 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQi Li
Biphasic Face Photo-Sketch Synthesis via Semantic-Driven Generative Adversarial Network with Graph Representation Learning
Jan 05, 2022
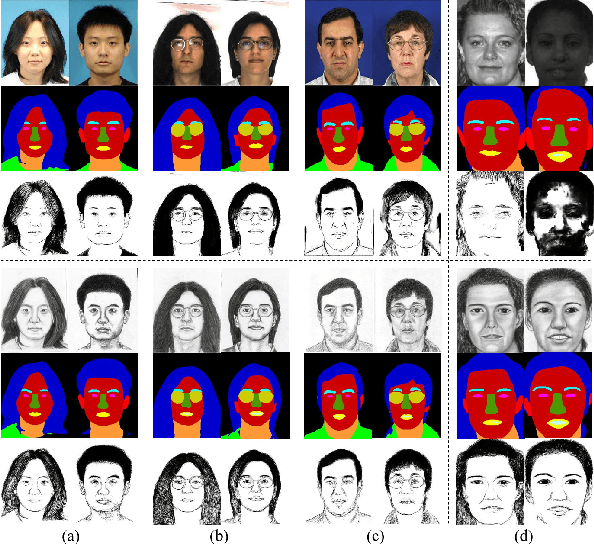
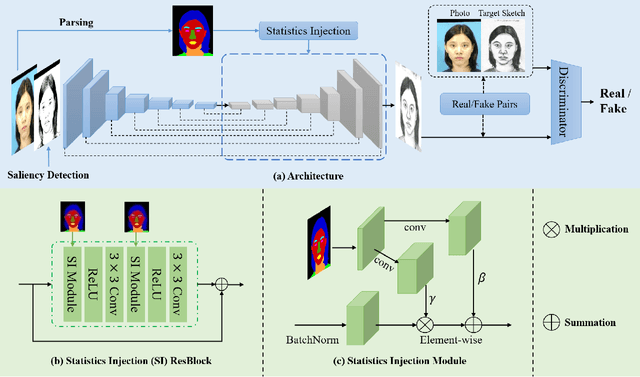
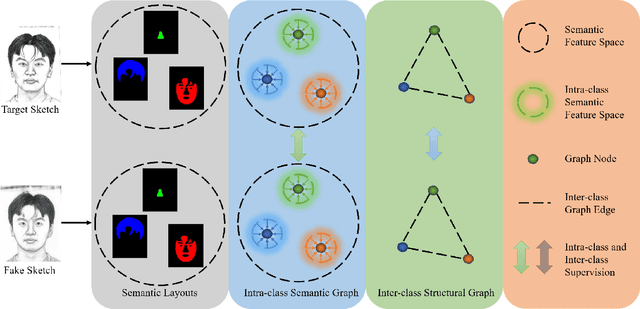
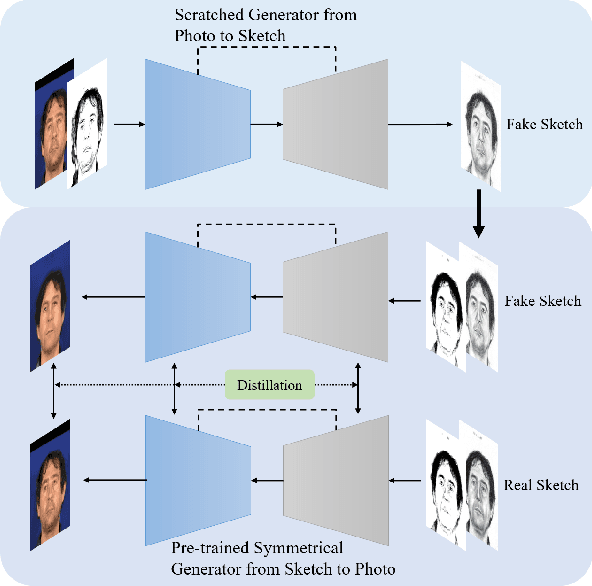
In recent years, significant progress has been achieved in biphasic face photo-sketch synthesis with the development of Generative Adversarial Network (GAN). Biphasic face photo-sketch synthesis could be applied in wide-ranging fields such as digital entertainment and law enforcement. However, generating realistic photos and distinct sketches suffers from great challenges due to the low quality of sketches and complex photo variations in the real scenes. To this end, we propose a novel Semantic-Driven Generative Adversarial Network to address the above issues, cooperating with the Graph Representation Learning. Specifically, we inject class-wise semantic layouts into the generator to provide style-based spatial supervision for synthesized face photos and sketches. In addition, to improve the fidelity of the generated results, we leverage the semantic layouts to construct two types of Representational Graphs which indicate the intra-class semantic features and inter-class structural features of the synthesized images. Furthermore, we design two types of constraints based on the proposed Representational Graphs which facilitate the preservation of the details in generated face photos and sketches. Moreover, to further enhance the perceptual quality of synthesized images, we propose a novel biphasic training strategy which is dedicated to refine the generated results through Iterative Cycle Training. Extensive experiments are conducted on CUFS and CUFSF datasets to demonstrate the prominent ability of our proposed method which achieves the state-of-the-art performance.
