 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrustLLM: Trustworthiness in Large Language Models
Jan 25, 2024



Large language models (LLMs), exemplified by ChatGPT, have gained considerable attention for their excellent natural language processing capabilities. Nonetheless, these LLMs present many challenges, particularly in the realm of trustworthiness. Therefore, ensuring the trustworthiness of LLMs emerges as an important topic. This paper introduces TrustLLM, a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. Our findings firstly show that in general trustworthiness and utility (i.e., functional effectiveness) are positively related. Secondly, our observations reveal that proprietary LLMs generally outperform most open-source counterparts in terms of trustworthiness, raising concerns about the potential risks of widely accessible open-source LLMs. However, a few open-source LLMs come very close to proprietary ones. Thirdly, it is important to note that some LLMs may be overly calibrated towards exhibiting trustworthiness, to the extent that they compromise their utility by mistakenly treating benign prompts as harmful and consequently not responding. Finally, we emphasize the importance of ensuring transparency not only in the models themselves but also in the technologies that underpin trustworthiness. Knowing the specific trustworthy technologies that have been employed is crucial for analyzing their effectiveness.
Multitask Active Learning for Graph Anomaly Detection
Jan 24, 2024In the web era, graph machine learning has been widely used on ubiquitous graph-structured data. As a pivotal component for bolstering web security and enhancing the robustness of graph-based applications, the significance of graph anomaly detection is continually increasing. While Graph Neural Networks (GNNs) have demonstrated efficacy in supervised and semi-supervised graph anomaly detection, their performance is contingent upon the availability of sufficient ground truth labels. The labor-intensive nature of identifying anomalies from complex graph structures poses a significant challenge in real-world applications. Despite that, the indirect supervision signals from other tasks (e.g., node classification) are relatively abundant. In this paper, we propose a novel MultItask acTIve Graph Anomaly deTEction framework, namely MITIGATE. Firstly, by coupling node classification tasks, MITIGATE obtains the capability to detect out-of-distribution nodes without known anomalies. Secondly, MITIGATE quantifies the informativeness of nodes by the confidence difference across tasks, allowing samples with conflicting predictions to provide informative yet not excessively challenging information for subsequent training. Finally, to enhance the likelihood of selecting representative nodes that are distant from known patterns, MITIGATE adopts a masked aggregation mechanism for distance measurement, considering both inherent features of nodes and current labeled status. Empirical studies on four datasets demonstrate that MITIGATE significantly outperforms the state-of-the-art methods for anomaly detection. Our code is publicly available at: https://github.com/AhaChang/MITIGATE.
DeepRicci: Self-supervised Graph Structure-Feature Co-Refinement for Alleviating Over-squashing
Jan 23, 2024Graph Neural Networks (GNNs) have shown great power for learning and mining on graphs, and Graph Structure Learning (GSL) plays an important role in boosting GNNs with a refined graph. In the literature, most GSL solutions either primarily focus on structure refinement with task-specific supervision (i.e., node classification), or overlook the inherent weakness of GNNs themselves (e.g., over-squashing), resulting in suboptimal performance despite sophisticated designs. In light of these limitations, we propose to study self-supervised graph structure-feature co-refinement for effectively alleviating the issue of over-squashing in typical GNNs. In this paper, we take a fundamentally different perspective of the Ricci curvature in Riemannian geometry, in which we encounter the challenges of modeling, utilizing and computing Ricci curvature. To tackle these challenges, we present a self-supervised Riemannian model, DeepRicci. Specifically, we introduce a latent Riemannian space of heterogeneous curvatures to model various Ricci curvatures, and propose a gyrovector feature mapping to utilize Ricci curvature for typical GNNs. Thereafter, we refine node features by geometric contrastive learning among different geometric views, and simultaneously refine graph structure by backward Ricci flow based on a novel formulation of differentiable Ricci curvature. Finally, extensive experiments on public datasets show the superiority of DeepRicci, and the connection between backward Ricci flow and over-squashing. Codes of our work are given in https://github.com/RiemanGraph/.
A Survey of Text Watermarking in the Era of Large Language Models
Jan 03, 2024



