 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVOID: Defeating Unauthorized Mimicry in Latent Diffusion Models
Jun 11, 2026While Latent Diffusion Models (LDMs) have revolutionized visual synthesis, they are increasingly exploited for unauthorized mimicry of individuals. Existing defenses inject deceptive perturbations to steer the generated images toward irrelevant targets. However, this approach hinges on an ungrounded assumption: subtle perturbations can maintain their deceptive efficacy throughout an LDM's extensive generation process. In reality, the model's innate restoration mechanism will remove such perturbations and cause individual identities to re-emerge in the images generated. We propose VOID, a defense framework that overcomes this conundrum by manipulating an LDM's intrinsic stochasticity. VOID perturbs the diffusion pipeline in two novel ways: 1) amplifying the latent encoding errors to shatter an image's semantic structure, and 2) counteracting the target guidance signals to suppress the model's restoration capabilities. This results in a semantic corruption that thwarts any unauthorized mimicry. Notably, the security gain does not come at the price of visual utility, as VOID simultaneously manages to confine perturbations to human-imperceptible regions of protected images. Our comprehensive evaluation of 24 state-of-the-art defenses against 10 mimicry attacks on 5 datasets demonstrates VOID's unprecedented protection power: it increases the average Frechet Inception Distance (FID) from 113 to 365, a 223% improvement over the strongest defense to date.
Solid-SQL: Enhanced Schema-linking based In-context Learning for Robust Text-to-SQL
Dec 17, 2024

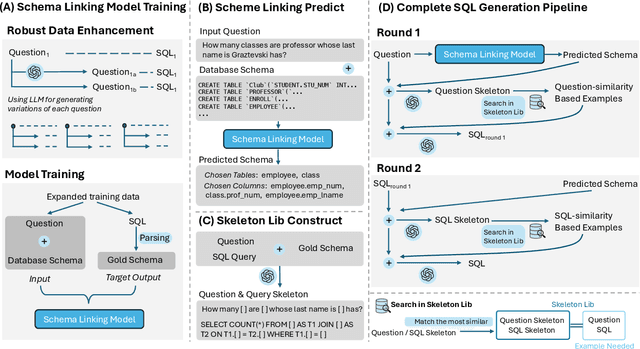

Recently, large language models (LLMs) have significantly improved the performance of text-to-SQL systems. Nevertheless, many state-of-the-art (SOTA) approaches have overlooked the critical aspect of system robustness. Our experiments reveal that while LLM-driven methods excel on standard datasets, their accuracy is notably compromised when faced with adversarial perturbations. To address this challenge, we propose a robust text-to-SQL solution, called Solid-SQL, designed to integrate with various LLMs. We focus on the pre-processing stage, training a robust schema-linking model enhanced by LLM-based data augmentation. Additionally, we design a two-round, structural similarity-based example retrieval strategy for in-context learning. Our method achieves SOTA SQL execution accuracy levels of 82.1% and 58.9% on the general Spider and Bird benchmarks, respectively. Furthermore, experimental results show that Solid-SQL delivers an average improvement of 11.6% compared to baselines on the perturbed Spider-Syn, Spider-Realistic, and Dr. Spider benchmarks.
Zero-Query Adversarial Attack on Black-box Automatic Speech Recognition Systems
Jun 27, 2024