IFR-Explore: Learning Inter-object Functional Relationships in 3D Indoor Scenes
Dec 18, 2021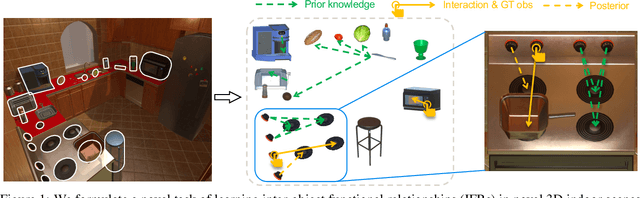
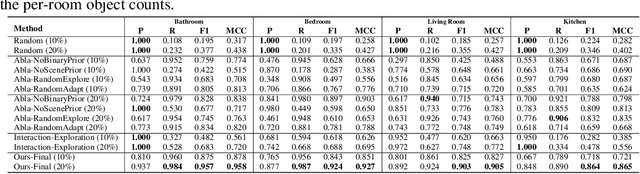
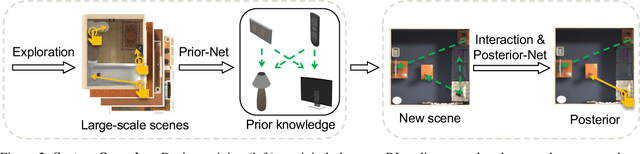

Building embodied intelligent agents that can interact with 3D indoor environments has received increasing research attention in recent years. While most works focus on single-object or agent-object visual functionality and affordances, our work proposes to study a new kind of visual relationship that is also important to perceive and model -- inter-object functional relationships (e.g., a switch on the wall turns on or off the light, a remote control operates the TV). Humans often spend little or no effort to infer these relationships, even when entering a new room, by using our strong prior knowledge (e.g., we know that buttons control electrical devices) or using only a few exploratory interactions in cases of uncertainty (e.g., multiple switches and lights in the same room). In this paper, we take the first step in building AI system learning inter-object functional relationships in 3D indoor environments with key technical contributions of modeling prior knowledge by training over large-scale scenes and designing interactive policies for effectively exploring the training scenes and quickly adapting to novel test scenes. We create a new benchmark based on the AI2Thor and PartNet datasets and perform extensive experiments that prove the effectiveness of our proposed method. Results show that our model successfully learns priors and fast-interactive-adaptation strategies for exploring inter-object functional relationships in complex 3D scenes. Several ablation studies further validate the usefulness of each proposed module.
