 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMCIP: Protecting MCP Safety via Model Contextual Integrity Protocol
May 21, 2025As Model Context Protocol (MCP) introduces an easy-to-use ecosystem for users and developers, it also brings underexplored safety risks. Its decentralized architecture, which separates clients and servers, poses unique challenges for systematic safety analysis. This paper proposes a novel framework to enhance MCP safety. Guided by the MAESTRO framework, we first analyze the missing safety mechanisms in MCP, and based on this analysis, we propose the Model Contextual Integrity Protocol (MCIP), a refined version of MCP that addresses these gaps. Next, we develop a fine-grained taxonomy that captures a diverse range of unsafe behaviors observed in MCP scenarios. Building on this taxonomy, we develop benchmark and training data that support the evaluation and improvement of LLMs' capabilities in identifying safety risks within MCP interactions. Leveraging the proposed benchmark and training data, we conduct extensive experiments on state-of-the-art LLMs. The results highlight LLMs' vulnerabilities in MCP interactions and demonstrate that our approach substantially improves their safety performance.
Context Reasoner: Incentivizing Reasoning Capability for Contextualized Privacy and Safety Compliance via Reinforcement Learning
May 20, 2025While Large Language Models (LLMs) exhibit remarkable capabilities, they also introduce significant safety and privacy risks. Current mitigation strategies often fail to preserve contextual reasoning capabilities in risky scenarios. Instead, they rely heavily on sensitive pattern matching to protect LLMs, which limits the scope. Furthermore, they overlook established safety and privacy standards, leading to systemic risks for legal compliance. To address these gaps, we formulate safety and privacy issues into contextualized compliance problems following the Contextual Integrity (CI) theory. Under the CI framework, we align our model with three critical regulatory standards: GDPR, EU AI Act, and HIPAA. Specifically, we employ reinforcement learning (RL) with a rule-based reward to incentivize contextual reasoning capabilities while enhancing compliance with safety and privacy norms. Through extensive experiments, we demonstrate that our method not only significantly enhances legal compliance (achieving a +17.64% accuracy improvement in safety/privacy benchmarks) but also further improves general reasoning capability. For OpenThinker-7B, a strong reasoning model that significantly outperforms its base model Qwen2.5-7B-Instruct across diverse subjects, our method enhances its general reasoning capabilities, with +2.05% and +8.98% accuracy improvement on the MMLU and LegalBench benchmark, respectively.
A Provably Convergent Plug-and-Play Framework for Stochastic Bilevel Optimization
May 02, 2025Bilevel optimization has recently attracted significant attention in machine learning due to its wide range of applications and advanced hierarchical optimization capabilities. In this paper, we propose a plug-and-play framework, named PnPBO, for developing and analyzing stochastic bilevel optimization methods. This framework integrates both modern unbiased and biased stochastic estimators into the single-loop bilevel optimization framework introduced in [9], with several improvements. In the implementation of PnPBO, all stochastic estimators for different variables can be independently incorporated, and an additional moving average technique is applied when using an unbiased estimator for the upper-level variable. In the theoretical analysis, we provide a unified convergence and complexity analysis for PnPBO, demonstrating that the adaptation of various stochastic estimators (including PAGE, ZeroSARAH, and mixed strategies) within the PnPBO framework achieves optimal sample complexity, comparable to that of single-level optimization. This resolves the open question of whether the optimal complexity bounds for solving bilevel optimization are identical to those for single-level optimization. Finally, we empirically validate our framework, demonstrating its effectiveness on several benchmark problems and confirming our theoretical findings.
PrivaCI-Bench: Evaluating Privacy with Contextual Integrity and Legal Compliance
Feb 24, 2025Recent advancements in generative large language models (LLMs) have enabled wider applicability, accessibility, and flexibility. However, their reliability and trustworthiness are still in doubt, especially for concerns regarding individuals' data privacy. Great efforts have been made on privacy by building various evaluation benchmarks to study LLMs' privacy awareness and robustness from their generated outputs to their hidden representations. Unfortunately, most of these works adopt a narrow formulation of privacy and only investigate personally identifiable information (PII). In this paper, we follow the merit of the Contextual Integrity (CI) theory, which posits that privacy evaluation should not only cover the transmitted attributes but also encompass the whole relevant social context through private information flows. We present PrivaCI-Bench, a comprehensive contextual privacy evaluation benchmark targeted at legal compliance to cover well-annotated privacy and safety regulations, real court cases, privacy policies, and synthetic data built from the official toolkit to study LLMs' privacy and safety compliance. We evaluate the latest LLMs, including the recent reasoner models QwQ-32B and Deepseek R1. Our experimental results suggest that though LLMs can effectively capture key CI parameters inside a given context, they still require further advancements for privacy compliance.
