 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeU2-BENCH: Benchmarking Large Vision-Language Models on Ultrasound Understanding
May 23, 2025Ultrasound is a widely-used imaging modality critical to global healthcare, yet its interpretation remains challenging due to its varying image quality on operators, noises, and anatomical structures. Although large vision-language models (LVLMs) have demonstrated impressive multimodal capabilities across natural and medical domains, their performance on ultrasound remains largely unexplored. We introduce U2-BENCH, the first comprehensive benchmark to evaluate LVLMs on ultrasound understanding across classification, detection, regression, and text generation tasks. U2-BENCH aggregates 7,241 cases spanning 15 anatomical regions and defines 8 clinically inspired tasks, such as diagnosis, view recognition, lesion localization, clinical value estimation, and report generation, across 50 ultrasound application scenarios. We evaluate 20 state-of-the-art LVLMs, both open- and closed-source, general-purpose and medical-specific. Our results reveal strong performance on image-level classification, but persistent challenges in spatial reasoning and clinical language generation. U2-BENCH establishes a rigorous and unified testbed to assess and accelerate LVLM research in the uniquely multimodal domain of medical ultrasound imaging.
Local Superior Soups: A Catalyst for Model Merging in Cross-Silo Federated Learning
Oct 31, 2024



Federated learning (FL) is a learning paradigm that enables collaborative training of models using decentralized data. Recently, the utilization of pre-trained weight initialization in FL has been demonstrated to effectively improve model performance. However, the evolving complexity of current pre-trained models, characterized by a substantial increase in parameters, markedly intensifies the challenges associated with communication rounds required for their adaptation to FL. To address these communication cost issues and increase the performance of pre-trained model adaptation in FL, we propose an innovative model interpolation-based local training technique called ``Local Superior Soups.'' Our method enhances local training across different clients, encouraging the exploration of a connected low-loss basin within a few communication rounds through regularized model interpolation. This approach acts as a catalyst for the seamless adaptation of pre-trained models in in FL. We demonstrated its effectiveness and efficiency across diverse widely-used FL datasets. Our code is available at \href{https://github.com/ubc-tea/Local-Superior-Soups}{https://github.com/ubc-tea/Local-Superior-Soups}.
Client-Level Differential Privacy via Adaptive Intermediary in Federated Medical Imaging
Jul 24, 2023



Despite recent progress in enhancing the privacy of federated learning (FL) via differential privacy (DP), the trade-off of DP between privacy protection and performance is still underexplored for real-world medical scenario. In this paper, we propose to optimize the trade-off under the context of client-level DP, which focuses on privacy during communications. However, FL for medical imaging involves typically much fewer participants (hospitals) than other domains (e.g., mobile devices), thus ensuring clients be differentially private is much more challenging. To tackle this problem, we propose an adaptive intermediary strategy to improve performance without harming privacy. Specifically, we theoretically find splitting clients into sub-clients, which serve as intermediaries between hospitals and the server, can mitigate the noises introduced by DP without harming privacy. Our proposed approach is empirically evaluated on both classification and segmentation tasks using two public datasets, and its effectiveness is demonstrated with significant performance improvements and comprehensive analytical studies. Code is available at: https://github.com/med-air/Client-DP-FL.
FedSoup: Improving Generalization and Personalization in Federated Learning via Selective Model Interpolation
Jul 20, 2023



Cross-silo federated learning (FL) enables the development of machine learning models on datasets distributed across data centers such as hospitals and clinical research laboratories. However, recent research has found that current FL algorithms face a trade-off between local and global performance when confronted with distribution shifts. Specifically, personalized FL methods have a tendency to overfit to local data, leading to a sharp valley in the local model and inhibiting its ability to generalize to out-of-distribution data. In this paper, we propose a novel federated model soup method (i.e., selective interpolation of model parameters) to optimize the trade-off between local and global performance. Specifically, during the federated training phase, each client maintains its own global model pool by monitoring the performance of the interpolated model between the local and global models. This allows us to alleviate overfitting and seek flat minima, which can significantly improve the model's generalization performance. We evaluate our method on retinal and pathological image classification tasks, and our proposed method achieves significant improvements for out-of-distribution generalization. Our code is available at https://github.com/ubc-tea/FedSoup.
