 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFNBench: Benchmarking Robust Federated Learning against Noisy Labels
May 10, 2025



Robustness to label noise within data is a significant challenge in federated learning (FL). From the data-centric perspective, the data quality of distributed datasets can not be guaranteed since annotations of different clients contain complicated label noise of varying degrees, which causes the performance degradation. There have been some early attempts to tackle noisy labels in FL. However, there exists a lack of benchmark studies on comprehensively evaluating their practical performance under unified settings. To this end, we propose the first benchmark study FNBench to provide an experimental investigation which considers three diverse label noise patterns covering synthetic label noise, imperfect human-annotation errors and systematic errors. Our evaluation incorporates eighteen state-of-the-art methods over five image recognition datasets and one text classification dataset. Meanwhile, we provide observations to understand why noisy labels impair FL, and additionally exploit a representation-aware regularization method to enhance the robustness of existing methods against noisy labels based on our observations. Finally, we discuss the limitations of this work and propose three-fold future directions. To facilitate related communities, our source code is open-sourced at https://github.com/Sprinter1999/FNBench.
Learning Knowledge-based Prompts for Robust 3D Mask Presentation Attack Detection
May 06, 20253D mask presentation attack detection is crucial for protecting face recognition systems against the rising threat of 3D mask attacks. While most existing methods utilize multimodal features or remote photoplethysmography (rPPG) signals to distinguish between real faces and 3D masks, they face significant challenges, such as the high costs associated with multimodal sensors and limited generalization ability. Detection-related text descriptions offer concise, universal information and are cost-effective to obtain. However, the potential of vision-language multimodal features for 3D mask presentation attack detection remains unexplored. In this paper, we propose a novel knowledge-based prompt learning framework to explore the strong generalization capability of vision-language models for 3D mask presentation attack detection. Specifically, our approach incorporates entities and triples from knowledge graphs into the prompt learning process, generating fine-grained, task-specific explicit prompts that effectively harness the knowledge embedded in pre-trained vision-language models. Furthermore, considering different input images may emphasize distinct knowledge graph elements, we introduce a visual-specific knowledge filter based on an attention mechanism to refine relevant elements according to the visual context. Additionally, we leverage causal graph theory insights into the prompt learning process to further enhance the generalization ability of our method. During training, a spurious correlation elimination paradigm is employed, which removes category-irrelevant local image patches using guidance from knowledge-based text features, fostering the learning of generalized causal prompts that align with category-relevant local patches. Experimental results demonstrate that the proposed method achieves state-of-the-art intra- and cross-scenario detection performance on benchmark datasets.
Learning Unknown Spoof Prompts for Generalized Face Anti-Spoofing Using Only Real Face Images
May 06, 2025



Face anti-spoofing is a critical technology for ensuring the security of face recognition systems. However, its ability to generalize across diverse scenarios remains a significant challenge. In this paper, we attribute the limited generalization ability to two key factors: covariate shift, which arises from external data collection variations, and semantic shift, which results from substantial differences in emerging attack types. To address both challenges, we propose a novel approach for learning unknown spoof prompts, relying solely on real face images from a single source domain. Our method generates textual prompts for real faces and potential unknown spoof attacks by leveraging the general knowledge embedded in vision-language models, thereby enhancing the model's ability to generalize to unseen target domains. Specifically, we introduce a diverse spoof prompt optimization framework to learn effective prompts. This framework constrains unknown spoof prompts within a relaxed prior knowledge space while maximizing their distance from real face images. Moreover, it enforces semantic independence among different spoof prompts to capture a broad range of spoof patterns. Experimental results on nine datasets demonstrate that the learned prompts effectively transfer the knowledge of vision-language models, enabling state-of-the-art generalization ability against diverse unknown attack types across unseen target domains without using any spoof face images.
MISE: Meta-knowledge Inheritance for Social Media-Based Stressor Estimation
May 03, 2025Stress haunts people in modern society, which may cause severe health issues if left unattended. With social media becoming an integral part of daily life, leveraging social media to detect stress has gained increasing attention. While the majority of the work focuses on classifying stress states and stress categories, this study introduce a new task aimed at estimating more specific stressors (like exam, writing paper, etc.) through users' posts on social media. Unfortunately, the diversity of stressors with many different classes but a few examples per class, combined with the consistent arising of new stressors over time, hinders the machine understanding of stressors. To this end, we cast the stressor estimation problem within a practical scenario few-shot learning setting, and propose a novel meta-learning based stressor estimation framework that is enhanced by a meta-knowledge inheritance mechanism. This model can not only learn generic stressor context through meta-learning, but also has a good generalization ability to estimate new stressors with little labeled data. A fundamental breakthrough in our approach lies in the inclusion of the meta-knowledge inheritance mechanism, which equips our model with the ability to prevent catastrophic forgetting when adapting to new stressors. The experimental results show that our model achieves state-of-the-art performance compared with the baselines. Additionally, we construct a social media-based stressor estimation dataset that can help train artificial intelligence models to facilitate human well-being. The dataset is now public at \href{https://www.kaggle.com/datasets/xinwangcs/stressor-cause-of-mental-health-problem-dataset}{\underline{Kaggle}} and \href{https://huggingface.co/datasets/XinWangcs/Stressor}{\underline{Hugging Face}}.