In recent years, extensive research has been conducted on the vulnerability of ASR systems, revealing that black-box adversarial example attacks pose significant threats to real-world ASR systems. However, most existing black-box attacks rely on queries to the target ASRs, which is impractical when queries are not permitted. In this paper, we propose ZQ-Attack, a transfer-based adversarial attack on ASR systems in the zero-query black-box setting. Through a comprehensive review and categorization of modern ASR technologies, we first meticulously select surrogate ASRs of diverse types to generate adversarial examples. Following this, ZQ-Attack initializes the adversarial perturbation with a scaled target command audio, rendering it relatively imperceptible while maintaining effectiveness. Subsequently, to achieve high transferability of adversarial perturbations, we propose a sequential ensemble optimization algorithm, which iteratively optimizes the adversarial perturbation on each surrogate model, leveraging collaborative information from other models. We conduct extensive experiments to evaluate ZQ-Attack. In the over-the-line setting, ZQ-Attack achieves a 100% success rate of attack (SRoA) with an average signal-to-noise ratio (SNR) of 21.91dB on 4 online speech recognition services, and attains an average SRoA of 100% and SNR of 19.67dB on 16 open-source ASRs. For commercial intelligent voice control devices, ZQ-Attack also achieves a 100% SRoA with an average SNR of 15.77dB in the over-the-air setting.
Enhancing Adversarial Transferability Through Neighborhood Conditional Sampling
May 25, 2024



Transfer-based attacks craft adversarial examples utilizing a white-box surrogate model to compromise various black-box target models, posing significant threats to many real-world applications. However, existing transfer attacks suffer from either weak transferability or expensive computation. To bridge the gap, we propose a novel sample-based attack, named neighborhood conditional sampling (NCS), which enjoys high transferability with lightweight computation. Inspired by the observation that flat maxima result in better transferability, NCS is formulated as a max-min bi-level optimization problem to seek adversarial regions with high expected adversarial loss and small standard deviations. Specifically, due to the inner minimization problem being computationally intensive to resolve, and affecting the overall transferability, we propose a momentum-based previous gradient inversion approximation (PGIA) method to effectively solve the inner problem without any computation cost. In addition, we prove that two newly proposed attacks, which achieve flat maxima for better transferability, are actually specific cases of NCS under particular conditions. Extensive experiments demonstrate that NCS efficiently generates highly transferable adversarial examples, surpassing the current best method in transferability while requiring only 50% of the computational cost. Additionally, NCS can be seamlessly integrated with other methods to further enhance transferability.
Revisiting Adversarial Training under Long-Tailed Distributions
Mar 15, 2024



Deep neural networks are vulnerable to adversarial attacks, often leading to erroneous outputs. Adversarial training has been recognized as one of the most effective methods to counter such attacks. However, existing adversarial training techniques have predominantly been tested on balanced datasets, whereas real-world data often exhibit a long-tailed distribution, casting doubt on the efficacy of these methods in practical scenarios. In this paper, we delve into adversarial training under long-tailed distributions. Through an analysis of the previous work "RoBal", we discover that utilizing Balanced Softmax Loss alone can achieve performance comparable to the complete RoBal approach while significantly reducing training overheads. Additionally, we reveal that, similar to uniform distributions, adversarial training under long-tailed distributions also suffers from robust overfitting. To address this, we explore data augmentation as a solution and unexpectedly discover that, unlike results obtained with balanced data, data augmentation not only effectively alleviates robust overfitting but also significantly improves robustness. We further investigate the reasons behind the improvement of robustness through data augmentation and identify that it is attributable to the increased diversity of examples. Extensive experiments further corroborate that data augmentation alone can significantly improve robustness. Finally, building on these findings, we demonstrate that compared to RoBal, the combination of BSL and data augmentation leads to a +6.66% improvement in model robustness under AutoAttack on CIFAR-10-LT. Our code is available at https://github.com/NISPLab/AT-BSL .
Universal Defensive Underpainting Patch: Making Your Text Invisible to Optical Character Recognition
Aug 04, 2023