Privacy Checklist: Privacy Violation Detection Grounding on Contextual Integrity Theory
Aug 19, 2024



Privacy research has attracted wide attention as individuals worry that their private data can be easily leaked during interactions with smart devices, social platforms, and AI applications. Computer science researchers, on the other hand, commonly study privacy issues through privacy attacks and defenses on segmented fields. Privacy research is conducted on various sub-fields, including Computer Vision (CV), Natural Language Processing (NLP), and Computer Networks. Within each field, privacy has its own formulation. Though pioneering works on attacks and defenses reveal sensitive privacy issues, they are narrowly trapped and cannot fully cover people's actual privacy concerns. Consequently, the research on general and human-centric privacy research remains rather unexplored. In this paper, we formulate the privacy issue as a reasoning problem rather than simple pattern matching. We ground on the Contextual Integrity (CI) theory which posits that people's perceptions of privacy are highly correlated with the corresponding social context. Based on such an assumption, we develop the first comprehensive checklist that covers social identities, private attributes, and existing privacy regulations. Unlike prior works on CI that either cover limited expert annotated norms or model incomplete social context, our proposed privacy checklist uses the whole Health Insurance Portability and Accountability Act of 1996 (HIPAA) as an example, to show that we can resort to large language models (LLMs) to completely cover the HIPAA's regulations. Additionally, our checklist also gathers expert annotations across multiple ontologies to determine private information including but not limited to personally identifiable information (PII). We use our preliminary results on the HIPAA to shed light on future context-centric privacy research to cover more privacy regulations, social norms and standards.
SPABA: A Single-Loop and Probabilistic Stochastic Bilevel Algorithm Achieving Optimal Sample Complexity
May 29, 2024While stochastic bilevel optimization methods have been extensively studied for addressing large-scale nested optimization problems in machine learning, it remains an open question whether the optimal complexity bounds for solving bilevel optimization are the same as those in single-level optimization. Our main result resolves this question: SPABA, an adaptation of the PAGE method for nonconvex optimization in (Li et al., 2021) to the bilevel setting, can achieve optimal sample complexity in both the finite-sum and expectation settings. We show the optimality of SPABA by proving that there is no gap in complexity analysis between stochastic bilevel and single-level optimization when implementing PAGE. Notably, as indicated by the results of (Dagr\'eou et al., 2022), there might exist a gap in complexity analysis when implementing other stochastic gradient estimators, like SGD and SAGA. In addition to SPABA, we propose several other single-loop stochastic bilevel algorithms, that either match or improve the state-of-the-art sample complexity results, leveraging our convergence rate and complexity analysis. Numerical experiments demonstrate the superior practical performance of the proposed methods.
Predicting Depression and Anxiety: A Multi-Layer Perceptron for Analyzing the Mental Health Impact of COVID-19
Mar 09, 2024



We introduce a multi-layer perceptron (MLP) called the COVID-19 Depression and Anxiety Predictor (CoDAP) to predict mental health trends, particularly anxiety and depression, during the COVID-19 pandemic. Our method utilizes a comprehensive dataset, which tracked mental health symptoms weekly over ten weeks during the initial COVID-19 wave (April to June 2020) in a diverse cohort of U.S. adults. This period, characterized by a surge in mental health symptoms and conditions, offers a critical context for our analysis. Our focus was to extract and analyze patterns of anxiety and depression through a unique lens of qualitative individual attributes using CoDAP. This model not only predicts patterns of anxiety and depression during the pandemic but also unveils key insights into the interplay of demographic factors, behavioral changes, and social determinants of mental health. These findings contribute to a more nuanced understanding of the complexity of mental health issues in times of global health crises, potentially guiding future early interventions.
