 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQi Dou
Future Frame Prediction for Robot-assisted Surgery
Mar 18, 2021
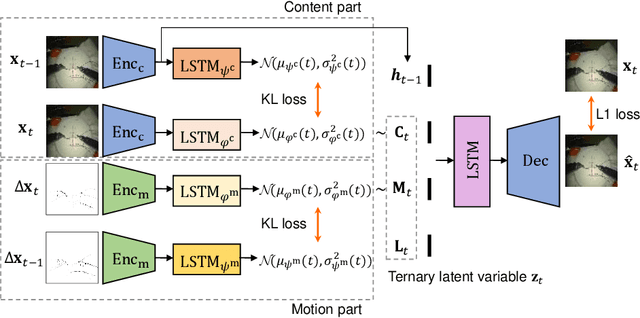
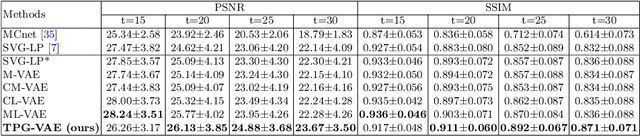

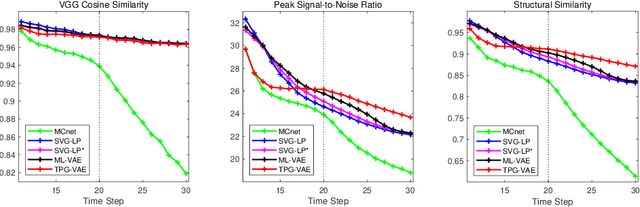
Predicting future frames for robotic surgical video is an interesting, important yet extremely challenging problem, given that the operative tasks may have complex dynamics. Existing approaches on future prediction of natural videos were based on either deterministic models or stochastic models, including deep recurrent neural networks, optical flow, and latent space modeling. However, the potential in predicting meaningful movements of robots with dual arms in surgical scenarios has not been tapped so far, which is typically more challenging than forecasting independent motions of one arm robots in natural scenarios. In this paper, we propose a ternary prior guided variational autoencoder (TPG-VAE) model for future frame prediction in robotic surgical video sequences. Besides content distribution, our model learns motion distribution, which is novel to handle the small movements of surgical tools. Furthermore, we add the invariant prior information from the gesture class into the generation process to constrain the latent space of our model. To our best knowledge, this is the first time that the future frames of dual arm robots are predicted considering their unique characteristics relative to general robotic videos. Experiments demonstrate that our model gains more stable and realistic future frame prediction scenes with the suturing task on the public JIGSAWS dataset.
Trans-SVNet: Accurate Phase Recognition from Surgical Videos via Hybrid Embedding Aggregation Transformer
Mar 17, 2021
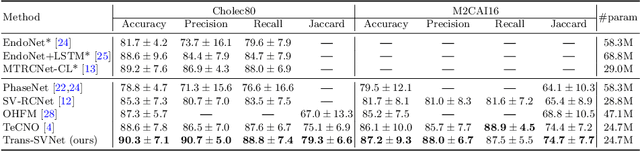
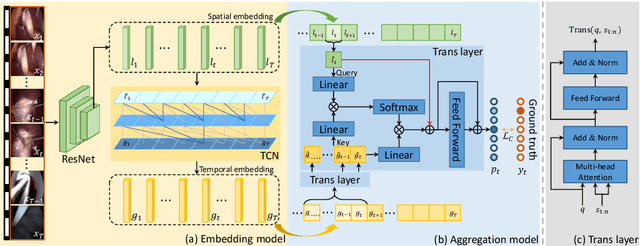

Real-time surgical phase recognition is a fundamental task in modern operating rooms. Previous works tackle this task relying on architectures arranged in spatio-temporal order, however, the supportive benefits of intermediate spatial features are not considered. In this paper, we introduce, for the first time in surgical workflow analysis, Transformer to reconsider the ignored complementary effects of spatial and temporal features for accurate surgical phase recognition. Our hybrid embedding aggregation Transformer fuses cleverly designed spatial and temporal embeddings by allowing for active queries based on spatial information from temporal embedding sequences. More importantly, our framework is lightweight and processes the hybrid embeddings in parallel to achieve a high inference speed. Our method is thoroughly validated on two large surgical video datasets, i.e., Cholec80 and M2CAI16 Challenge datasets, and significantly outperforms the state-of-the-art approaches at a processing speed of 91 fps.
