 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Perceptual Quality Preserving Image Compression
Aug 16, 2023



We propose conditional perceptual quality, an extension of the perceptual quality defined in \citet{blau2018perception}, by conditioning it on user defined information. Specifically, we extend the original perceptual quality $d(p_{X},p_{\hat{X}})$ to the conditional perceptual quality $d(p_{X|Y},p_{\hat{X}|Y})$, where $X$ is the original image, $\hat{X}$ is the reconstructed, $Y$ is side information defined by user and $d(.,.)$ is divergence. We show that conditional perceptual quality has similar theoretical properties as rate-distortion-perception trade-off \citep{blau2019rethinking}. Based on these theoretical results, we propose an optimal framework for conditional perceptual quality preserving compression. Experimental results show that our codec successfully maintains high perceptual quality and semantic quality at all bitrate. Besides, by providing a lowerbound of common randomness required, we settle the previous arguments on whether randomness should be incorporated into generator for (conditional) perceptual quality compression. The source code is provided in supplementary material.
MapTRv2: An End-to-End Framework for Online Vectorized HD Map Construction
Aug 10, 2023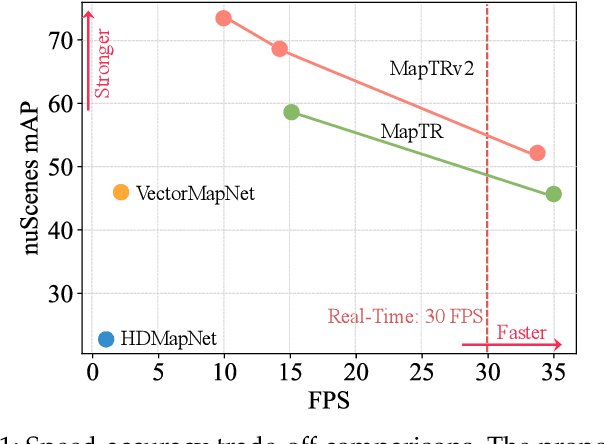
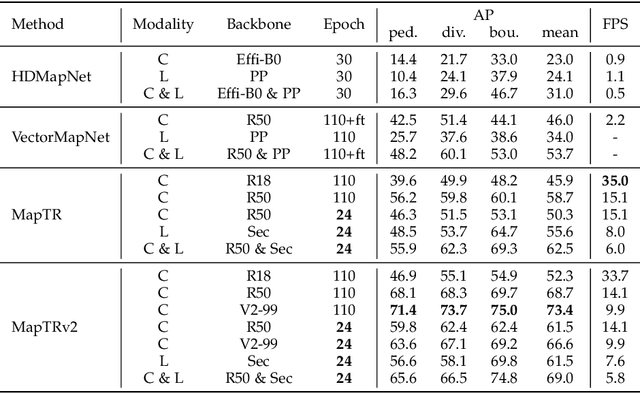
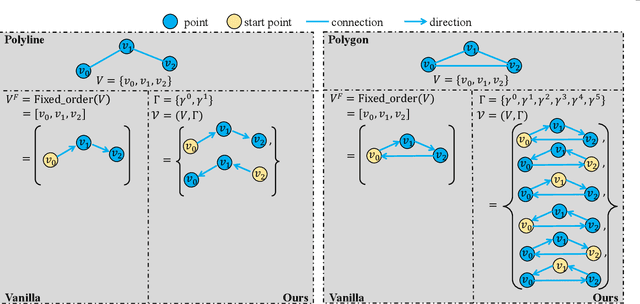
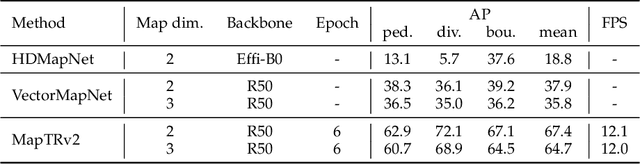
High-definition (HD) map provides abundant and precise static environmental information of the driving scene, serving as a fundamental and indispensable component for planning in autonomous driving system. In this paper, we present \textbf{Map} \textbf{TR}ansformer, an end-to-end framework for online vectorized HD map construction. We propose a unified permutation-equivalent modeling approach, \ie, modeling map element as a point set with a group of equivalent permutations, which accurately describes the shape of map element and stabilizes the learning process. We design a hierarchical query embedding scheme to flexibly encode structured map information and perform hierarchical bipartite matching for map element learning. To speed up convergence, we further introduce auxiliary one-to-many matching and dense supervision. The proposed method well copes with various map elements with arbitrary shapes. It runs at real-time inference speed and achieves state-of-the-art performance on both nuScenes and Argoverse2 datasets. Abundant qualitative results show stable and robust map construction quality in complex and various driving scenes. Code and more demos are available at \url{https://github.com/hustvl/MapTR} for facilitating further studies and applications.
Universal Rates for Multiclass Learning
Jul 05, 2023We study universal rates for multiclass classification, establishing the optimal rates (up to log factors) for all hypothesis classes. This generalizes previous results on binary classification (Bousquet, Hanneke, Moran, van Handel, and Yehudayoff, 2021), and resolves an open question studied by Kalavasis, Velegkas, and Karbasi (2022) who handled the multiclass setting with a bounded number of class labels. In contrast, our result applies for any countable label space. Even for finite label space, our proofs provide a more precise bounds on the learning curves, as they do not depend on the number of labels. Specifically, we show that any class admits exponential rates if and only if it has no infinite Littlestone tree, and admits (near-)linear rates if and only if it has no infinite Daniely-Shalev-Shwartz-Littleston (DSL) tree, and otherwise requires arbitrarily slow rates. DSL trees are a new structure we define in this work, in which each node of the tree is given by a pseudo-cube of possible classifications of a given set of points. Pseudo-cubes are a structure, rooted in the work of Daniely and Shalev-Shwartz (2014), and recently shown by Brukhim, Carmon, Dinur, Moran, and Yehudayoff (2022) to characterize PAC learnability (i.e., uniform rates) for multiclass classification. We also resolve an open question of Kalavasis, Velegkas, and Karbasi (2022) regarding the equivalence of classes having infinite Graph-Littlestone (GL) trees versus infinite Natarajan-Littlestone (NL) trees, showing that they are indeed equivalent.
ProRes: Exploring Degradation-aware Visual Prompt for Universal Image Restoration
Jun 23, 2023Image restoration aims to reconstruct degraded images, e.g., denoising or deblurring. Existing works focus on designing task-specific methods and there are inadequate attempts at universal methods. However, simply unifying multiple tasks into one universal architecture suffers from uncontrollable and undesired predictions. To address those issues, we explore prompt learning in universal architectures for image restoration tasks. In this paper, we present Degradation-aware Visual Prompts, which encode various types of image degradation, e.g., noise and blur, into unified visual prompts. These degradation-aware prompts provide control over image processing and allow weighted combinations for customized image restoration. We then leverage degradation-aware visual prompts to establish a controllable and universal model for image restoration, called ProRes, which is applicable to an extensive range of image restoration tasks. ProRes leverages the vanilla Vision Transformer (ViT) without any task-specific designs. Furthermore, the pre-trained ProRes can easily adapt to new tasks through efficient prompt tuning with only a few images. Without bells and whistles, ProRes achieves competitive performance compared to task-specific methods and experiments can demonstrate its ability for controllable restoration and adaptation for new tasks. The code and models will be released in \url{https://github.com/leonmakise/ProRes}.
RoMe: Towards Large Scale Road Surface Reconstruction via Mesh Representation
Jun 20, 2023



