 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDF-GNN: Dynamic Fusion Framework for Attention Graph Neural Networks on GPUs
Nov 25, 2024



Attention Graph Neural Networks (AT-GNNs), such as GAT and Graph Transformer, have demonstrated superior performance compared to other GNNs. However, existing GNN systems struggle to efficiently train AT-GNNs on GPUs due to their intricate computation patterns. The execution of AT-GNN operations without kernel fusion results in heavy data movement and significant kernel launch overhead, while fixed thread scheduling in existing GNN kernel fusion strategies leads to sub-optimal performance, redundant computation and unbalanced workload. To address these challenges, we propose a dynamic kernel fusion framework, DF-GNN, for the AT-GNN family. DF-GNN introduces a dynamic bi-level thread scheduling strategy, enabling flexible adjustments to thread scheduling while retaining the benefits of shared memory within the fused kernel. DF-GNN tailors specific thread scheduling for operations in AT-GNNs and considers the performance bottleneck shift caused by the presence of super nodes. Additionally, DF-GNN is integrated with the PyTorch framework for high programmability. Evaluations across diverse GNN models and multiple datasets reveal that DF-GNN surpasses existing GNN kernel optimization works like cuGraph and dgNN, with speedups up to $7.0\times$ over the state-of-the-art non-fusion DGL sparse library. Moreover, it achieves an average speedup of $2.16\times$ in end-to-end training compared to the popular GNN computing framework DGL.
DiskGNN: Bridging I/O Efficiency and Model Accuracy for Out-of-Core GNN Training
May 08, 2024



Graph neural networks (GNNs) are machine learning models specialized for graph data and widely used in many applications. To train GNNs on large graphs that exceed CPU memory, several systems store data on disk and conduct out-of-core processing. However, these systems suffer from either read amplification when reading node features that are usually smaller than a disk page or degraded model accuracy by treating the graph as disconnected partitions. To close this gap, we build a system called DiskGNN, which achieves high I/O efficiency and thus fast training without hurting model accuracy. The key technique used by DiskGNN is offline sampling, which helps decouple graph sampling from model computation. In particular, by conducting graph sampling beforehand, DiskGNN acquires the node features that will be accessed by model computation, and such information is utilized to pack the target node features contiguously on disk to avoid read amplification. Besides, \name{} also adopts designs including four-level feature store to fully utilize the memory hierarchy to cache node features and reduce disk access, batched packing to accelerate the feature packing process, and pipelined training to overlap disk access with other operations. We compare DiskGNN with Ginex and MariusGNN, which are state-of-the-art systems for out-of-core GNN training. The results show that DiskGNN can speed up the baselines by over 8x while matching their best model accuracy.
4DBInfer: A 4D Benchmarking Toolbox for Graph-Centric Predictive Modeling on Relational DBs
Apr 28, 2024



Although RDBs store vast amounts of rich, informative data spread across interconnected tables, the progress of predictive machine learning models as applied to such tasks arguably falls well behind advances in other domains such as computer vision or natural language processing. This deficit stems, at least in part, from the lack of established/public RDB benchmarks as needed for training and evaluation purposes. As a result, related model development thus far often defaults to tabular approaches trained on ubiquitous single-table benchmarks, or on the relational side, graph-based alternatives such as GNNs applied to a completely different set of graph datasets devoid of tabular characteristics. To more precisely target RDBs lying at the nexus of these two complementary regimes, we explore a broad class of baseline models predicated on: (i) converting multi-table datasets into graphs using various strategies equipped with efficient subsampling, while preserving tabular characteristics; and (ii) trainable models with well-matched inductive biases that output predictions based on these input subgraphs. Then, to address the dearth of suitable public benchmarks and reduce siloed comparisons, we assemble a diverse collection of (i) large-scale RDB datasets and (ii) coincident predictive tasks. From a delivery standpoint, we operationalize the above four dimensions (4D) of exploration within a unified, scalable open-source toolbox called 4DBInfer. We conclude by presenting evaluations using 4DBInfer, the results of which highlight the importance of considering each such dimension in the design of RDB predictive models, as well as the limitations of more naive approaches such as simply joining adjacent tables. Our source code is released at https://github.com/awslabs/multi-table-benchmark .
MuseGNN: Interpretable and Convergent Graph Neural Network Layers at Scale
Oct 19, 2023