EIoU-EMC: A Novel Loss for Domain-specific Nested Entity Recognition
Apr 19, 2025In recent years, research has mainly focused on the general NER task. There still have some challenges with nested NER task in the specific domains. Specifically, the scenarios of low resource and class imbalance impede the wide application for biomedical and industrial domains. In this study, we design a novel loss EIoU-EMC, by enhancing the implement of Intersection over Union loss and Multiclass loss. Our proposed method specially leverages the information of entity boundary and entity classification, thereby enhancing the model's capacity to learn from a limited number of data samples. To validate the performance of this innovative method in enhancing NER task, we conducted experiments on three distinct biomedical NER datasets and one dataset constructed by ourselves from industrial complex equipment maintenance documents. Comparing to strong baselines, our method demonstrates the competitive performance across all datasets. During the experimental analysis, our proposed method exhibits significant advancements in entity boundary recognition and entity classification. Our code are available here.
TrafficLLM: Enhancing Large Language Models for Network Traffic Analysis with Generic Traffic Representation
Apr 05, 2025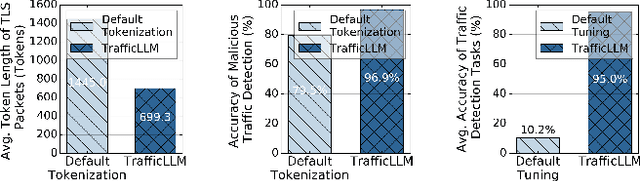
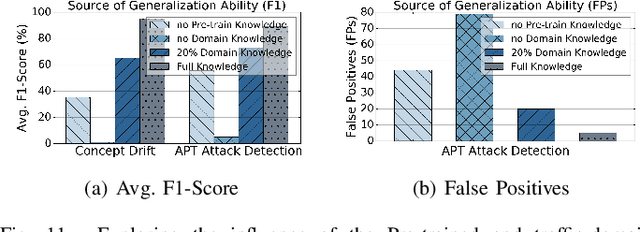
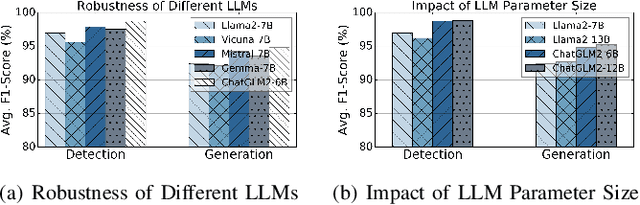
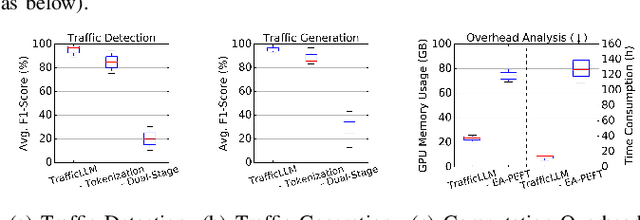
Machine learning (ML) powered network traffic analysis has been widely used for the purpose of threat detection. Unfortunately, their generalization across different tasks and unseen data is very limited. Large language models (LLMs), known for their strong generalization capabilities, have shown promising performance in various domains. However, their application to the traffic analysis domain is limited due to significantly different characteristics of network traffic. To address the issue, in this paper, we propose TrafficLLM, which introduces a dual-stage fine-tuning framework to learn generic traffic representation from heterogeneous raw traffic data. The framework uses traffic-domain tokenization, dual-stage tuning pipeline, and extensible adaptation to help LLM release generalization ability on dynamic traffic analysis tasks, such that it enables traffic detection and traffic generation across a wide range of downstream tasks. We evaluate TrafficLLM across 10 distinct scenarios and 229 types of traffic. TrafficLLM achieves F1-scores of 0.9875 and 0.9483, with up to 80.12% and 33.92% better performance than existing detection and generation methods. It also shows strong generalization on unseen traffic with an 18.6% performance improvement. We further evaluate TrafficLLM in real-world scenarios. The results confirm that TrafficLLM is easy to scale and achieves accurate detection performance on enterprise traffic.