Optical Character Recognition (OCR) enables automatic text extraction from scanned or digitized text images, but it also makes it easy to pirate valuable or sensitive text from these images. Previous methods to prevent OCR piracy by distorting characters in text images are impractical in real-world scenarios, as pirates can capture arbitrary portions of the text images, rendering the defenses ineffective. In this work, we propose a novel and effective defense mechanism termed the Universal Defensive Underpainting Patch (UDUP) that modifies the underpainting of text images instead of the characters. UDUP is created through an iterative optimization process to craft a small, fixed-size defensive patch that can generate non-overlapping underpainting for text images of any size. Experimental results show that UDUP effectively defends against unauthorized OCR under the setting of any screenshot range or complex image background. It is agnostic to the content, size, colors, and languages of characters, and is robust to typical image operations such as scaling and compressing. In addition, the transferability of UDUP is demonstrated by evading several off-the-shelf OCRs. The code is available at https://github.com/QRICKDD/UDUP.
Shielding Collaborative Learning: Mitigating Poisoning Attacks through Client-Side Detection
Oct 29, 2019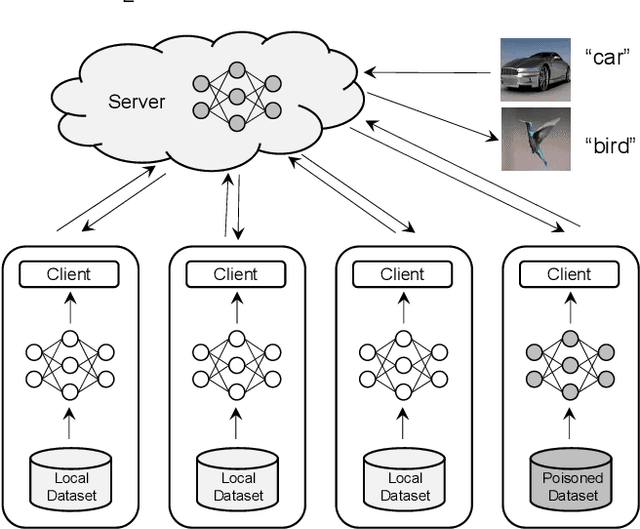