Fair Federated Medical Image Segmentation via Client Contribution Estimation
Mar 29, 2023How to ensure fairness is an important topic in federated learning (FL). Recent studies have investigated how to reward clients based on their contribution (collaboration fairness), and how to achieve uniformity of performance across clients (performance fairness). Despite achieving progress on either one, we argue that it is critical to consider them together, in order to engage and motivate more diverse clients joining FL to derive a high-quality global model. In this work, we propose a novel method to optimize both types of fairness simultaneously. Specifically, we propose to estimate client contribution in gradient and data space. In gradient space, we monitor the gradient direction differences of each client with respect to others. And in data space, we measure the prediction error on client data using an auxiliary model. Based on this contribution estimation, we propose a FL method, federated training via contribution estimation (FedCE), i.e., using estimation as global model aggregation weights. We have theoretically analyzed our method and empirically evaluated it on two real-world medical datasets. The effectiveness of our approach has been validated with significant performance improvements, better collaboration fairness, better performance fairness, and comprehensive analytical studies.
Federated Domain Generalization for Image Recognition via Cross-Client Style Transfer
Oct 03, 2022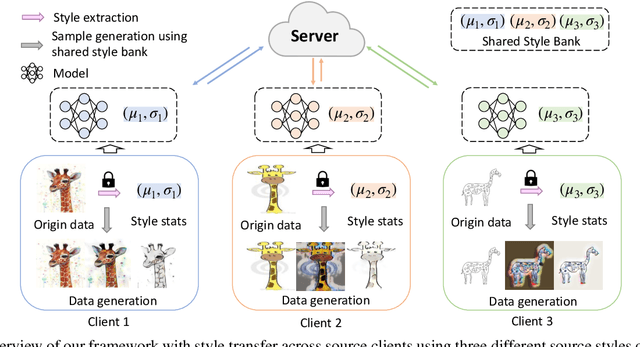
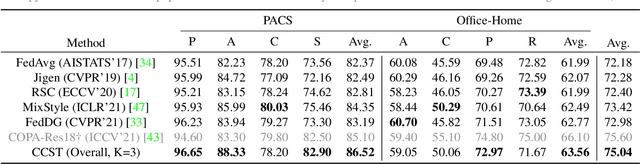
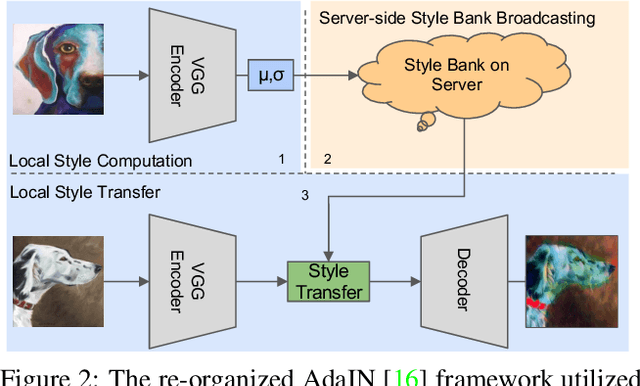
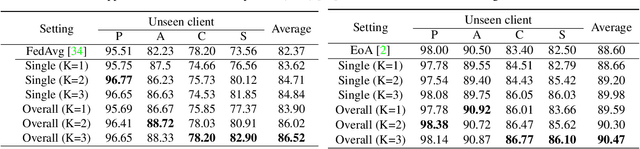
Domain generalization (DG) has been a hot topic in image recognition, with a goal to train a general model that can perform well on unseen domains. Recently, federated learning (FL), an emerging machine learning paradigm to train a global model from multiple decentralized clients without compromising data privacy, brings new challenges, also new possibilities, to DG. In the FL scenario, many existing state-of-the-art (SOTA) DG methods become ineffective, because they require the centralization of data from different domains during training. In this paper, we propose a novel domain generalization method for image recognition under federated learning through cross-client style transfer (CCST) without exchanging data samples. Our CCST method can lead to more uniform distributions of source clients, and thus make each local model learn to fit the image styles of all the clients to avoid the different model biases. Two types of style (single image style and overall domain style) with corresponding mechanisms are proposed to be chosen according to different scenarios. Our style representation is exceptionally lightweight and can hardly be used for the reconstruction of the dataset. The level of diversity is also flexible to be controlled with a hyper-parameter. Our method outperforms recent SOTA DG methods on two DG benchmarks (PACS, OfficeHome) and a large-scale medical image dataset (Camelyon17) in the FL setting. Last but not least, our method is orthogonal to many classic DG methods, achieving additive performance by combined utilization.