Black-box Adversarial Attacks on Commercial Speech Platforms with Minimal Information
Oct 19, 2021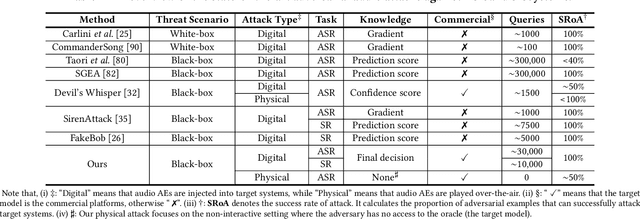

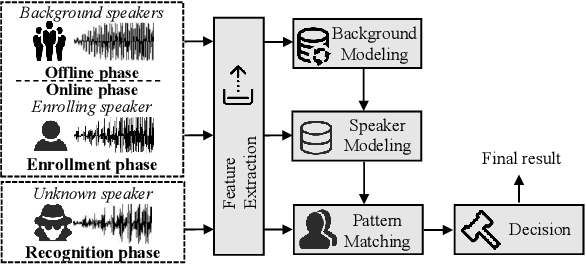
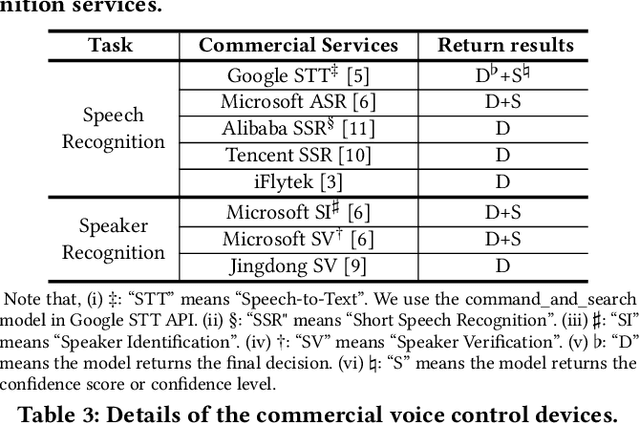
Adversarial attacks against commercial black-box speech platforms, including cloud speech APIs and voice control devices, have received little attention until recent years. The current "black-box" attacks all heavily rely on the knowledge of prediction/confidence scores to craft effective adversarial examples, which can be intuitively defended by service providers without returning these messages. In this paper, we propose two novel adversarial attacks in more practical and rigorous scenarios. For commercial cloud speech APIs, we propose Occam, a decision-only black-box adversarial attack, where only final decisions are available to the adversary. In Occam, we formulate the decision-only AE generation as a discontinuous large-scale global optimization problem, and solve it by adaptively decomposing this complicated problem into a set of sub-problems and cooperatively optimizing each one. Our Occam is a one-size-fits-all approach, which achieves 100% success rates of attacks with an average SNR of 14.23dB, on a wide range of popular speech and speaker recognition APIs, including Google, Alibaba, Microsoft, Tencent, iFlytek, and Jingdong, outperforming the state-of-the-art black-box attacks. For commercial voice control devices, we propose NI-Occam, the first non-interactive physical adversarial attack, where the adversary does not need to query the oracle and has no access to its internal information and training data. We combine adversarial attacks with model inversion attacks, and thus generate the physically-effective audio AEs with high transferability without any interaction with target devices. Our experimental results show that NI-Occam can successfully fool Apple Siri, Microsoft Cortana, Google Assistant, iFlytek and Amazon Echo with an average SRoA of 52% and SNR of 9.65dB, shedding light on non-interactive physical attacks against voice control devices.
A Unified Framework for Biphasic Facial Age Translation with Noisy-Semantic Guided Generative Adversarial Networks
Sep 15, 2021
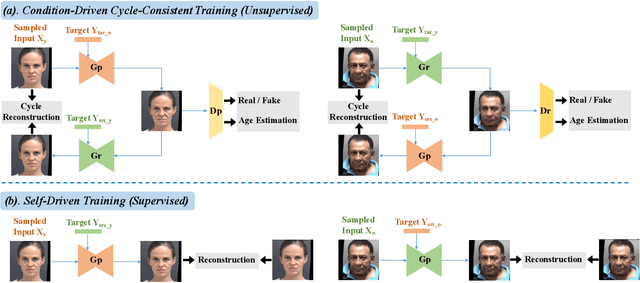
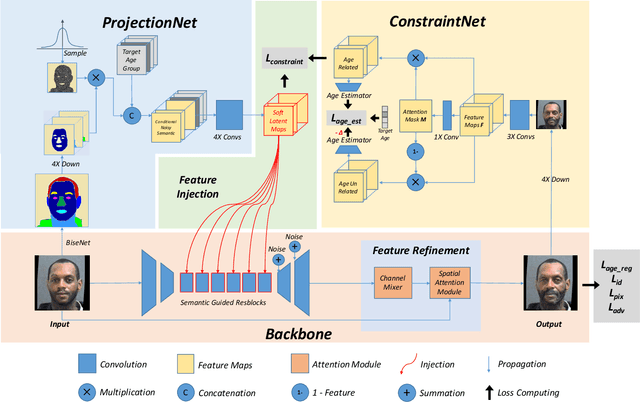

Biphasic facial age translation aims at predicting the appearance of the input face at any age. Facial age translation has received considerable research attention in the last decade due to its practical value in cross-age face recognition and various entertainment applications. However, most existing methods model age changes between holistic images, regardless of the human face structure and the age-changing patterns of individual facial components. Consequently, the lack of semantic supervision will cause infidelity of generated faces in detail. To this end, we propose a unified framework for biphasic facial age translation with noisy-semantic guided generative adversarial networks. Structurally, we project the class-aware noisy semantic layouts to soft latent maps for the following injection operation on the individual facial parts. In particular, we introduce two sub-networks, ProjectionNet and ConstraintNet. ProjectionNet introduces the low-level structural semantic information with noise map and produces soft latent maps. ConstraintNet disentangles the high-level spatial features to constrain the soft latent maps, which endows more age-related context into the soft latent maps. Specifically, attention mechanism is employed in ConstraintNet for feature disentanglement. Meanwhile, in order to mine the strongest mapping ability of the network, we embed two types of learning strategies in the training procedure, supervised self-driven generation and unsupervised condition-driven cycle-consistent generation. As a result, extensive experiments conducted on MORPH and CACD datasets demonstrate the prominent ability of our proposed method which achieves state-of-the-art performance.