FedDG: Federated Domain Generalization on Medical Image Segmentation via Episodic Learning in Continuous Frequency Space
Mar 10, 2021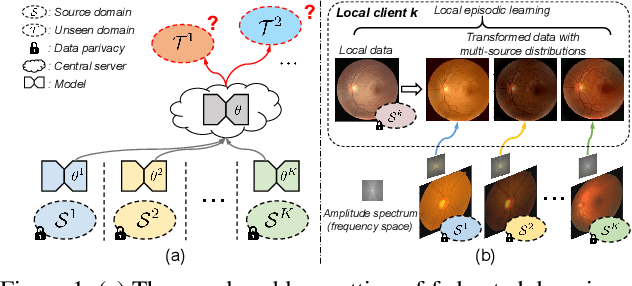
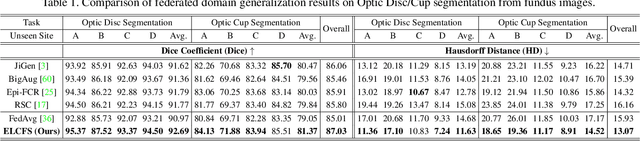
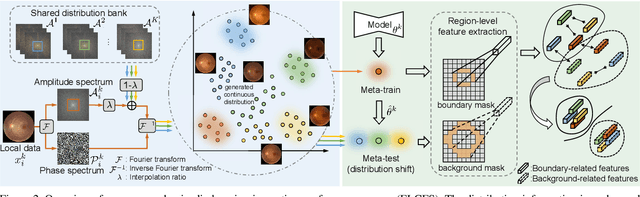
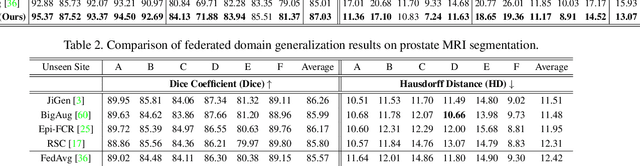
Federated learning allows distributed medical institutions to collaboratively learn a shared prediction model with privacy protection. While at clinical deployment, the models trained in federated learning can still suffer from performance drop when applied to completely unseen hospitals outside the federation. In this paper, we point out and solve a novel problem setting of federated domain generalization (FedDG), which aims to learn a federated model from multiple distributed source domains such that it can directly generalize to unseen target domains. We present a novel approach, named as Episodic Learning in Continuous Frequency Space (ELCFS), for this problem by enabling each client to exploit multi-source data distributions under the challenging constraint of data decentralization. Our approach transmits the distribution information across clients in a privacy-protecting way through an effective continuous frequency space interpolation mechanism. With the transferred multi-source distributions, we further carefully design a boundary-oriented episodic learning paradigm to expose the local learning to domain distribution shifts and particularly meet the challenges of model generalization in medical image segmentation scenario. The effectiveness of our method is demonstrated with superior performance over state-of-the-arts and in-depth ablation experiments on two medical image segmentation tasks. The code is available at "https://github.com/liuquande/FedDG-ELCFS".
