 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePioneer: Physics-informed Riemannian Graph ODE for Entropy-increasing Dynamics
Feb 05, 2025



Dynamic interacting system modeling is important for understanding and simulating real world systems. The system is typically described as a graph, where multiple objects dynamically interact with each other and evolve over time. In recent years, graph Ordinary Differential Equations (ODE) receive increasing research attentions. While achieving encouraging results, existing solutions prioritize the traditional Euclidean space, and neglect the intrinsic geometry of the system and physics laws, e.g., the principle of entropy increasing. The limitations above motivate us to rethink the system dynamics from a fresh perspective of Riemannian geometry, and pose a more realistic problem of physics-informed dynamic system modeling, considering the underlying geometry and physics law for the first time. In this paper, we present a novel physics-informed Riemannian graph ODE for a wide range of entropy-increasing dynamic systems (termed as Pioneer). In particular, we formulate a differential system on the Riemannian manifold, where a manifold-valued graph ODE is governed by the proposed constrained Ricci flow, and a manifold preserving Gyro-transform aware of system geometry. Theoretically, we report the provable entropy non-decreasing of our formulation, obeying the physics laws. Empirical results show the superiority of Pioneer on real datasets.
Distributed Multi-Head Learning Systems for Power Consumption Prediction
Jan 21, 2025As more and more automatic vehicles, power consumption prediction becomes a vital issue for task scheduling and energy management. Most research focuses on automatic vehicles in transportation, but few focus on automatic ground vehicles (AGVs) in smart factories, which face complex environments and generate large amounts of data. There is an inevitable trade-off between feature diversity and interference. In this paper, we propose Distributed Multi-Head learning (DMH) systems for power consumption prediction in smart factories. Multi-head learning mechanisms are proposed in DMH to reduce noise interference and improve accuracy. Additionally, DMH systems are designed as distributed and split learning, reducing the client-to-server transmission cost, sharing knowledge without sharing local data and models, and enhancing the privacy and security levels. Experimental results show that the proposed DMH systems rank in the top-2 on most datasets and scenarios. DMH-E system reduces the error of the state-of-the-art systems by 14.5% to 24.0%. Effectiveness studies demonstrate the effectiveness of Pearson correlation-based feature engineering, and feature grouping with the proposed multi-head learning further enhances prediction performance.
Hierarchical Superpixel Segmentation via Structural Information Theory
Jan 13, 2025Superpixel segmentation is a foundation for many higher-level computer vision tasks, such as image segmentation, object recognition, and scene understanding. Existing graph-based superpixel segmentation methods typically concentrate on the relationships between a given pixel and its directly adjacent pixels while overlooking the influence of non-adjacent pixels. These approaches do not fully leverage the global information in the graph, leading to suboptimal segmentation quality. To address this limitation, we present SIT-HSS, a hierarchical superpixel segmentation method based on structural information theory. Specifically, we first design a novel graph construction strategy that incrementally explores the pixel neighborhood to add edges based on 1-dimensional structural entropy (1D SE). This strategy maximizes the retention of graph information while avoiding an overly complex graph structure. Then, we design a new 2D SE-guided hierarchical graph partitioning method, which iteratively merges pixel clusters layer by layer to reduce the graph's 2D SE until a predefined segmentation scale is achieved. Experimental results on three benchmark datasets demonstrate that the SIT-HSS performs better than state-of-the-art unsupervised superpixel segmentation algorithms. The source code is available at \url{https://github.com/SELGroup/SIT-HSS}.
Graph Contrastive Learning on Multi-label Classification for Recommendations
Jan 13, 2025