Truth Discovery in Sequence Labels from Crowds
Sep 09, 2021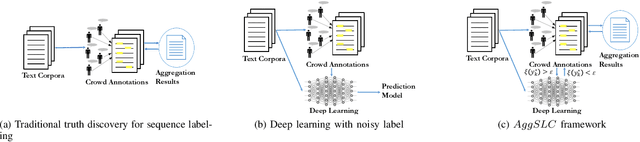
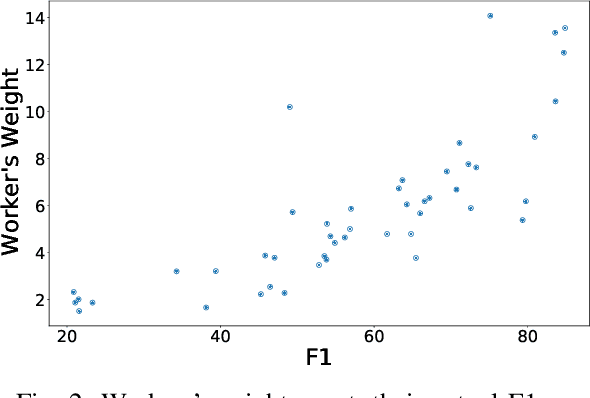
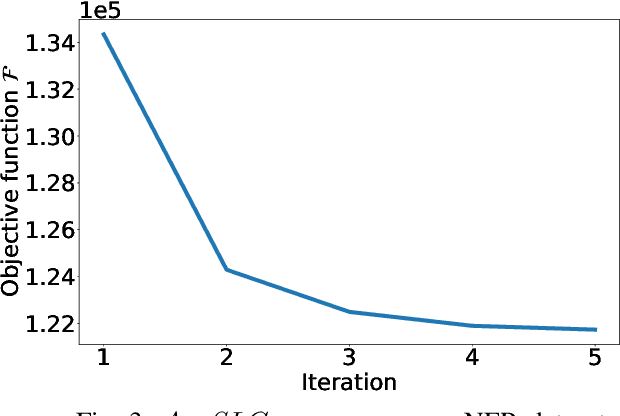
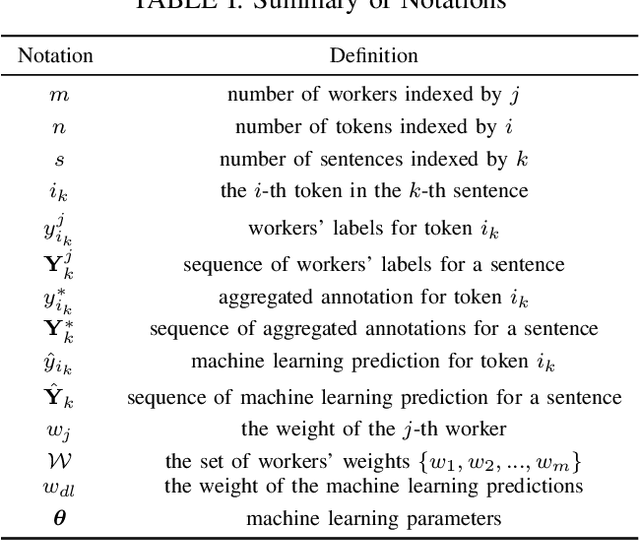
Annotations quality and quantity positively affect the performance of sequence labeling, a vital task in Natural Language Processing. Hiring domain experts to annotate a corpus set is very costly in terms of money and time. Crowdsourcing platforms, such as Amazon Mechanical Turk (AMT), have been deployed to assist in this purpose. However, these platforms are prone to human errors due to the lack of expertise; hence, one worker's annotations cannot be directly used to train the model. Existing literature in annotation aggregation more focuses on binary or multi-choice problems. In recent years, handling the sequential label aggregation tasks on imbalanced datasets with complex dependencies between tokens has been challenging. To conquer the challenge, we propose an optimization-based method that infers the best set of aggregated annotations using labels provided by workers. The proposed Aggregation method for Sequential Labels from Crowds ($AggSLC$) jointly considers the characteristics of sequential labeling tasks, workers' reliabilities, and advanced machine learning techniques. We evaluate $AggSLC$ on different crowdsourced data for Named Entity Recognition (NER), Information Extraction tasks in biomedical (PICO), and the simulated dataset. Our results show that the proposed method outperforms the state-of-the-art aggregation methods. To achieve insights into the framework, we study $AggSLC$ components' effectiveness through ablation studies by evaluating our model in the absence of the prediction module and inconsistency loss function. Theoretical analysis of our algorithm's convergence points that the proposed $AggSLC$ halts after a finite number of iterations.