Domain Adaptive Robotic Gesture Recognition with Unsupervised Kinematic-Visual Data Alignment
Mar 06, 2021
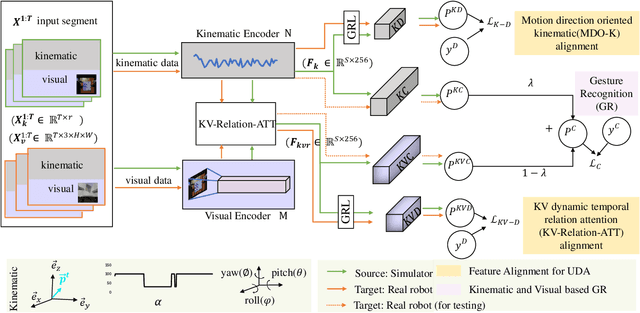
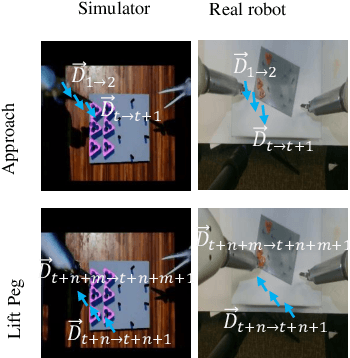
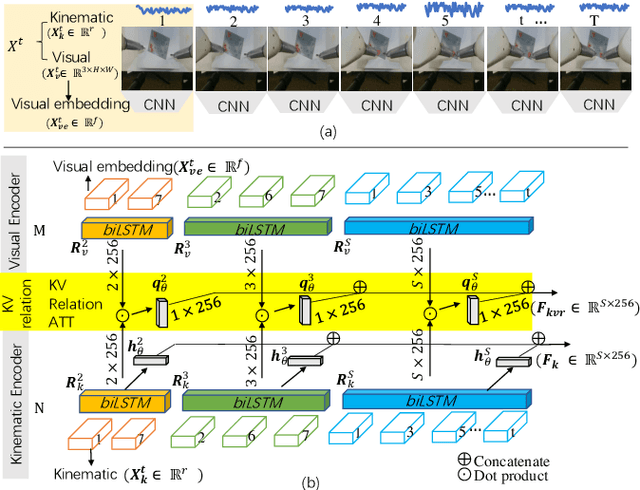
Automated surgical gesture recognition is of great importance in robot-assisted minimally invasive surgery. However, existing methods assume that training and testing data are from the same domain, which suffers from severe performance degradation when a domain gap exists, such as the simulator and real robot. In this paper, we propose a novel unsupervised domain adaptation framework which can simultaneously transfer multi-modality knowledge, i.e., both kinematic and visual data, from simulator to real robot. It remedies the domain gap with enhanced transferable features by using temporal cues in videos, and inherent correlations in multi-modal towards recognizing gesture. Specifically, we first propose an MDO-K to align kinematics, which exploits temporal continuity to transfer motion directions with smaller gap rather than position values, relieving the adaptation burden. Moreover, we propose a KV-Relation-ATT to transfer the co-occurrence signals of kinematics and vision. Such features attended by correlation similarity are more informative for enhancing domain-invariance of the model. Two feature alignment strategies benefit the model mutually during the end-to-end learning process. We extensively evaluate our method for gesture recognition using DESK dataset with peg transfer procedure. Results show that our approach recovers the performance with great improvement gains, up to 12.91% in ACC and 20.16% in F1score without using any annotations in real robot.
FedBN: Federated Learning on Non-IID Features via Local Batch Normalization
Feb 15, 2021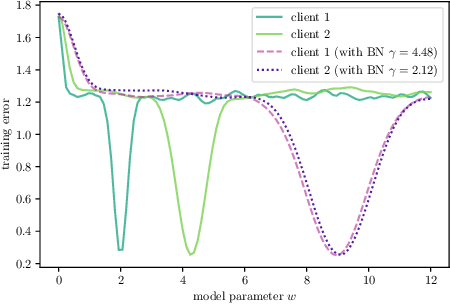
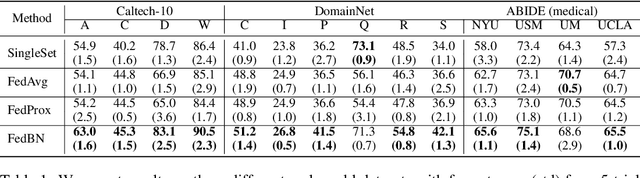
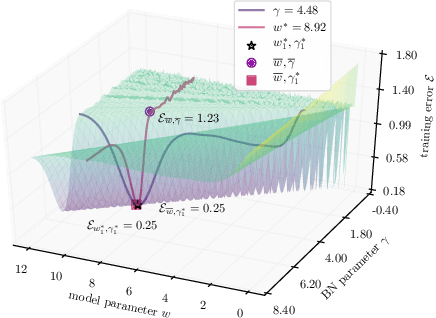

The emerging paradigm of federated learning (FL) strives to enable collaborative training of deep models on the network edge without centrally aggregating raw data and hence improving data privacy. In most cases, the assumption of independent and identically distributed samples across local clients does not hold for federated learning setups. Under this setting, neural network training performance may vary significantly according to the data distribution and even hurt training convergence. Most of the previous work has focused on a difference in the distribution of labels or client shifts. Unlike those settings, we address an important problem of FL, e.g., different scanners/sensors in medical imaging, different scenery distribution in autonomous driving (highway vs. city), where local clients store examples with different distributions compared to other clients, which we denote as feature shift non-iid. In this work, we propose an effective method that uses local batch normalization to alleviate the feature shift before averaging models. The resulting scheme, called FedBN, outperforms both classical FedAvg, as well as the state-of-the-art for non-iid data (FedProx) on our extensive experiments. These empirical results are supported by a convergence analysis that shows in a simplified setting that FedBN has a faster convergence rate than FedAvg. Code is available at https://github.com/med-air/FedBN.