Text watermarking algorithms play a crucial role in the copyright protection of textual content, yet their capabilities and application scenarios have been limited historically. The recent developments in large language models (LLMs) have opened new opportunities for the advancement of text watermarking techniques. LLMs not only enhance the capabilities of text watermarking algorithms through their text understanding and generation abilities but also necessitate the use of text watermarking algorithms for their own copyright protection. This paper conducts a comprehensive survey of the current state of text watermarking technology, covering four main aspects: (1) an overview and comparison of different text watermarking techniques; (2) evaluation methods for text watermarking algorithms, including their success rates, impact on text quality, robustness, and unforgeability; (3) potential application scenarios for text watermarking technology; (4) current challenges and future directions for development. This survey aims to provide researchers with a thorough understanding of text watermarking technology, thereby promoting its further advancement.
Contrastive Sequential Interaction Network Learning on Co-Evolving Riemannian Spaces
Jan 02, 2024The sequential interaction network usually find itself in a variety of applications, e.g., recommender system. Herein, inferring future interaction is of fundamental importance, and previous efforts are mainly focused on the dynamics in the classic zero-curvature Euclidean space. Despite the promising results achieved by previous methods, a range of significant issues still largely remains open: On the bipartite nature, is it appropriate to place user and item nodes in one identical space regardless of their inherent difference? On the network dynamics, instead of a fixed curvature space, will the representation spaces evolve when new interactions arrive continuously? On the learning paradigm, can we get rid of the label information costly to acquire? To address the aforementioned issues, we propose a novel Contrastive model for Sequential Interaction Network learning on Co-Evolving RiEmannian spaces, CSINCERE. To the best of our knowledge, we are the first to introduce a couple of co-evolving representation spaces, rather than a single or static space, and propose a co-contrastive learning for the sequential interaction network. In CSINCERE, we formulate a Cross-Space Aggregation for message-passing across representation spaces of different Riemannian geometries, and design a Neural Curvature Estimator based on Ricci curvatures for modeling the space evolvement over time. Thereafter, we present a Reweighed Co-Contrast between the temporal views of the sequential network, so that the couple of Riemannian spaces interact with each other for the interaction prediction without labels. Empirical results on 5 public datasets show the superiority of CSINCERE over the state-of-the-art methods.
Deep Learning for Code Intelligence: Survey, Benchmark and Toolkit
Dec 30, 2023



Code intelligence leverages machine learning techniques to extract knowledge from extensive code corpora, with the aim of developing intelligent tools to improve the quality and productivity of computer programming. Currently, there is already a thriving research community focusing on code intelligence, with efforts ranging from software engineering, machine learning, data mining, natural language processing, and programming languages. In this paper, we conduct a comprehensive literature review on deep learning for code intelligence, from the aspects of code representation learning, deep learning techniques, and application tasks. We also benchmark several state-of-the-art neural models for code intelligence, and provide an open-source toolkit tailored for the rapid prototyping of deep-learning-based code intelligence models. In particular, we inspect the existing code intelligence models under the basis of code representation learning, and provide a comprehensive overview to enhance comprehension of the present state of code intelligence. Furthermore, we publicly release the source code and data resources to provide the community with a ready-to-use benchmark, which can facilitate the evaluation and comparison of existing and future code intelligence models (https://xcodemind.github.io). At last, we also point out several challenging and promising directions for future research.
Data Augmentation for Supervised Graph Outlier Detection with Latent Diffusion Models
Dec 29, 2023