Large-scale road surface reconstruction is becoming important to autonomous driving systems, as it provides valuable training and testing data effectively. In this paper, we introduce a simple yet efficient method, RoMe, for large-scale Road surface reconstruction via Mesh representations. To simplify the problem, RoMe decomposes a 3D road surface into a triangle-mesh and a multilayer perception network to model the road elevation implicitly. To retain fine surface details, each mesh vertex has two extra attributes, namely color and semantics. To improve the efficiency of RoMe in large-scale environments, a novel waypoint sampling method is introduced. As such, RoMe can properly preserve road surface details, with only linear computational complexity to road areas. In addition, to improve the accuracy of RoMe, extrinsics optimization is proposed to mitigate inaccurate extrinsic calibrations. Experimental results on popular public datasets also demonstrate the high efficiency and accuracy of RoMe.
Augmenting Greybox Fuzzing with Generative AI
Jun 11, 2023Real-world programs expecting structured inputs often has a format-parsing stage gating the deeper program space. Neither a mutation-based approach nor a generative approach can provide a solution that is effective and scalable. Large language models (LLM) pre-trained with an enormous amount of natural language corpus have proved to be effective for understanding the implicit format syntax and generating format-conforming inputs. In this paper, propose ChatFuzz, a greybox fuzzer augmented by generative AI. More specifically, we pick a seed in the fuzzer's seed pool and prompt ChatGPT generative models to variations, which are more likely to be format-conforming and thus of high quality. We conduct extensive experiments to explore the best practice for harvesting the power of generative LLM models. The experiment results show that our approach improves the edge coverage by 12.77\% over the SOTA greybox fuzzer (AFL++) on 12 target programs from three well-tested benchmarks. As for vulnerability detection, \sys is able to perform similar to or better than AFL++ for programs with explicit syntax rules but not for programs with non-trivial syntax.
VMA: Divide-and-Conquer Vectorized Map Annotation System for Large-Scale Driving Scene
Apr 19, 2023