Data-driven Holistic Framework for Automated Laparoscope Optimal View Control with Learning-based Depth Perception
Nov 23, 2020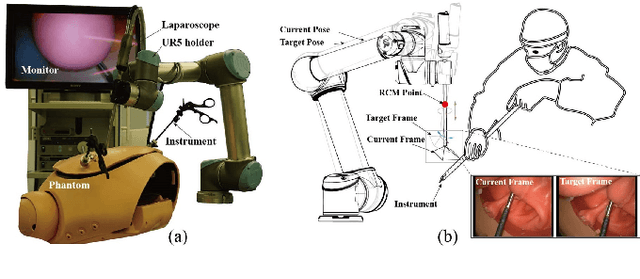
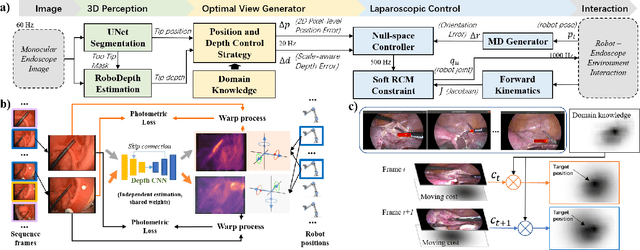
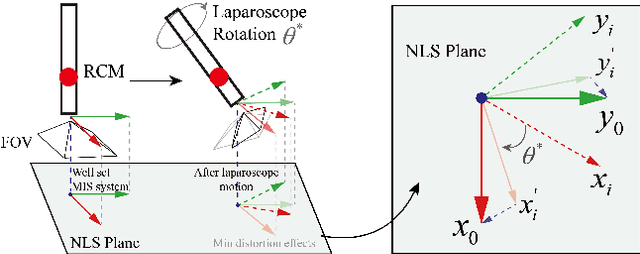
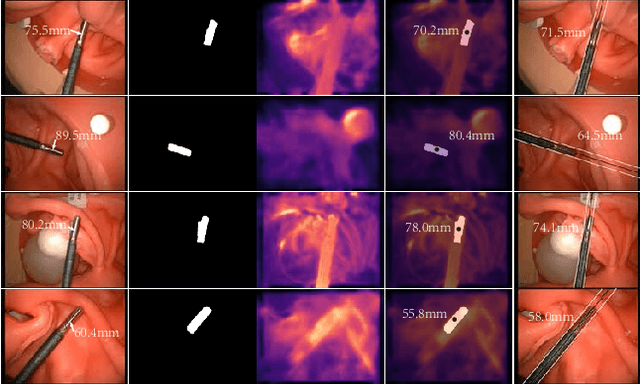
Laparoscopic Field of View (FOV) control is one of the most fundamental and important components in Minimally Invasive Surgery (MIS), nevertheless, the traditional manual holding paradigm may easily bring fatigue to surgical assistants, and misunderstanding between surgeons also hinders assistants to provide a high-quality FOV. Targeting this problem, we here present a data-driven framework to realize an automated laparoscopic optimal FOV control. To achieve this goal, we offline learn a motion strategy of laparoscope relative to the surgeon's hand-held surgical tool from our in-house surgical videos, developing our control domain knowledge and an optimal view generator. To adjust the laparoscope online, we first adopt a learning-based method to segment the two-dimensional (2D) position of the surgical tool, and further leverage this outcome to obtain its scale-aware depth from dense depth estimation results calculated by our novel unsupervised RoboDepth model only with the monocular camera feedback, hence in return fusing the above real-time 3D position into our control loop. To eliminate the misorientation of FOV caused by Remote Center of Motion (RCM) constraints when moving the laparoscope, we propose a novel distortion constraint using an affine map to minimize the visual warping problem, and a null-space controller is also embedded into the framework to optimize all types of errors in a unified and decoupled manner. Experiments are conducted using Universal Robot (UR) and Karl Storz Laparoscope/Instruments, which prove the feasibility of our domain knowledge and learning enabled framework for automated camera control.