Dynamic Bank Learning for Semi-supervised Federated Image Diagnosis with Class Imbalance
Jun 27, 2022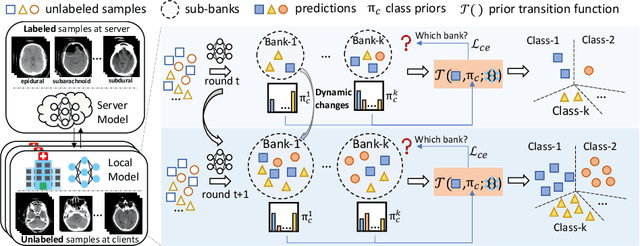
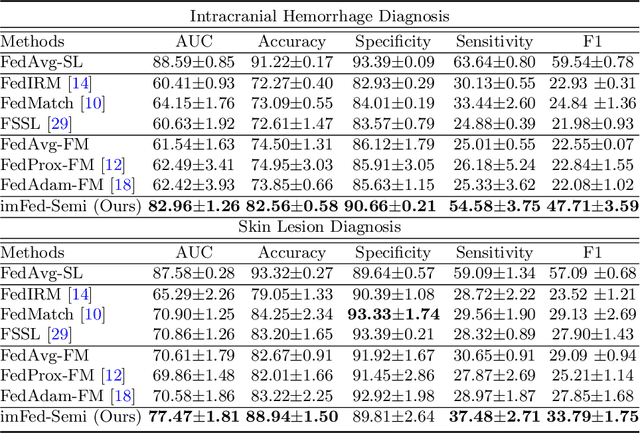
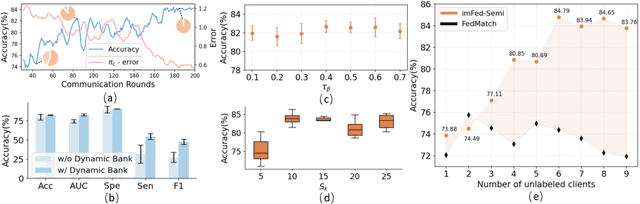
Despite recent progress on semi-supervised federated learning (FL) for medical image diagnosis, the problem of imbalanced class distributions among unlabeled clients is still unsolved for real-world use. In this paper, we study a practical yet challenging problem of class imbalanced semi-supervised FL (imFed-Semi), which allows all clients to have only unlabeled data while the server just has a small amount of labeled data. This imFed-Semi problem is addressed by a novel dynamic bank learning scheme, which improves client training by exploiting class proportion information. This scheme consists of two parts, i.e., the dynamic bank construction to distill various class proportions for each local client, and the sub-bank classification to impose the local model to learn different class proportions. We evaluate our approach on two public real-world medical datasets, including the intracranial hemorrhage diagnosis with 25,000 CT slices and skin lesion diagnosis with 10,015 dermoscopy images. The effectiveness of our method has been validated with significant performance improvements (7.61% and 4.69%) compared with the second-best on the accuracy, as well as comprehensive analytical studies. Code is available at https://github.com/med-air/imFedSemi.