From Contexts to Locality: Ultra-high Resolution Image Segmentation via Locality-aware Contextual Correlation
Sep 06, 2021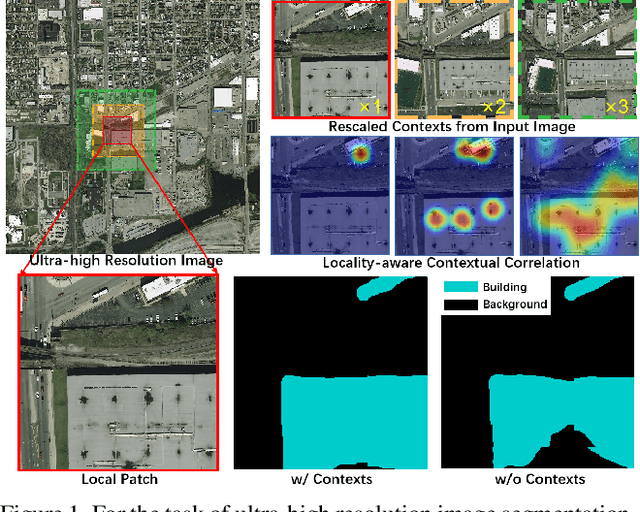
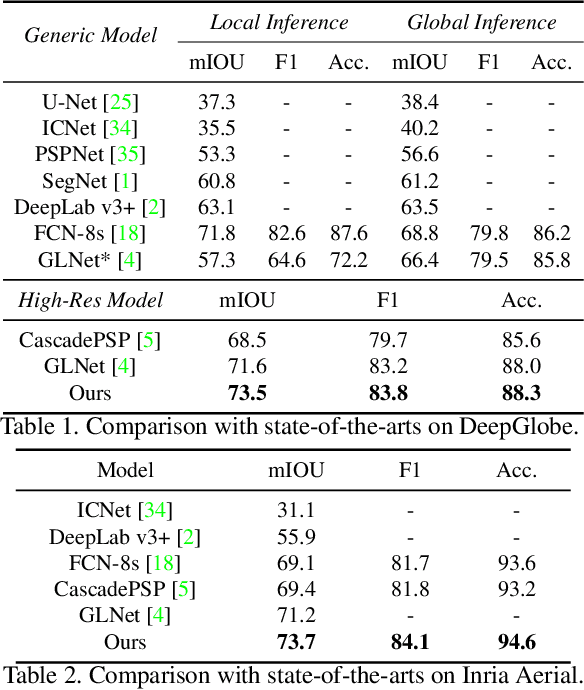
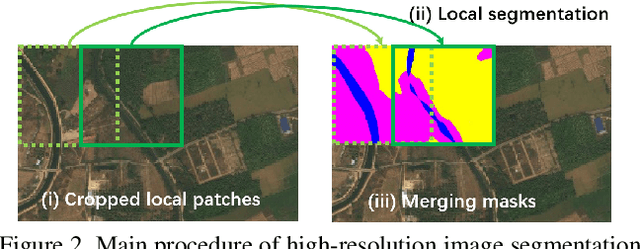
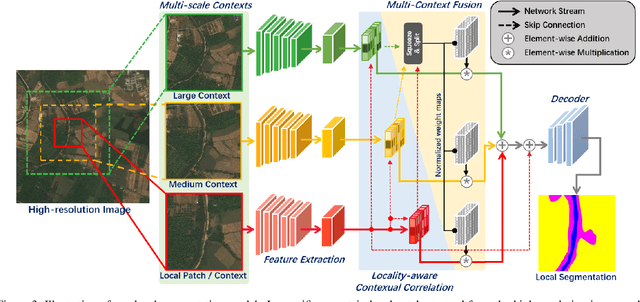
Ultra-high resolution image segmentation has raised increasing interests in recent years due to its realistic applications. In this paper, we innovate the widely used high-resolution image segmentation pipeline, in which an ultra-high resolution image is partitioned into regular patches for local segmentation and then the local results are merged into a high-resolution semantic mask. In particular, we introduce a novel locality-aware contextual correlation based segmentation model to process local patches, where the relevance between local patch and its various contexts are jointly and complementarily utilized to handle the semantic regions with large variations. Additionally, we present a contextual semantics refinement network that associates the local segmentation result with its contextual semantics, and thus is endowed with the ability of reducing boundary artifacts and refining mask contours during the generation of final high-resolution mask. Furthermore, in comprehensive experiments, we demonstrate that our model outperforms other state-of-the-art methods in public benchmarks. Our released codes are available at https://github.com/liqiokkk/FCtL.