Relational Graph Learning on Visual and Kinematics Embeddings for Accurate Gesture Recognition in Robotic Surgery
Nov 03, 2020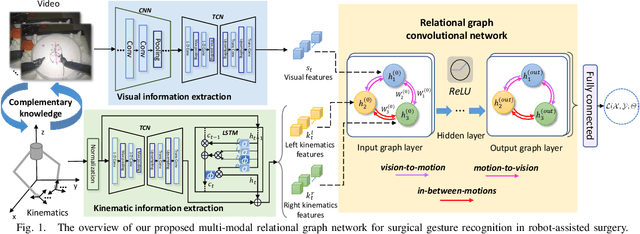
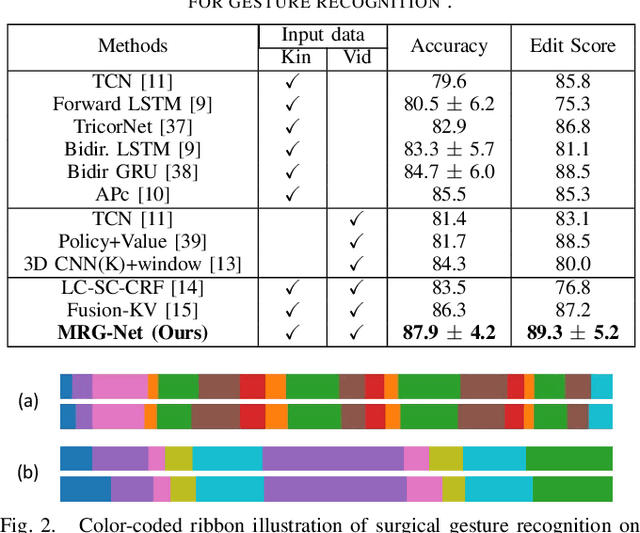
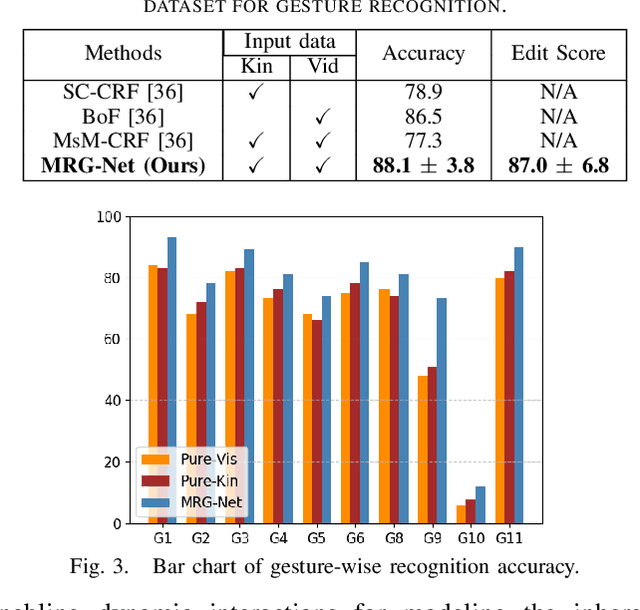

Automatic surgical gesture recognition is fundamentally important to enable intelligent cognitive assistance in robotic surgery. With recent advancement in robot-assisted minimally invasive surgery, rich information including surgical videos and robotic kinematics can be recorded, which provide complementary knowledge for understanding surgical gestures. However, existing methods either solely adopt uni-modal data or directly concatenate multi-modal representations, which can not sufficiently exploit the informative correlations inherent in visual and kinematics data to boost gesture recognition accuracies. In this regard, we propose a novel approach of multimodal relational graph network (i.e., MRG-Net) to dynamically integrate visual and kinematics information through interactive message propagation in the latent feature space. In specific, we first extract embeddings from video and kinematics sequences with temporal convolutional networks and LSTM units. Next, we identify multi-relations in these multi-modal features and model them through a hierarchical relational graph learning module. The effectiveness of our method is demonstrated with state-of-the-art results on the public JIGSAWS dataset, outperforming current uni-modal and multi-modal methods on both suturing and knot typing tasks. Furthermore, we validated our method on in-house visual-kinematics datasets collected with da Vinci Research Kit (dVRK) platforms in two centers, with consistent promising performance achieved.