DLTTA: Dynamic Learning Rate for Test-time Adaptation on Cross-domain Medical Images
May 27, 2022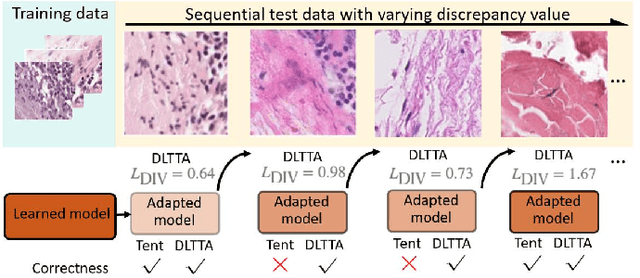
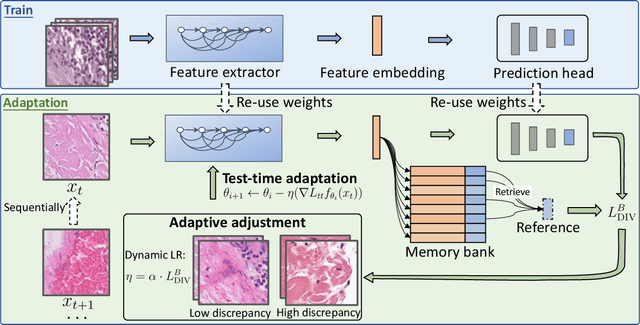
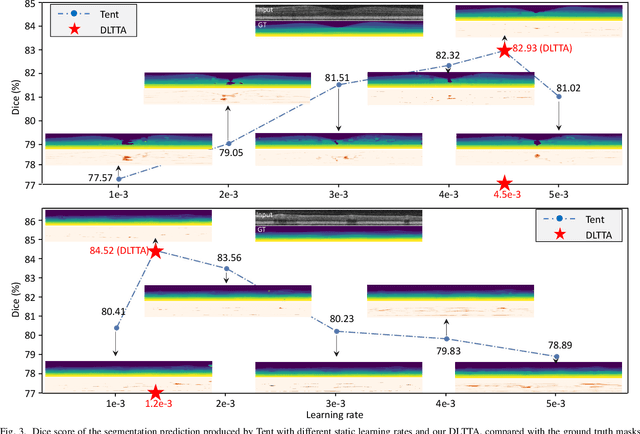
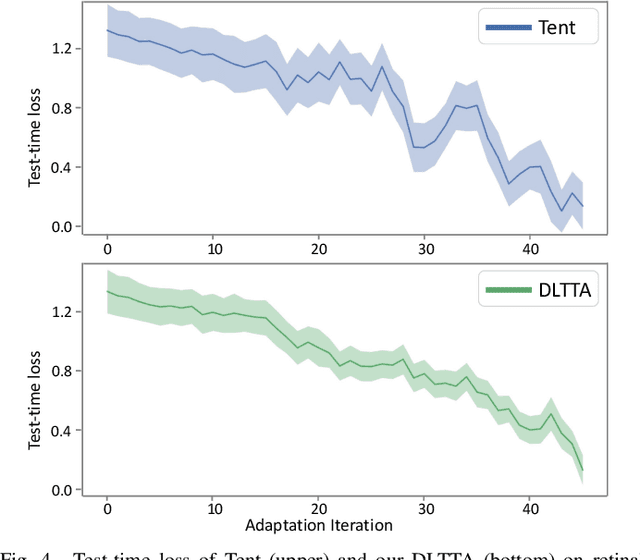
Test-time adaptation (TTA) has increasingly been an important topic to efficiently tackle the cross-domain distribution shift at test time for medical images from different institutions. Previous TTA methods have a common limitation of using a fixed learning rate for all the test samples. Such a practice would be sub-optimal for TTA, because test data may arrive sequentially therefore the scale of distribution shift would change frequently. To address this problem, we propose a novel dynamic learning rate adjustment method for test-time adaptation, called DLTTA, which dynamically modulates the amount of weights update for each test image to account for the differences in their distribution shift. Specifically, our DLTTA is equipped with a memory bank based estimation scheme to effectively measure the discrepancy of a given test sample. Based on this estimated discrepancy, a dynamic learning rate adjustment strategy is then developed to achieve a suitable degree of adaptation for each test sample. The effectiveness and general applicability of our DLTTA is extensively demonstrated on three tasks including retinal optical coherence tomography (OCT) segmentation, histopathological image classification, and prostate 3D MRI segmentation. Our method achieves effective and fast test-time adaptation with consistent performance improvement over current state-of-the-art test-time adaptation methods. Code is available at: https://github.com/med-air/DLTTA.
Federated Learning Enables Big Data for Rare Cancer Boundary Detection
Apr 25, 2022Although machine learning (ML) has shown promise in numerous domains, there are concerns about generalizability to out-of-sample data. This is currently addressed by centrally sharing ample, and importantly diverse, data from multiple sites. However, such centralization is challenging to scale (or even not feasible) due to various limitations. Federated ML (FL) provides an alternative to train accurate and generalizable ML models, by only sharing numerical model updates. Here we present findings from the largest FL study to-date, involving data from 71 healthcare institutions across 6 continents, to generate an automatic tumor boundary detector for the rare disease of glioblastoma, utilizing the largest dataset of such patients ever used in the literature (25,256 MRI scans from 6,314 patients). We demonstrate a 33% improvement over a publicly trained model to delineate the surgically targetable tumor, and 23% improvement over the tumor's entire extent. We anticipate our study to: 1) enable more studies in healthcare informed by large and diverse data, ensuring meaningful results for rare diseases and underrepresented populations, 2) facilitate further quantitative analyses for glioblastoma via performance optimization of our consensus model for eventual public release, and 3) demonstrate the effectiveness of FL at such scale and task complexity as a paradigm shift for multi-site collaborations, alleviating the need for data sharing.