Towards Balanced Learning for Instance Recognition
Aug 23, 2021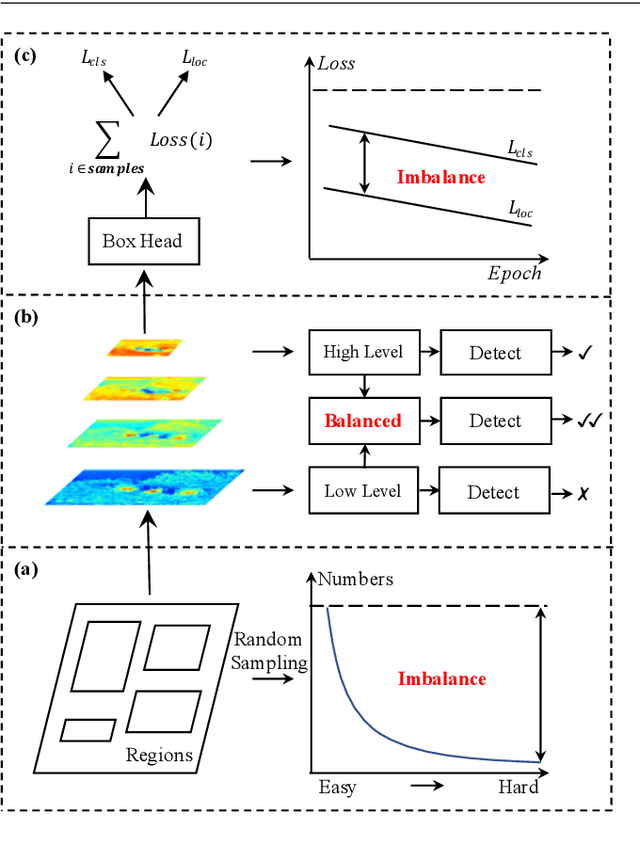
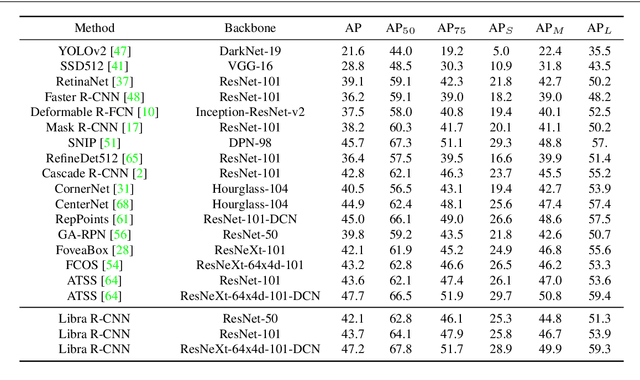
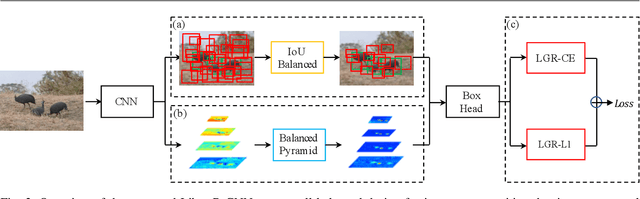
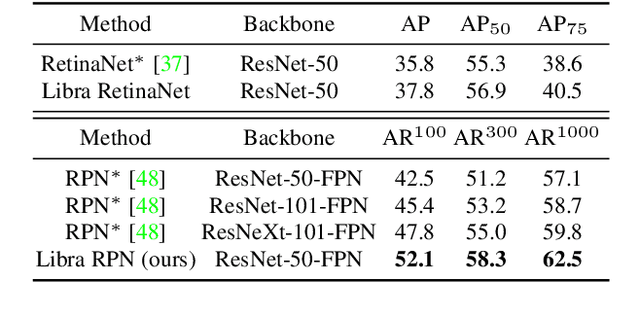
Instance recognition is rapidly advanced along with the developments of various deep convolutional neural networks. Compared to the architectures of networks, the training process, which is also crucial to the success of detectors, has received relatively less attention. In this work, we carefully revisit the standard training practice of detectors, and find that the detection performance is often limited by the imbalance during the training process, which generally consists in three levels - sample level, feature level, and objective level. To mitigate the adverse effects caused thereby, we propose Libra R-CNN, a simple yet effective framework towards balanced learning for instance recognition. It integrates IoU-balanced sampling, balanced feature pyramid, and objective re-weighting, respectively for reducing the imbalance at sample, feature, and objective level. Extensive experiments conducted on MS COCO, LVIS and Pascal VOC datasets prove the effectiveness of the overall balanced design.
A Hard Label Black-box Adversarial Attack Against Graph Neural Networks
Aug 21, 2021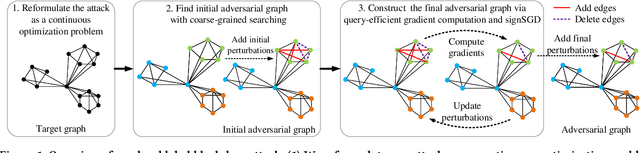
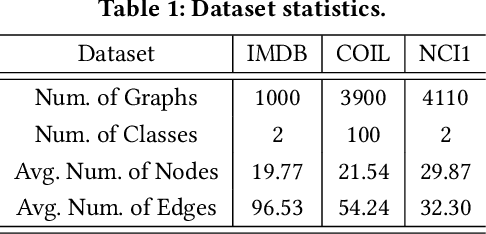
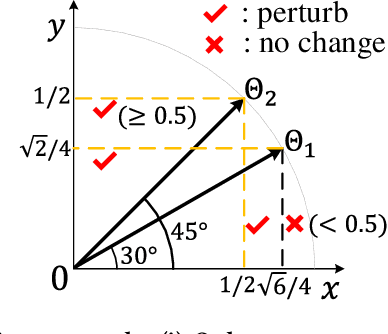
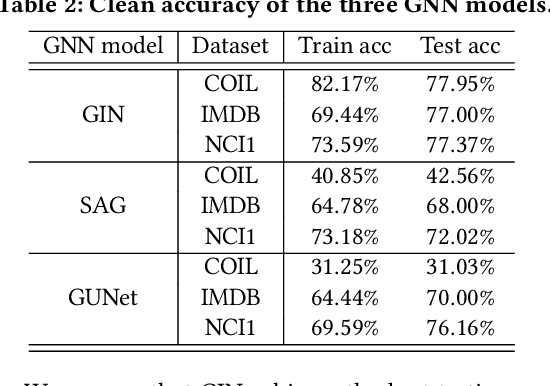