Contrastive Cross-site Learning with Redesigned Net for COVID-19 CT Classification
Sep 15, 2020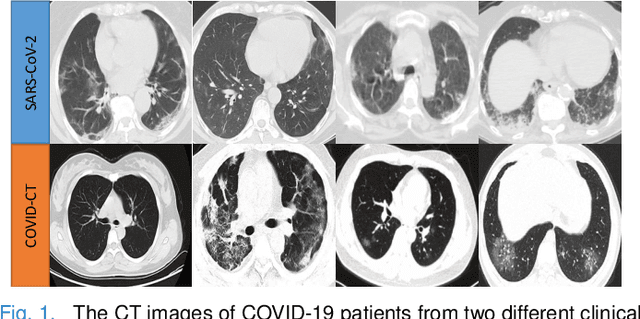
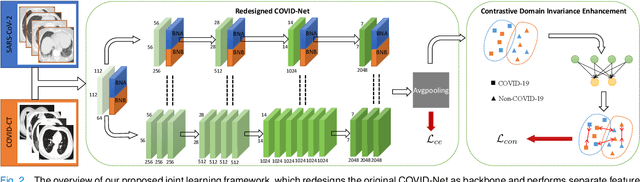
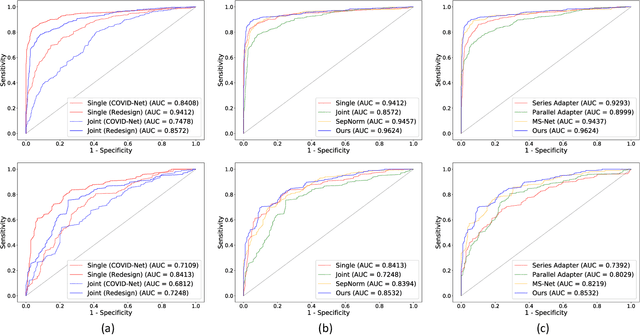
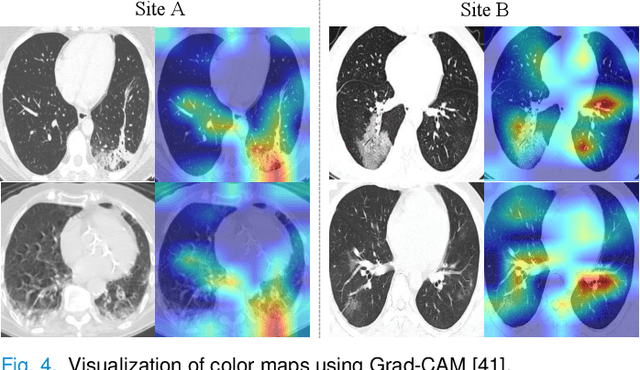
The pandemic of coronavirus disease 2019 (COVID-19) has lead to a global public health crisis spreading hundreds of countries. With the continuous growth of new infections, developing automated tools for COVID-19 identification with CT image is highly desired to assist the clinical diagnosis and reduce the tedious workload of image interpretation. To enlarge the datasets for developing machine learning methods, it is essentially helpful to aggregate the cases from different medical systems for learning robust and generalizable models. This paper proposes a novel joint learning framework to perform accurate COVID-19 identification by effectively learning with heterogeneous datasets with distribution discrepancy. We build a powerful backbone by redesigning the recently proposed COVID-Net in aspects of network architecture and learning strategy to improve the prediction accuracy and learning efficiency. On top of our improved backbone, we further explicitly tackle the cross-site domain shift by conducting separate feature normalization in latent space. Moreover, we propose to use a contrastive training objective to enhance the domain invariance of semantic embeddings for boosting the classification performance on each dataset. We develop and evaluate our method with two public large-scale COVID-19 diagnosis datasets made up of CT images. Extensive experiments show that our approach consistently improves the performances on both datasets, outperforming the original COVID-Net trained on each dataset by 12.16% and 14.23% in AUC respectively, also exceeding existing state-of-the-art multi-site learning methods.