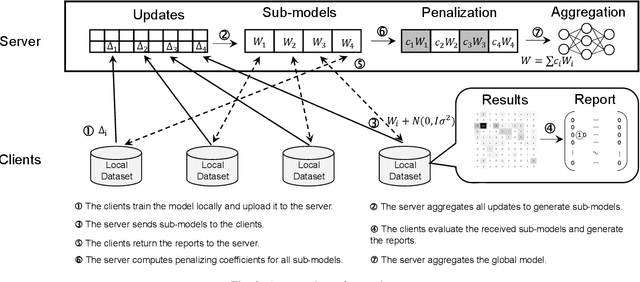

Collaborative learning allows multiple clients to train a joint model without sharing their data with each other. Each client performs training locally and then submits the model updates to a central server for aggregation. Since the server has no visibility into the process of generating the updates, collaborative learning is vulnerable to poisoning attacks where a malicious client can generate a poisoned update to introduce backdoor functionality to the joint model. The existing solutions for detecting poisoned updates, however, fail to defend against the recently proposed attacks, especially in the non-IID setting. In this paper, we present a novel defense scheme to detect anomalous updates in both IID and non-IID settings. Our key idea is to realize client-side cross-validation, where each update is evaluated over other clients' local data. The server will adjust the weights of the updates based on the evaluation results when performing aggregation. To adapt to the unbalanced distribution of data in the non-IID setting, a dynamic client allocation mechanism is designed to assign detection tasks to the most suitable clients. During the detection process, we also protect the client-level privacy to prevent malicious clients from stealing the training data of other clients, by integrating differential privacy with our design without degrading the detection performance. Our experimental evaluations on two real-world datasets show that our scheme is significantly robust to two representative poisoning attacks.
Privacy-Preserving Collaborative Deep Learning with Irregular Participants
Dec 25, 2018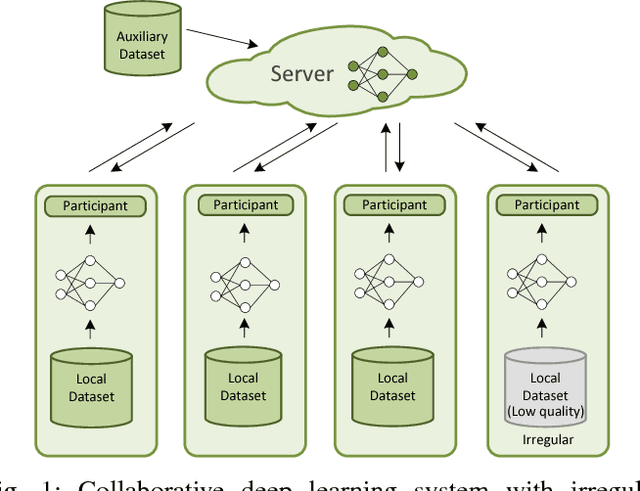
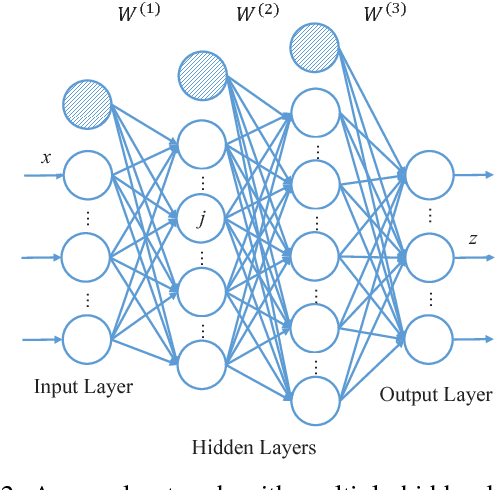
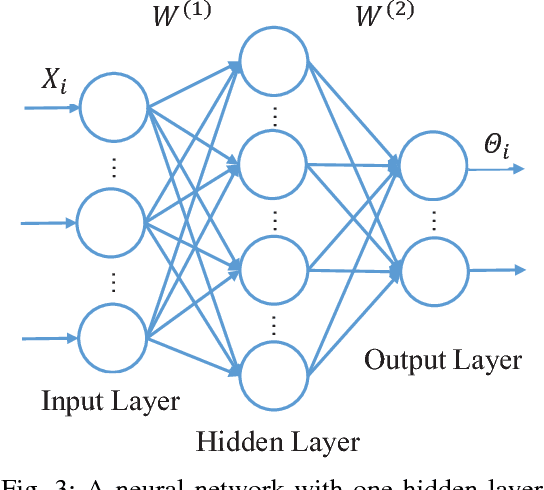
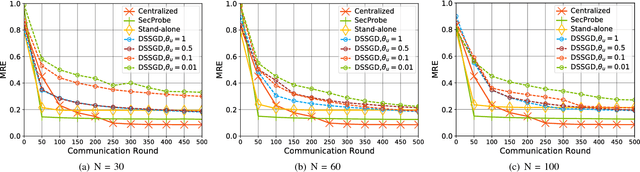
With large amounts of data collected from massive sensors, mobile users and institutions becomes widely available, neural network based deep learning is becoming increasingly popular and making great success in many application scenarios, such as image detection, speech recognition and machine translation. While deep learning can provide various benefits, the data for training usually contains highly sensitive information, e.g., personal medical records, and a central location for saving the data may pose a considerable threat to user privacy. In this paper, we present a practical privacy-preserving collaborative deep learning system that allows users (i.e., participants) to cooperatively build a collective deep learning model with data of all participants, without direct data sharing and central data storage. In our system, each participant trains a local model with their own data and only shares model parameters with the others. To further avoid potential privacy leakage from sharing model parameters, we use functional mechanism to perturb the objective function of the neural network in the training process to achieve $\epsilon$-differential privacy. In particular, for the first time, we consider the possibility that the data of certain participants may be of low quality (called \textit{irregular participants}), and propose a solution to reduce the impact of these participants while protecting their privacy. We evaluate the performance of our system on two well-known real-world data sets for regression and classification tasks. The results demonstrate that our system is robust to irregular participants, and can achieve high accuracy close to the centralized model while ensuring rigorous privacy protection.