IOP-FL: Inside-Outside Personalization for Federated Medical Image Segmentation
Apr 16, 2022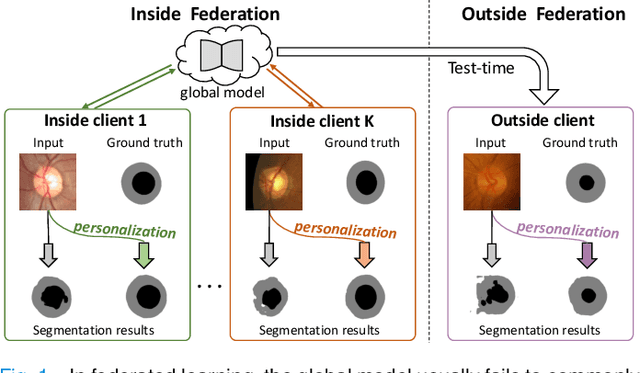
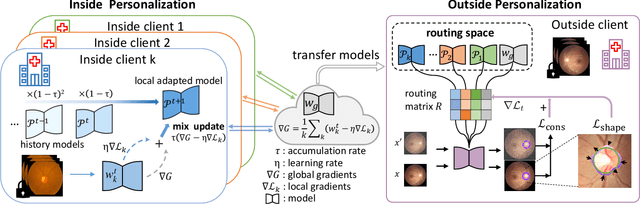
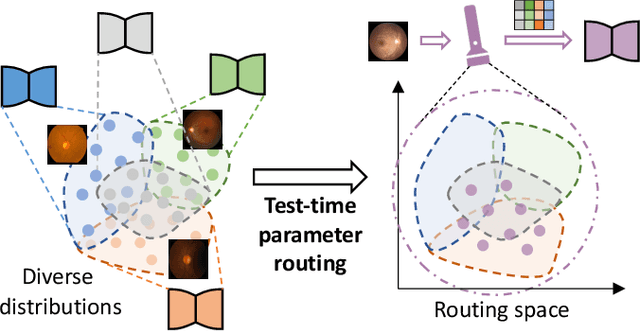
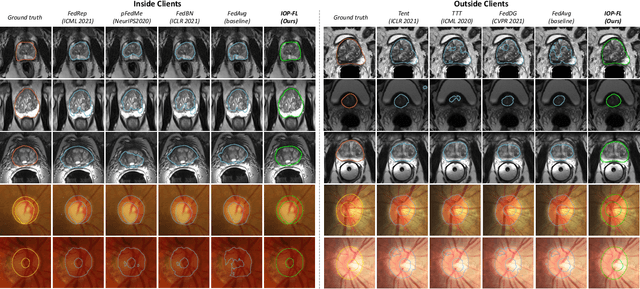
Federated learning (FL) allows multiple medical institutions to collaboratively learn a global model without centralizing all clients data. It is difficult, if possible at all, for such a global model to commonly achieve optimal performance for each individual client, due to the heterogeneity of medical data from various scanners and patient demographics. This problem becomes even more significant when deploying the global model to unseen clients outside the FL with new distributions not presented during federated training. To optimize the prediction accuracy of each individual client for critical medical tasks, we propose a novel unified framework for both Inside and Outside model Personalization in FL (IOP-FL). Our inside personalization is achieved by a lightweight gradient-based approach that exploits the local adapted model for each client, by accumulating both the global gradients for common knowledge and local gradients for client-specific optimization. Moreover, and importantly, the obtained local personalized models and the global model can form a diverse and informative routing space to personalize a new model for outside FL clients. Hence, we design a new test-time routing scheme inspired by the consistency loss with a shape constraint to dynamically incorporate the models, given the distribution information conveyed by the test data. Our extensive experimental results on two medical image segmentation tasks present significant improvements over SOTA methods on both inside and outside personalization, demonstrating the great potential of our IOP-FL scheme for clinical practice. Code will be released at https://github.com/med-air/IOP-FL.