Multi-Site Infant Brain Segmentation Algorithms: The iSeg-2019 Challenge
Jul 11, 2020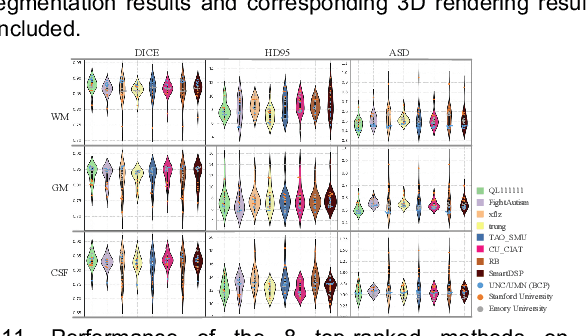
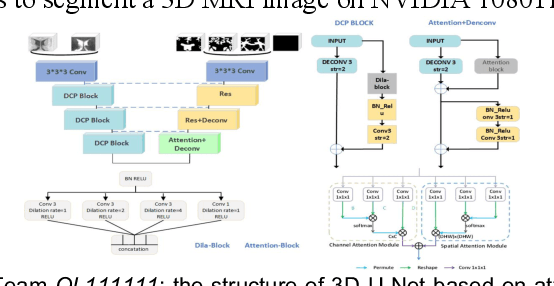
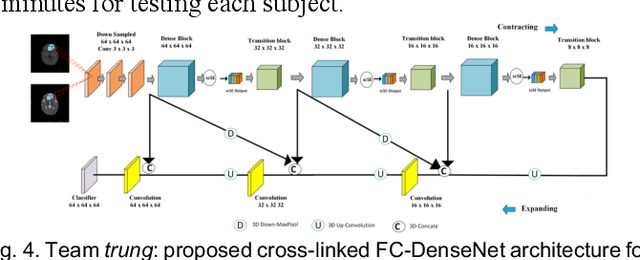
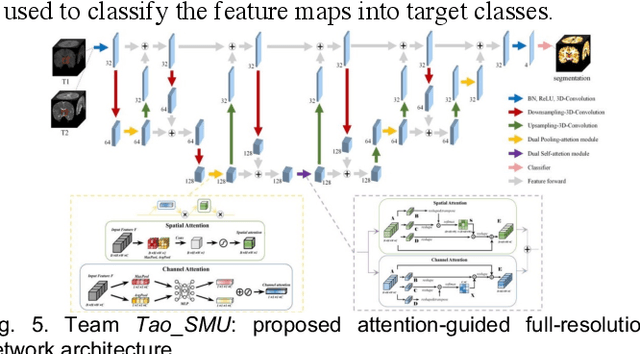
To better understand early brain growth patterns in health and disorder, it is critical to accurately segment infant brain magnetic resonance (MR) images into white matter (WM), gray matter (GM), and cerebrospinal fluid (CSF). Deep learning-based methods have achieved state-of-the-art performance; however, one of major limitations is that the learning-based methods may suffer from the multi-site issue, that is, the models trained on a dataset from one site may not be applicable to the datasets acquired from other sites with different imaging protocols/scanners. To promote methodological development in the community, iSeg-2019 challenge (http://iseg2019.web.unc.edu) provides a set of 6-month infant subjects from multiple sites with different protocols/scanners for the participating methods. Training/validation subjects are from UNC (MAP) and testing subjects are from UNC/UMN (BCP), Stanford University, and Emory University. By the time of writing, there are 30 automatic segmentation methods participating in iSeg-2019. We review the 8 top-ranked teams by detailing their pipelines/implementations, presenting experimental results and evaluating performance in terms of the whole brain, regions of interest, and gyral landmark curves. We also discuss their limitations and possible future directions for the multi-site issue. We hope that the multi-site dataset in iSeg-2019 and this review article will attract more researchers on the multi-site issue.