High-definition (HD) map serves as the essential infrastructure of autonomous driving. In this work, we build up a systematic vectorized map annotation framework (termed VMA) for efficiently generating HD map of large-scale driving scene. We design a divide-and-conquer annotation scheme to solve the spatial extensibility problem of HD map generation, and abstract map elements with a variety of geometric patterns as unified point sequence representation, which can be extended to most map elements in the driving scene. VMA is highly efficient and extensible, requiring negligible human effort, and flexible in terms of spatial scale and element type. We quantitatively and qualitatively validate the annotation performance on real-world urban and highway scenes, as well as NYC Planimetric Database. VMA can significantly improve map generation efficiency and require little human effort. On average VMA takes 160min for annotating a scene with a range of hundreds of meters, and reduces 52.3% of the human cost, showing great application value.
TinyDet: Accurate Small Object Detection in Lightweight Generic Detectors
Apr 07, 2023



Small object detection requires the detection head to scan a large number of positions on image feature maps, which is extremely hard for computation- and energy-efficient lightweight generic detectors. To accurately detect small objects with limited computation, we propose a two-stage lightweight detection framework with extremely low computation complexity, termed as TinyDet. It enables high-resolution feature maps for dense anchoring to better cover small objects, proposes a sparsely-connected convolution for computation reduction, enhances the early stage features in the backbone, and addresses the feature misalignment problem for accurate small object detection. On the COCO benchmark, our TinyDet-M achieves 30.3 AP and 13.5 AP^s with only 991 MFLOPs, which is the first detector that has an AP over 30 with less than 1 GFLOPs; besides, TinyDet-S and TinyDet-L achieve promising performance under different computation limitation.
OpenInst: A Simple Query-Based Method for Open-World Instance Segmentation
Mar 28, 2023



Open-world instance segmentation has recently gained significant popularitydue to its importance in many real-world applications, such as autonomous driving, robot perception, and remote sensing. However, previous methods have either produced unsatisfactory results or relied on complex systems and paradigms. We wonder if there is a simple way to obtain state-of-the-art results. Fortunately, we have identified two observations that help us achieve the best of both worlds: 1) query-based methods demonstrate superiority over dense proposal-based methods in open-world instance segmentation, and 2) learning localization cues is sufficient for open world instance segmentation. Based on these observations, we propose a simple query-based method named OpenInst for open world instance segmentation. OpenInst leverages advanced query-based methods like QueryInst and focuses on learning localization cues. Notably, OpenInst is an extremely simple and straightforward framework without any auxiliary modules or post-processing, yet achieves state-of-the-art results on multiple benchmarks. Specifically, in the COCO$\to$UVO scenario, OpenInst achieves a mask AR of 53.3, outperforming the previous best methods by 2.0 AR with a simpler structure. We hope that OpenInst can serve as a solid baselines for future research in this area.
Multi-Granularity Archaeological Dating of Chinese Bronze Dings Based on a Knowledge-Guided Relation Graph
Mar 27, 2023



The archaeological dating of bronze dings has played a critical role in the study of ancient Chinese history. Current archaeology depends on trained experts to carry out bronze dating, which is time-consuming and labor-intensive. For such dating, in this study, we propose a learning-based approach to integrate advanced deep learning techniques and archaeological knowledge. To achieve this, we first collect a large-scale image dataset of bronze dings, which contains richer attribute information than other existing fine-grained datasets. Second, we introduce a multihead classifier and a knowledge-guided relation graph to mine the relationship between attributes and the ding era. Third, we conduct comparison experiments with various existing methods, the results of which show that our dating method achieves a state-of-the-art performance. We hope that our data and applied networks will enrich fine-grained classification research relevant to other interdisciplinary areas of expertise. The dataset and source code used are included in our supplementary materials, and will be open after submission owing to the anonymity policy. Source codes and data are available at: https://github.com/zhourixin/bronze-Ding.