Graph outlier detection is a prominent task of research and application in the realm of graph neural networks. It identifies the outlier nodes that exhibit deviation from the majority in the graph. One of the fundamental challenges confronting supervised graph outlier detection algorithms is the prevalent issue of class imbalance, where the scarcity of outlier instances compared to normal instances often results in suboptimal performance. Conventional methods mitigate the imbalance by reweighting instances in the estimation of the loss function, assigning higher weights to outliers and lower weights to inliers. Nonetheless, these strategies are prone to overfitting and underfitting, respectively. Recently, generative models, especially diffusion models, have demonstrated their efficacy in synthesizing high-fidelity images. Despite their extraordinary generation quality, their potential in data augmentation for supervised graph outlier detection remains largely underexplored. To bridge this gap, we introduce GODM, a novel data augmentation for mitigating class imbalance in supervised Graph Outlier detection with latent Diffusion Models. Specifically, our proposed method consists of three key components: (1) Variantioanl Encoder maps the heterogeneous information inherent within the graph data into a unified latent space. (2) Graph Generator synthesizes graph data that are statistically similar to real outliers from latent space, and (3) Latent Diffusion Model learns the latent space distribution of real organic data by iterative denoising. Extensive experiments conducted on multiple datasets substantiate the effectiveness and efficiency of GODM. The case study further demonstrated the generation quality of our synthetic data. To foster accessibility and reproducibility, we encapsulate GODM into a plug-and-play package and release it at the Python Package Index (PyPI).
Hypergraph Enhanced Knowledge Tree Prompt Learning for Next-Basket Recommendation
Dec 26, 2023
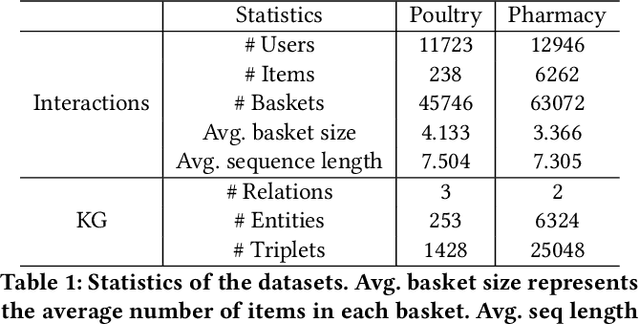
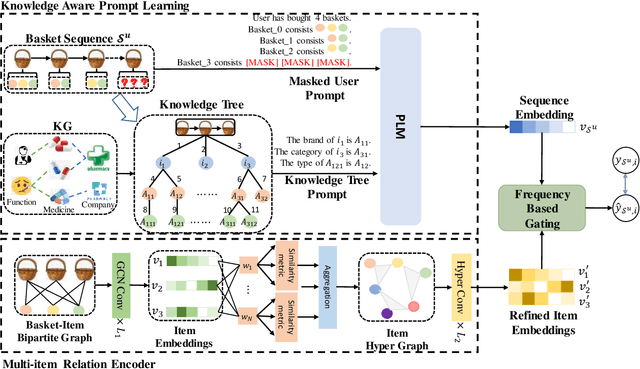
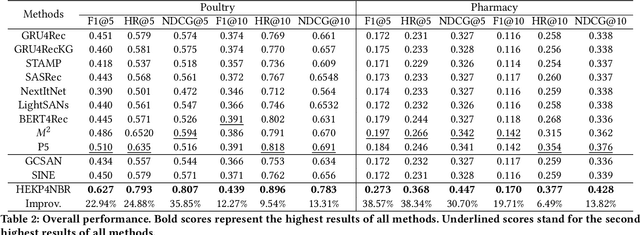
Next-basket recommendation (NBR) aims to infer the items in the next basket given the corresponding basket sequence. Existing NBR methods are mainly based on either message passing in a plain graph or transition modelling in a basket sequence. However, these methods only consider point-to-point binary item relations while item dependencies in real world scenarios are often in higher order. Additionally, the importance of the same item to different users varies due to variation of user preferences, and the relations between items usually involve various aspects. As pretrained language models (PLMs) excel in multiple tasks in natural language processing (NLP) and computer vision (CV), many researchers have made great efforts in utilizing PLMs to boost recommendation. However, existing PLM-based recommendation methods degrade when encountering Out-Of-Vocabulary (OOV) items. OOV items are those whose IDs are out of PLM's vocabulary and thus unintelligible to PLM. To settle the above challenges, we propose a novel method HEKP4NBR, which transforms the knowledge graph (KG) into prompts, namely Knowledge Tree Prompt (KTP), to help PLM encode the OOV item IDs in the user's basket sequence. A hypergraph convolutional module is designed to build a hypergraph based on item similarities measured by an MoE model from multiple aspects and then employ convolution on the hypergraph to model correlations among multiple items. Extensive experiments are conducted on HEKP4NBR on two datasets based on real company data and validate its effectiveness against multiple state-of-the-art methods.
Prompt Based Tri-Channel Graph Convolution Neural Network for Aspect Sentiment Triplet Extraction
Dec 24, 2023



Aspect Sentiment Triplet Extraction (ASTE) is an emerging task to extract a given sentence's triplets, which consist of aspects, opinions, and sentiments. Recent studies tend to address this task with a table-filling paradigm, wherein word relations are encoded in a two-dimensional table, and the process involves clarifying all the individual cells to extract triples. However, these studies ignore the deep interaction between neighbor cells, which we find quite helpful for accurate extraction. To this end, we propose a novel model for the ASTE task, called Prompt-based Tri-Channel Graph Convolution Neural Network (PT-GCN), which converts the relation table into a graph to explore more comprehensive relational information. Specifically, we treat the original table cells as nodes and utilize a prompt attention score computation module to determine the edges' weights. This enables us to construct a target-aware grid-like graph to enhance the overall extraction process. After that, a triple-channel convolution module is conducted to extract precise sentiment knowledge. Extensive experiments on the benchmark datasets show that our model achieves state-of-the-art performance. The code is available at https://github.com/KunPunCN/PT-GCN.
Hierarchical and Incremental Structural Entropy Minimization for Unsupervised Social Event Detection
Dec 19, 2023



As a trending approach for social event detection, graph neural network (GNN)-based methods enable a fusion of natural language semantics and the complex social network structural information, thus showing SOTA performance. However, GNN-based methods can miss useful message correlations. Moreover, they require manual labeling for training and predetermining the number of events for prediction. In this work, we address social event detection via graph structural entropy (SE) minimization. While keeping the merits of the GNN-based methods, the proposed framework, HISEvent, constructs more informative message graphs, is unsupervised, and does not require the number of events given a priori. Specifically, we incrementally explore the graph neighborhoods using 1-dimensional (1D) SE minimization to supplement the existing message graph with edges between semantically related messages. We then detect events from the message graph by hierarchically minimizing 2-dimensional (2D) SE. Our proposed 1D and 2D SE minimization algorithms are customized for social event detection and effectively tackle the efficiency problem of the existing SE minimization algorithms. Extensive experiments show that HISEvent consistently outperforms GNN-based methods and achieves the new SOTA for social event detection under both closed- and open-set settings while being efficient and robust.