Hawkeye:Efficient Reasoning with Model Collaboration
Apr 01, 2025Chain-of-Thought (CoT) reasoning has demonstrated remarkable effectiveness in enhancing the reasoning abilities of large language models (LLMs). However, its efficiency remains a challenge due to the generation of excessive intermediate reasoning tokens, which introduce semantic redundancy and overly detailed reasoning steps. Moreover, computational expense and latency are significant concerns, as the cost scales with the number of output tokens, including those intermediate steps. In this work, we observe that most CoT tokens are unnecessary, and retaining only a small portion of them is sufficient for producing high-quality responses. Inspired by this, we propose HAWKEYE, a novel post-training and inference framework where a large model produces concise CoT instructions to guide a smaller model in response generation. HAWKEYE quantifies redundancy in CoT reasoning and distills high-density information via reinforcement learning. By leveraging these concise CoTs, HAWKEYE is able to expand responses while reducing token usage and computational cost significantly. Our evaluation shows that HAWKEYE can achieve comparable response quality using only 35% of the full CoTs, while improving clarity, coherence, and conciseness by approximately 10%. Furthermore, HAWKEYE can accelerate end-to-end reasoning by up to 3.4x on complex math tasks while reducing inference cost by up to 60%. HAWKEYE will be open-sourced and the models will be available soon.
How to optimize K-means?
Mar 25, 2025Center-based clustering algorithms (e.g., K-means) are popular for clustering tasks, but they usually struggle to achieve high accuracy on complex datasets. We believe the main reason is that traditional center-based clustering algorithms identify only one clustering center in each cluster. Once the distribution of the dataset is complex, a single clustering center cannot strongly represent distant objects within the cluster. How to optimize the existing center-based clustering algorithms will be valuable research. In this paper, we propose a general optimization method called ECAC, and it can optimize different center-based clustering algorithms. ECAC is independent of the clustering principle and is embedded as a component between the center process and the category assignment process of center-based clustering algorithms. Specifically, ECAC identifies several extended-centers for each clustering center. The extended-centers will act as relays to expand the representative capability of the clustering center in the complex cluster, thus improving the accuracy of center-based clustering algorithms. We conducted numerous experiments to verify the robustness and effectiveness of ECAC. ECAC is robust to diverse datasets and diverse clustering centers. After ECAC optimization, the accuracy (NMI as well as RI) of center-based clustering algorithms improves by an average of 33.4% and 64.1%, respectively, and even K-means accurately identifies complex-shaped clusters.
VisualSimpleQA: A Benchmark for Decoupled Evaluation of Large Vision-Language Models in Fact-Seeking Question Answering
Mar 09, 2025Large vision-language models (LVLMs) have demonstrated remarkable achievements, yet the generation of non-factual responses remains prevalent in fact-seeking question answering (QA). Current multimodal fact-seeking benchmarks primarily focus on comparing model outputs to ground truth answers, providing limited insights into the performance of modality-specific modules. To bridge this gap, we introduce VisualSimpleQA, a multimodal fact-seeking benchmark with two key features. First, it enables streamlined and decoupled evaluation of LVLMs in visual and linguistic modalities. Second, it incorporates well-defined difficulty criteria to guide human annotation and facilitates the extraction of a challenging subset, VisualSimpleQA-hard. Experiments on 15 LVLMs show that even state-of-the-art models such as GPT-4o achieve merely 60%+ correctness in multimodal fact-seeking QA on VisualSimpleQA and 30%+ on VisualSimpleQA-hard. Furthermore, the decoupled evaluation across these models highlights substantial opportunities for improvement in both visual and linguistic modules. The dataset is available at https://huggingface.co/datasets/WYLing/VisualSimpleQA.
Multi-Level Collaboration in Model Merging
Mar 03, 2025Parameter-level model merging is an emerging paradigm in multi-task learning with significant promise. Previous research has explored its connections with prediction-level model ensembling-commonly viewed as the upper bound for merging-to reveal the potential of achieving performance consistency between the two. However, this observation relies on certain preconditions, such as being limited to two models, using ViT-based models, and all models are fine-tuned from the same pre-trained checkpoint. To further understand the intrinsic connections between model merging and model ensembling, this paper explores an interesting possibility: If these restrictions are removed, can performance consistency still be achieved between merging and ensembling? To answer this question, we first theoretically establish a performance correlation between merging and ensembling. We find that even when previous restrictions are not met, there is still a way for model merging to attain a near-identical and superior performance similar to that of ensembling. To verify whether our findings are practical, we introduce a validation framework termed Neural Ligand (NeuLig). The learning process of NeuLig is meticulously designed with a specialized loss function supported by theoretical foundations. Experimental results demonstrate the robust resilience of NeuLig in terms of both model scale and the number of collaborating models. For instance, for the case involving 5 CLIP-ViT-B/32 models, parameter-level merging achieves the same performance as prediction-level ensembling (merging: 95.44% vs. ensembling: 95.46%).