Graph Neural Networks (GNNs) have achieved state-of-the-art performance in various graph structure related tasks such as node classification and graph classification. However, GNNs are vulnerable to adversarial attacks. Existing works mainly focus on attacking GNNs for node classification; nevertheless, the attacks against GNNs for graph classification have not been well explored. In this work, we conduct a systematic study on adversarial attacks against GNNs for graph classification via perturbing the graph structure. In particular, we focus on the most challenging attack, i.e., hard label black-box attack, where an attacker has no knowledge about the target GNN model and can only obtain predicted labels through querying the target model.To achieve this goal, we formulate our attack as an optimization problem, whose objective is to minimize the number of edges to be perturbed in a graph while maintaining the high attack success rate. The original optimization problem is intractable to solve, and we relax the optimization problem to be a tractable one, which is solved with theoretical convergence guarantee. We also design a coarse-grained searching algorithm and a query-efficient gradient computation algorithm to decrease the number of queries to the target GNN model. Our experimental results on three real-world datasets demonstrate that our attack can effectively attack representative GNNs for graph classification with less queries and perturbations. We also evaluate the effectiveness of our attack under two defenses: one is well-designed adversarial graph detector and the other is that the target GNN model itself is equipped with a defense to prevent adversarial graph generation. Our experimental results show that such defenses are not effective enough, which highlights more advanced defenses.
