 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUT-ACA: Uncertainty-Triggered Adaptive Context Allocation for Long-Context Inference
Mar 19, 2026Long-context inference remains challenging for large language models due to attention dilution and out-of-distribution degradation. Context selection mitigates this limitation by attending to a subset of key-value cache entries, yet most methods allocate a fixed context budget throughout decoding despite highly non-uniform token-level contextual demands. To address this issue, we propose Uncertainty-Triggered Adaptive Context Allocation (UT-ACA), an inference-time framework that dynamically adjusts the context window based on token-wise uncertainty. UT-ACA learns an uncertainty detector that combines semantic embeddings with logit-based confidence while accounting for uncertainty accumulation across decoding steps. When insufficient evidence is indicated, UT-ACA selectively rolls back, expands the context window, and regenerates the token with additional support. Experiments show that UT-ACA substantially reduces average context usage while preserving generation quality in long-context settings.
ReViP: Reducing False Completion in Vision-Language-Action Models with Vision-Proprioception Rebalance
Jan 23, 2026Vision-Language-Action (VLA) models have advanced robotic manipulation by combining vision, language, and proprioception to predict actions. However, previous methods fuse proprioceptive signals directly with VLM-encoded vision-language features, resulting in state-dominant bias and false completions despite visible execution failures. We attribute this to modality imbalance, where policies over-rely on internal state while underusing visual evidence. To address this, we present ReViP, a novel VLA framework with Vision-Proprioception Rebalance to enhance visual grounding and robustness under perturbations. The key insight is to introduce auxiliary task-aware environment priors to adaptively modulate the coupling between semantic perception and proprioceptive dynamics. Specifically, we use an external VLM as a task-stage observer to extract real-time task-centric visual cues from visual observations, which drive a Vision-Proprioception Feature-wise Linear Modulation to enhance environmental awareness and reduce state-driven errors. Moreover, to evaluate false completion, we propose the first False-Completion Benchmark Suite built on LIBERO with controlled settings such as Object-Drop. Extensive experiments show that ReViP effectively reduces false-completion rates and improves success rates over strong VLA baselines on our suite, with gains extending to LIBERO, RoboTwin 2.0, and real-world evaluations.
Functional Consistency of LLM Code Embeddings: A Self-Evolving Data Synthesis Framework for Benchmarking
Aug 27, 2025Embedding models have demonstrated strong performance in tasks like clustering, retrieval, and feature extraction while offering computational advantages over generative models and cross-encoders. Benchmarks such as MTEB have shown that text embeddings from large language models (LLMs) capture rich semantic information, but their ability to reflect code-level functional semantics remains unclear. Existing studies largely focus on code clone detection, which emphasizes syntactic similarity and overlooks functional understanding. In this paper, we focus on the functional consistency of LLM code embeddings, which determines if two code snippets perform the same function regardless of syntactic differences. We propose a novel data synthesis framework called Functionality-Oriented Code Self-Evolution to construct diverse and challenging benchmarks. Specifically, we define code examples across four semantic and syntactic categories and find that existing datasets predominantly capture syntactic properties. Our framework generates four unique variations from a single code instance, providing a broader spectrum of code examples that better reflect functional differences. Extensive experiments on three downstream tasks-code clone detection, code functional consistency identification, and code retrieval-demonstrate that embedding models significantly improve their performance when trained on our evolved datasets. These results highlight the effectiveness and generalization of our data synthesis framework, advancing the functional understanding of code.
FSSUWNet: Mitigating the Fragility of Pre-trained Models with Feature Enhancement for Few-Shot Semantic Segmentation in Underwater Images
Apr 01, 2025



Few-Shot Semantic Segmentation (FSS), which focuses on segmenting new classes in images using only a limited number of annotated examples, has recently progressed in data-scarce domains. However, in this work, we show that the existing FSS methods often struggle to generalize to underwater environments. Specifically, the prior features extracted by pre-trained models used as feature extractors are fragile due to the unique challenges of underwater images. To address this, we propose FSSUWNet, a tailored FSS framework for underwater images with feature enhancement. FSSUWNet exploits the integration of complementary features, emphasizing both low-level and high-level image characteristics. In addition to employing a pre-trained model as the primary encoder, we propose an auxiliary encoder called Feature Enhanced Encoder which extracts complementary features to better adapt to underwater scene characteristics. Furthermore, a simple and effective Feature Alignment Module aims to provide global prior knowledge and align low-level features with high-level features in dimensions. Given the scarcity of underwater images, we introduce a cross-validation dataset version based on the Segmentation of Underwater Imagery dataset. Extensive experiments on public underwater segmentation datasets demonstrate that our approach achieves state-of-the-art performance. For example, our method outperforms the previous best method by 2.8% and 2.6% in terms of the mean Intersection over Union metric for 1-shot and 5-shot scenarios in the datasets, respectively. Our implementation is available at https://github.com/lizhh268/FSSUWNet.
Hawkeye:Efficient Reasoning with Model Collaboration
Apr 01, 2025Chain-of-Thought (CoT) reasoning has demonstrated remarkable effectiveness in enhancing the reasoning abilities of large language models (LLMs). However, its efficiency remains a challenge due to the generation of excessive intermediate reasoning tokens, which introduce semantic redundancy and overly detailed reasoning steps. Moreover, computational expense and latency are significant concerns, as the cost scales with the number of output tokens, including those intermediate steps. In this work, we observe that most CoT tokens are unnecessary, and retaining only a small portion of them is sufficient for producing high-quality responses. Inspired by this, we propose HAWKEYE, a novel post-training and inference framework where a large model produces concise CoT instructions to guide a smaller model in response generation. HAWKEYE quantifies redundancy in CoT reasoning and distills high-density information via reinforcement learning. By leveraging these concise CoTs, HAWKEYE is able to expand responses while reducing token usage and computational cost significantly. Our evaluation shows that HAWKEYE can achieve comparable response quality using only 35% of the full CoTs, while improving clarity, coherence, and conciseness by approximately 10%. Furthermore, HAWKEYE can accelerate end-to-end reasoning by up to 3.4x on complex math tasks while reducing inference cost by up to 60%. HAWKEYE will be open-sourced and the models will be available soon.
Lazarus: Resilient and Elastic Training of Mixture-of-Experts Models with Adaptive Expert Placement
Jul 05, 2024