Among the many variants of graph neural network (GNN) architectures capable of modeling data with cross-instance relations, an important subclass involves layers designed such that the forward pass iteratively reduces a graph-regularized energy function of interest. In this way, node embeddings produced at the output layer dually serve as both predictive features for solving downstream tasks (e.g., node classification) and energy function minimizers that inherit desirable inductive biases and interpretability. However, scaling GNN architectures constructed in this way remains challenging, in part because the convergence of the forward pass may involve models with considerable depth. To tackle this limitation, we propose a sampling-based energy function and scalable GNN layers that iteratively reduce it, guided by convergence guarantees in certain settings. We also instantiate a full GNN architecture based on these designs, and the model achieves competitive accuracy and scalability when applied to the largest publicly-available node classification benchmark exceeding 1TB in size.
DGI: Easy and Efficient Inference for GNNs
Nov 28, 2022



While many systems have been developed to train Graph Neural Networks (GNNs), efficient model inference and evaluation remain to be addressed. For instance, using the widely adopted node-wise approach, model evaluation can account for up to 94% of the time in the end-to-end training process due to neighbor explosion, which means that a node accesses its multi-hop neighbors. On the other hand, layer-wise inference avoids the neighbor explosion problem by conducting inference layer by layer such that the nodes only need their one-hop neighbors in each layer. However, implementing layer-wise inference requires substantial engineering efforts because users need to manually decompose a GNN model into layers for computation and split workload into batches to fit into device memory. In this paper, we develop Deep Graph Inference (DGI) -- a system for easy and efficient GNN model inference, which automatically translates the training code of a GNN model for layer-wise execution. DGI is general for various GNN models and different kinds of inference requests, and supports out-of-core execution on large graphs that cannot fit in CPU memory. Experimental results show that DGI consistently outperforms layer-wise inference across different datasets and hardware settings, and the speedup can be over 1,000x.
TensorOpt: Exploring the Tradeoffs in Distributed DNN Training with Auto-Parallelism
Apr 16, 2020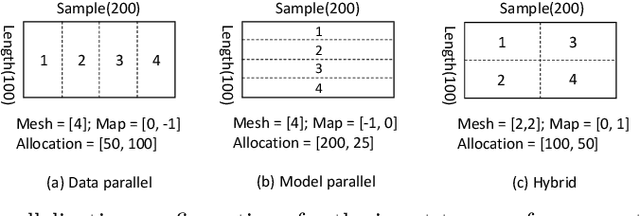
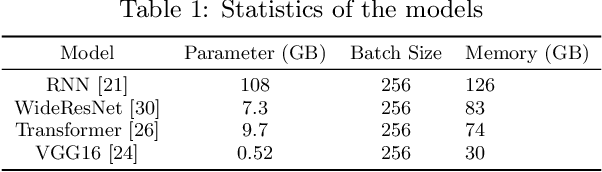
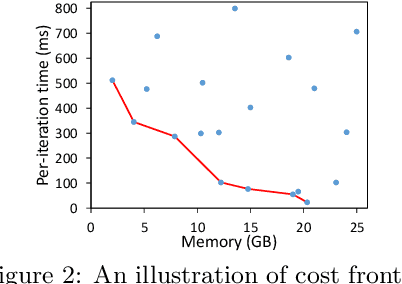

A good parallelization strategy can significantly improve the efficiency or reduce the cost for the distributed training of deep neural networks (DNNs). Recently, several methods have been proposed to find efficient parallelization strategies but they all optimize a single objective (e.g., execution time, memory consumption) and produce only one strategy. We propose FT, an efficient algorithm that searches for an optimal set of parallelization strategies to allow the trade-off among different objectives. FT can adapt to different scenarios by minimizing the memory consumption when the number of devices is limited and fully utilize additional resources to reduce the execution time. For popular DNN models (e.g., vision, language), an in-depth analysis is conducted to understand the trade-offs among different objectives and their influence on the parallelization strategies. We also develop a user-friendly system, called TensorOpt, which allows users to run their distributed DNN training jobs without caring the details of parallelization strategies. Experimental results show that FT runs efficiently and provides accurate estimation of runtime costs, and TensorOpt is more flexible in adapting to resource availability compared with existing frameworks.