Contrastive Learning for Cold-Start Recommendation
Jul 15, 2021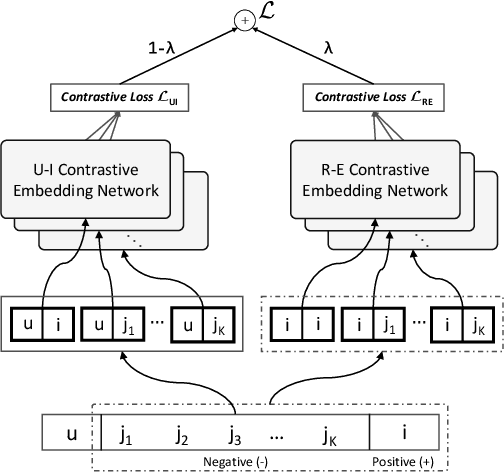
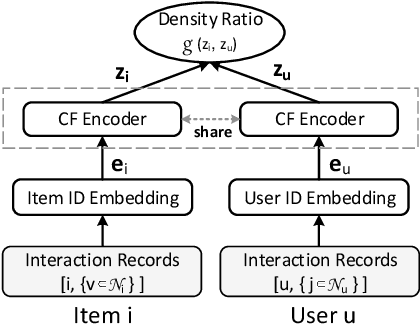
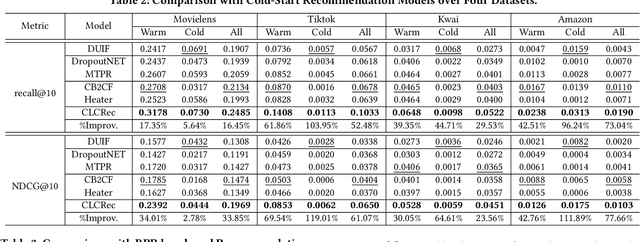
Recommending cold-start items is a long-standing and fundamental challenge in recommender systems. Without any historical interaction on cold-start items, CF scheme fails to use collaborative signals to infer user preference on these items. To solve this problem, extensive studies have been conducted to incorporate side information into the CF scheme. Specifically, they employ modern neural network techniques (e.g., dropout, consistency constraint) to discover and exploit the coalition effect of content features and collaborative representations. However, we argue that these works less explore the mutual dependencies between content features and collaborative representations and lack sufficient theoretical supports, thus resulting in unsatisfactory performance. In this work, we reformulate the cold-start item representation learning from an information-theoretic standpoint. It aims to maximize the mutual dependencies between item content and collaborative signals. Specifically, the representation learning is theoretically lower-bounded by the integration of two terms: mutual information between collaborative embeddings of users and items, and mutual information between collaborative embeddings and feature representations of items. To model such a learning process, we devise a new objective function founded upon contrastive learning and develop a simple yet effective Contrastive Learning-based Cold-start Recommendation framework(CLCRec). In particular, CLCRec consists of three components: contrastive pair organization, contrastive embedding, and contrastive optimization modules. It allows us to preserve collaborative signals in the content representations for both warm and cold-start items. Through extensive experiments on four publicly accessible datasets, we observe that CLCRec achieves significant improvements over state-of-the-art approaches in both warm- and cold-start scenarios.