Sparsely-activated Mixture-of-Experts (MoE) architecture has increasingly been adopted to further scale large language models (LLMs) due to its sub-linear scaling for computation costs. However, frequent failures still pose significant challenges as training scales. The cost of even a single failure is significant, as all GPUs need to wait idle until the failure is resolved, potentially losing considerable training progress as training has to restart from checkpoints. Existing solutions for efficient fault-tolerant training either lack elasticity or rely on building resiliency into pipeline parallelism, which cannot be applied to MoE models due to the expert parallelism strategy adopted by the MoE architecture. We present Lazarus, a system for resilient and elastic training of MoE models. Lazarus adaptively allocates expert replicas to address the inherent imbalance in expert workload and speeds-up training, while a provably optimal expert placement algorithm is developed to maximize the probability of recovery upon failures. Through adaptive expert placement and a flexible token dispatcher, Lazarus can also fully utilize all available nodes after failures, leaving no GPU idle. Our evaluation shows that Lazarus outperforms existing MoE training systems by up to 5.7x under frequent node failures and 3.4x on a real spot instance trace.
ShadowMaskFormer: Mask Augmented Patch Embeddings for Shadow Removal
Apr 30, 2024



Transformer recently emerged as the de facto model for computer vision tasks and has also been successfully applied to shadow removal. However, these existing methods heavily rely on intricate modifications to the attention mechanisms within the transformer blocks while using a generic patch embedding. As a result, it often leads to complex architectural designs requiring additional computation resources. In this work, we aim to explore the efficacy of incorporating shadow information within the early processing stage. Accordingly, we propose a transformer-based framework with a novel patch embedding that is tailored for shadow removal, dubbed ShadowMaskFormer. Specifically, we present a simple and effective mask-augmented patch embedding to integrate shadow information and promote the model's emphasis on acquiring knowledge for shadow regions. Extensive experiments conducted on the ISTD, ISTD+, and SRD benchmark datasets demonstrate the efficacy of our method against state-of-the-art approaches while using fewer model parameters.
RealNet: Combining Optimized Object Detection with Information Fusion Depth Estimation Co-Design Method on IoT
Apr 24, 2022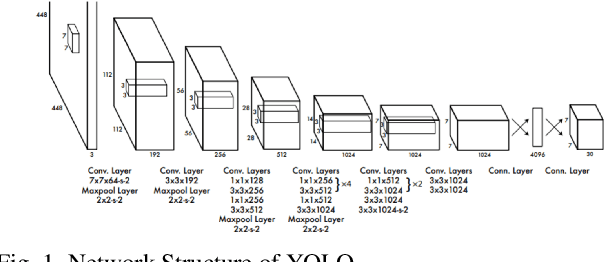

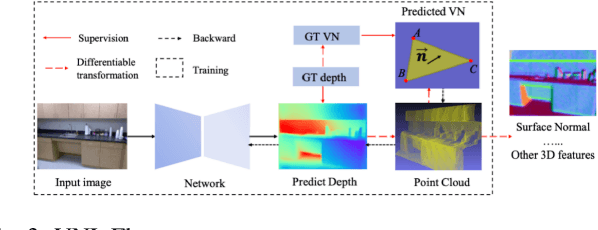

Depth Estimation and Object Detection Recognition play an important role in autonomous driving technology under the guidance of deep learning artificial intelligence. We propose a hybrid structure called RealNet: a co-design method combining the model-streamlined recognition algorithm, the depth estimation algorithm with information fusion, and deploying them on the Jetson-Nano for unmanned vehicles with monocular vision sensors. We use ROS for experiment. The method proposed in this paper is suitable for mobile platforms with high real-time request. Innovation of our method is using information fusion to compensate the problem of insufficient frame rate of output image, and improve the robustness of target detection and depth estimation under monocular vision.Object Detection is based on YOLO-v5. We have simplified the network structure of its DarkNet53 and realized a prediction speed up to 0.01s. Depth Estimation is based on the VNL Depth Estimation, which considers multiple geometric constraints in 3D global space. It calculates the loss function by calculating the deviation of the virtual normal vector VN and the label, which can obtain deeper depth information. We use PnP fusion algorithm to solve the problem of insufficient frame rate of depth map output. It solves the motion estimation depth from three-dimensional target to two-dimensional point based on corner feature matching, which is faster than VNL calculation. We interpolate VNL output and PnP output to achieve information fusion. Experiments show that this can effectively eliminate the jitter of depth information and improve robustness. At the control end, this method combines the results of target detection and depth estimation to calculate the target position, and uses a pure tracking control algorithm to track it.