Energy-Efficient Power Control for Multiple-Task Split Inference in UAVs: A Tiny Learning-Based Approach
Dec 31, 2023The limited energy and computing resources of unmanned aerial vehicles (UAVs) hinder the application of aerial artificial intelligence. The utilization of split inference in UAVs garners significant attention due to its effectiveness in mitigating computing and energy requirements. However, achieving energy-efficient split inference in UAVs remains complex considering of various crucial parameters such as energy level and delay constraints, especially involving multiple tasks. In this paper, we present a two-timescale approach for energy minimization in split inference, where discrete and continuous variables are segregated into two timescales to reduce the size of action space and computational complexity. This segregation enables the utilization of tiny reinforcement learning (TRL) for selecting discrete transmission modes for sequential tasks. Moreover, optimization programming (OP) is embedded between TRL's output and reward function to optimize the continuous transmit power. Specifically, we replace the optimization of transmit power with that of transmission time to decrease the computational complexity of OP since we reveal that energy consumption monotonically decreases with increasing transmission time. The replacement significantly reduces the feasible region and enables a fast solution according to the closed-form expression for optimal transmit power. Simulation results show that the proposed algorithm can achieve a higher probability of successful task completion with lower energy consumption.
Eliminating Prior Bias for Semantic Image Editing via Dual-Cycle Diffusion
Feb 07, 2023The recent success of text-to-image generation diffusion models has also revolutionized semantic image editing, enabling the manipulation of images based on query/target texts. Despite these advancements, a significant challenge lies in the potential introduction of prior bias in pre-trained models during image editing, e.g., making unexpected modifications to inappropriate regions. To this point, we present a novel Dual-Cycle Diffusion model that addresses the issue of prior bias by generating an unbiased mask as the guidance of image editing. The proposed model incorporates a Bias Elimination Cycle that consists of both a forward path and an inverted path, each featuring a Structural Consistency Cycle to ensure the preservation of image content during the editing process. The forward path utilizes the pre-trained model to produce the edited image, while the inverted path converts the result back to the source image. The unbiased mask is generated by comparing differences between the processed source image and the edited image to ensure that both conform to the same distribution. Our experiments demonstrate the effectiveness of the proposed method, as it significantly improves the D-CLIP score from 0.272 to 0.283. The code will be available at https://github.com/JohnDreamer/DualCycleDiffsion.
Multi-agent Reinforcement Learning for Networked System Control
Apr 24, 2020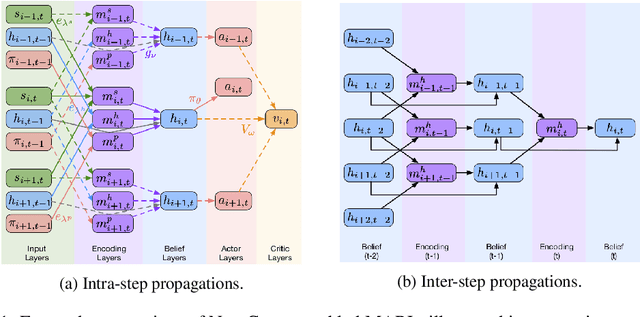

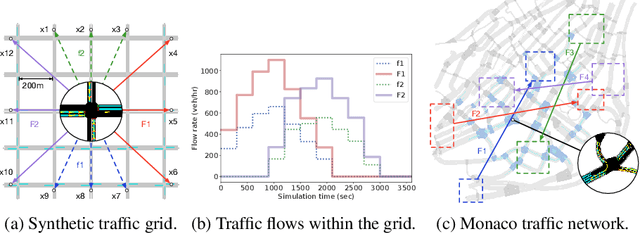

This paper considers multi-agent reinforcement learning (MARL) in networked system control. Specifically, each agent learns a decentralized control policy based on local observations and messages from connected neighbors. We formulate such a networked MARL (NMARL) problem as a spatiotemporal Markov decision process and introduce a spatial discount factor to stabilize the training of each local agent. Further, we propose a new differentiable communication protocol, called NeurComm, to reduce information loss and non-stationarity in NMARL. Based on experiments in realistic NMARL scenarios of adaptive traffic signal control and cooperative adaptive cruise control, an appropriate spatial discount factor effectively enhances the learning curves of non-communicative MARL algorithms, while NeurComm outperforms existing communication protocols in both learning efficiency and control performance.