In business analysis, providing effective recommendations is essential for enhancing company profits. The utilization of graph-based structures, such as bipartite graphs, has gained popularity for their ability to analyze complex data relationships. Link prediction is crucial for recommending specific items to users. Traditional methods in this area often involve identifying patterns in the graph structure or using representational techniques like graph neural networks (GNNs). However, these approaches encounter difficulties as the volume of data increases. To address these challenges, we propose a model called Graph Contrastive Learning for Multi-label Classification (MCGCL). MCGCL leverages contrastive learning to enhance recommendation effectiveness. The model incorporates two training stages: a main task and a subtask. The main task is holistic user-item graph learning to capture user-item relationships. The homogeneous user-user (item-item) subgraph is constructed to capture user-user and item-item relationships in the subtask. We assessed the performance using real-world datasets from Amazon Reviews in multi-label classification tasks. Comparative experiments with state-of-the-art methods confirm the effectiveness of MCGCL, highlighting its potential for improving recommendation systems.
ADKGD: Anomaly Detection in Knowledge Graphs with Dual-Channel Training
Jan 13, 2025In the current development of large language models (LLMs), it is important to ensure the accuracy and reliability of the underlying data sources. LLMs are critical for various applications, but they often suffer from hallucinations and inaccuracies due to knowledge gaps in the training data. Knowledge graphs (KGs), as a powerful structural tool, could serve as a vital external information source to mitigate the aforementioned issues. By providing a structured and comprehensive understanding of real-world data, KGs enhance the performance and reliability of LLMs. However, it is common that errors exist in KGs while extracting triplets from unstructured data to construct KGs. This could lead to degraded performance in downstream tasks such as question-answering and recommender systems. Therefore, anomaly detection in KGs is essential to identify and correct these errors. This paper presents an anomaly detection algorithm in knowledge graphs with dual-channel learning (ADKGD). ADKGD leverages a dual-channel learning approach to enhance representation learning from both the entity-view and triplet-view perspectives. Furthermore, using a cross-layer approach, our framework integrates internal information aggregation and context information aggregation. We introduce a kullback-leibler (KL)-loss component to improve the accuracy of the scoring function between the dual channels. To evaluate ADKGD's performance, we conduct empirical studies on three real-world KGs: WN18RR, FB15K, and NELL-995. Experimental results demonstrate that ADKGD outperforms the state-of-the-art anomaly detection algorithms. The source code and datasets are publicly available at https://github.com/csjywu1/ADKGD.
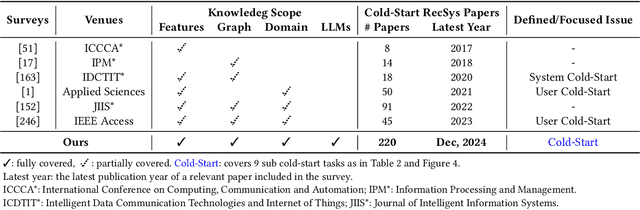
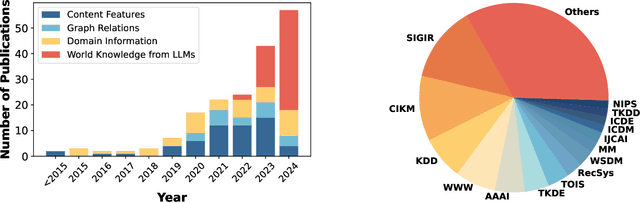
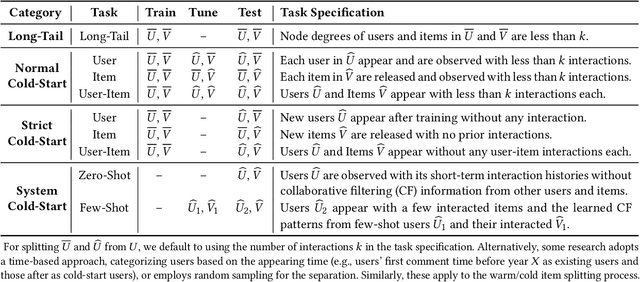
Cold-Start Recommendation towards the Era of Large Language Models (LLMs): A Comprehensive Survey and Roadmap
Jan 03, 2025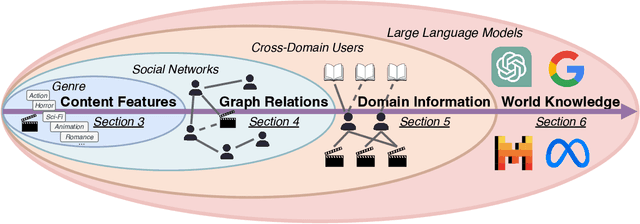
Cold-start problem is one of the long-standing challenges in recommender systems, focusing on accurately modeling new or interaction-limited users or items to provide better recommendations. Due to the diversification of internet platforms and the exponential growth of users and items, the importance of cold-start recommendation (CSR) is becoming increasingly evident. At the same time, large language models (LLMs) have achieved tremendous success and possess strong capabilities in modeling user and item information, providing new potential for cold-start recommendations. However, the research community on CSR still lacks a comprehensive review and reflection in this field. Based on this, in this paper, we stand in the context of the era of large language models and provide a comprehensive review and discussion on the roadmap, related literature, and future directions of CSR. Specifically, we have conducted an exploration of the development path of how existing CSR utilizes information, from content features, graph relations, and domain information, to the world knowledge possessed by large language models, aiming to provide new insights for both the research and industrial communities on CSR. Related resources of cold-start recommendations are collected and continuously updated for the community in https://github.com/YuanchenBei/Awesome-Cold-Start-Recommendation.
Property Enhanced Instruction Tuning for Multi-task Molecule Generation with Large Language Models
Dec 24, 2024Large language models (LLMs) are widely applied in various natural language processing tasks such as question answering and machine translation. However, due to the lack of labeled data and the difficulty of manual annotation for biochemical properties, the performance for molecule generation tasks is still limited, especially for tasks involving multi-properties constraints. In this work, we present a two-step framework PEIT (Property Enhanced Instruction Tuning) to improve LLMs for molecular-related tasks. In the first step, we use textual descriptions, SMILES, and biochemical properties as multimodal inputs to pre-train a model called PEIT-GEN, by aligning multi-modal representations to synthesize instruction data. In the second step, we fine-tune existing open-source LLMs with the synthesized data, the resulting PEIT-LLM can handle molecule captioning, text-based molecule generation, molecular property prediction, and our newly proposed multi-constraint molecule generation tasks. Experimental results show that our pre-trained PEIT-GEN outperforms MolT5 and BioT5 in molecule captioning, demonstrating modalities align well between textual descriptions, structures, and biochemical properties. Furthermore, PEIT-LLM shows promising improvements in multi-task molecule generation, proving the scalability of the PEIT framework for various molecular tasks. We release the code, constructed instruction data, and model checkpoints in https://github.com/chenlong164/PEIT.
SocialED: A Python Library for Social Event Detection
Dec 18, 2024