Learning Motion Flows for Semi-supervised Instrument Segmentation from Robotic Surgical Video
Jul 06, 2020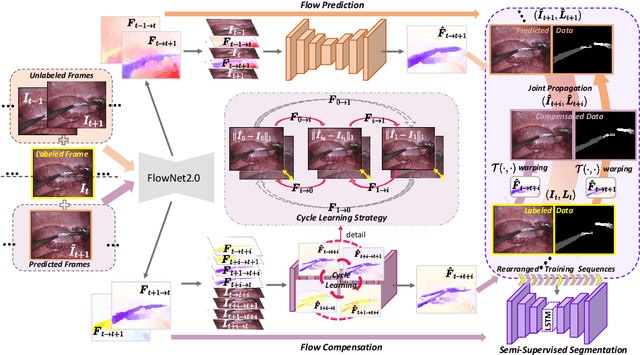
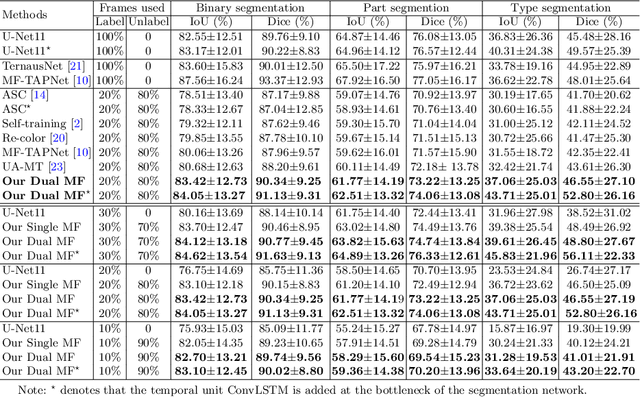
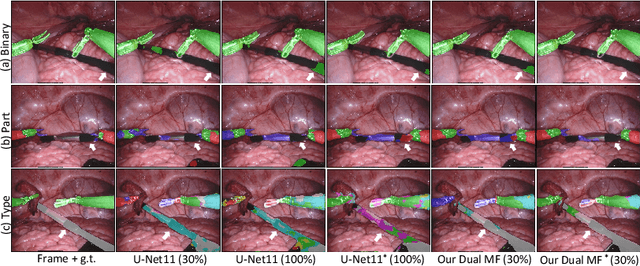
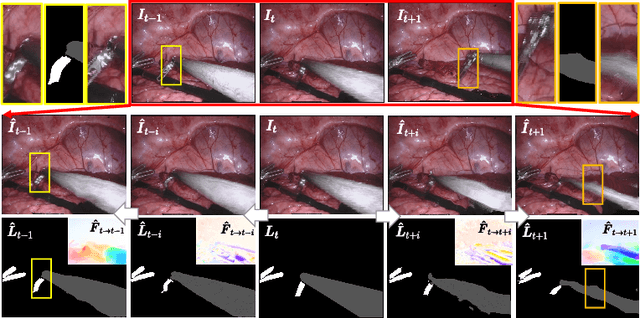
Performing low hertz labeling for surgical videos at intervals can greatly releases the burden of surgeons. In this paper, we study the semi-supervised instrument segmentation from robotic surgical videos with sparse annotations. Unlike most previous methods using unlabeled frames individually, we propose a dual motion based method to wisely learn motion flows for segmentation enhancement by leveraging temporal dynamics. We firstly design a flow predictor to derive the motion for jointly propagating the frame-label pairs given the current labeled frame. Considering the fast instrument motion, we further introduce a flow compensator to estimate intermediate motion within continuous frames, with a novel cycle learning strategy. By exploiting generated data pairs, our framework can recover and even enhance temporal consistency of training sequences to benefit segmentation. We validate our framework with binary, part, and type tasks on 2017 MICCAI EndoVis Robotic Instrument Segmentation Challenge dataset. Results show that our method outperforms the state-of-the-art semi-supervised methods by a large margin, and even exceeds fully supervised training on two tasks.