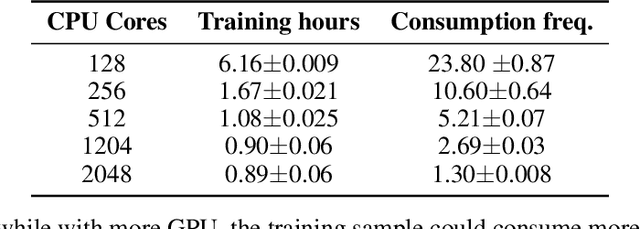

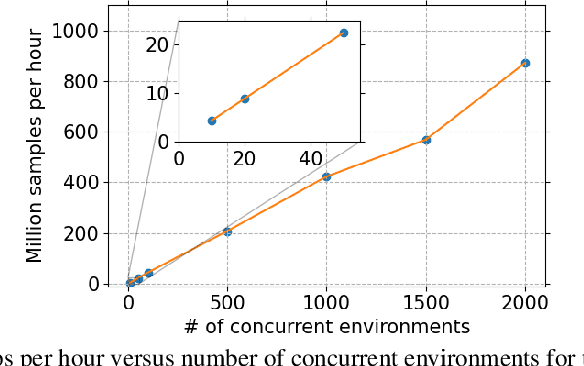
This paper introduces Honor of Kings Arena, a reinforcement learning (RL) environment based on Honor of Kings, one of the world's most popular games at present. Compared to other environments studied in most previous work, ours presents new generalization challenges for competitive reinforcement learning. It is a multi-agent problem with one agent competing against its opponent; and it requires the generalization ability as it has diverse targets to control and diverse opponents to compete with. We describe the observation, action, and reward specifications for the Honor of Kings domain and provide an open-source Python-based interface for communicating with the game engine. We provide twenty target heroes with a variety of tasks in Honor of Kings Arena and present initial baseline results for RL-based methods with feasible computing resources. Finally, we showcase the generalization challenges imposed by Honor of Kings Arena and possible remedies to the challenges. All of the software, including the environment-class, are publicly available at https://github.com/tencent-ailab/hok_env . The documentation is available at https://aiarena.tencent.com/hok/doc/ .