SocialED is a comprehensive, open-source Python library designed to support social event detection (SED) tasks, integrating 19 detection algorithms and 14 diverse datasets. It provides a unified API with detailed documentation, offering researchers and practitioners a complete solution for event detection in social media. The library is designed with modularity in mind, allowing users to easily adapt and extend components for various use cases. SocialED supports a wide range of preprocessing techniques, such as graph construction and tokenization, and includes standardized interfaces for training models and making predictions. By integrating popular deep learning frameworks, SocialED ensures high efficiency and scalability across both CPU and GPU environments. The library is built adhering to high code quality standards, including unit testing, continuous integration, and code coverage, ensuring that SocialED delivers robust, maintainable software. SocialED is publicly available at \url{https://github.com/RingBDStack/SocialED} and can be installed via PyPI.
Towards Effective, Efficient and Unsupervised Social Event Detection in the Hyperbolic Space
Dec 14, 2024



The vast, complex, and dynamic nature of social message data has posed challenges to social event detection (SED). Despite considerable effort, these challenges persist, often resulting in inadequately expressive message representations (ineffective) and prolonged learning durations (inefficient). In response to the challenges, this work introduces an unsupervised framework, HyperSED (Hyperbolic SED). Specifically, the proposed framework first models social messages into semantic-based message anchors, and then leverages the structure of the anchor graph and the expressiveness of the hyperbolic space to acquire structure- and geometry-aware anchor representations. Finally, HyperSED builds the partitioning tree of the anchor message graph by incorporating differentiable structural information as the reflection of the detected events. Extensive experiments on public datasets demonstrate HyperSED's competitive performance, along with a substantial improvement in efficiency compared to the current state-of-the-art unsupervised paradigm. Statistically, HyperSED boosts incremental SED by an average of 2%, 2%, and 25% in NMI, AMI, and ARI, respectively; enhancing efficiency by up to 37.41 times and at least 12.10 times, illustrating the advancement of the proposed framework. Our code is publicly available at https://github.com/XiaoyanWork/HyperSED.
Structural Entropy Guided Probabilistic Coding
Dec 12, 2024



Probabilistic embeddings have several advantages over deterministic embeddings as they map each data point to a distribution, which better describes the uncertainty and complexity of data. Many works focus on adjusting the distribution constraint under the Information Bottleneck (IB) principle to enhance representation learning. However, these proposed regularization terms only consider the constraint of each latent variable, omitting the structural information between latent variables. In this paper, we propose a novel structural entropy-guided probabilistic coding model, named SEPC. Specifically, we incorporate the relationship between latent variables into the optimization by proposing a structural entropy regularization loss. Besides, as traditional structural information theory is not well-suited for regression tasks, we propose a probabilistic encoding tree, transferring regression tasks to classification tasks while diminishing the influence of the transformation. Experimental results across 12 natural language understanding tasks, including both classification and regression tasks, demonstrate the superior performance of SEPC compared to other state-of-the-art models in terms of effectiveness, generalization capability, and robustness to label noise. The codes and datasets are available at https://github.com/SELGroup/SEPC.