 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Real-World Burst Image Super-Resolution: Benchmark and Method
Sep 09, 2023Despite substantial advances, single-image super-resolution (SISR) is always in a dilemma to reconstruct high-quality images with limited information from one input image, especially in realistic scenarios. In this paper, we establish a large-scale real-world burst super-resolution dataset, i.e., RealBSR, to explore the faithful reconstruction of image details from multiple frames. Furthermore, we introduce a Federated Burst Affinity network (FBAnet) to investigate non-trivial pixel-wise displacements among images under real-world image degradation. Specifically, rather than using pixel-wise alignment, our FBAnet employs a simple homography alignment from a structural geometry aspect and a Federated Affinity Fusion (FAF) strategy to aggregate the complementary information among frames. Those fused informative representations are fed to a Transformer-based module of burst representation decoding. Besides, we have conducted extensive experiments on two versions of our datasets, i.e., RealBSR-RAW and RealBSR-RGB. Experimental results demonstrate that our FBAnet outperforms existing state-of-the-art burst SR methods and also achieves visually-pleasant SR image predictions with model details. Our dataset, codes, and models are publicly available at https://github.com/yjsunnn/FBANet.
Identity-Preserving Talking Face Generation with Landmark and Appearance Priors
May 15, 2023



Generating talking face videos from audio attracts lots of research interest. A few person-specific methods can generate vivid videos but require the target speaker's videos for training or fine-tuning. Existing person-generic methods have difficulty in generating realistic and lip-synced videos while preserving identity information. To tackle this problem, we propose a two-stage framework consisting of audio-to-landmark generation and landmark-to-video rendering procedures. First, we devise a novel Transformer-based landmark generator to infer lip and jaw landmarks from the audio. Prior landmark characteristics of the speaker's face are employed to make the generated landmarks coincide with the facial outline of the speaker. Then, a video rendering model is built to translate the generated landmarks into face images. During this stage, prior appearance information is extracted from the lower-half occluded target face and static reference images, which helps generate realistic and identity-preserving visual content. For effectively exploring the prior information of static reference images, we align static reference images with the target face's pose and expression based on motion fields. Moreover, auditory features are reused to guarantee that the generated face images are well synchronized with the audio. Extensive experiments demonstrate that our method can produce more realistic, lip-synced, and identity-preserving videos than existing person-generic talking face generation methods.
Masked Images Are Counterfactual Samples for Robust Fine-tuning
Mar 14, 2023Deep learning models are challenged by the distribution shift between the training data and test data. Recently, the large models pre-trained on diverse data demonstrate unprecedented robustness to various distribution shifts. However, fine-tuning on these models can lead to a trade-off between in-distribution (ID) performance and out-of-distribution (OOD) robustness. Existing methods for tackling this trade-off do not explicitly address the OOD robustness problem. In this paper, based on causal analysis on the aforementioned problems, we propose a novel fine-tuning method, which use masked images as counterfactual samples that help improving the robustness of the fine-tuning model. Specifically, we mask either the semantics-related or semantics-unrelated patches of the images based on class activation map to break the spurious correlation, and refill the masked patches with patches from other images. The resulting counterfactual samples are used in feature-based distillation with the pre-trained model. Extensive experiments verify that regularizing the fine-tuning with the proposed masked images can achieve a better trade-off between ID and OOD performance, surpassing previous methods on the OOD performance. Our code will be publicly available.
DQnet: Cross-Model Detail Querying for Camouflaged Object Detection
Dec 16, 2022Camouflaged objects are seamlessly blended in with their surroundings, which brings a challenging detection task in computer vision. Optimizing a convolutional neural network (CNN) for camouflaged object detection (COD) tends to activate local discriminative regions while ignoring complete object extent, causing the partial activation issue which inevitably leads to missing or redundant regions of objects. In this paper, we argue that partial activation is caused by the intrinsic characteristics of CNN, where the convolution operations produce local receptive fields and experience difficulty to capture long-range feature dependency among image regions. In order to obtain feature maps that could activate full object extent, keeping the segmental results from being overwhelmed by noisy features, a novel framework termed Cross-Model Detail Querying network (DQnet) is proposed. It reasons the relations between long-range-aware representations and multi-scale local details to make the enhanced representation fully highlight the object regions and eliminate noise on non-object regions. Specifically, a vanilla ViT pretrained with self-supervised learning (SSL) is employed to model long-range dependencies among image regions. A ResNet is employed to enable learning fine-grained spatial local details in multiple scales. Then, to effectively retrieve object-related details, a Relation-Based Querying (RBQ) module is proposed to explore window-based interactions between the global representations and the multi-scale local details. Extensive experiments are conducted on the widely used COD datasets and show that our DQnet outperforms the current state-of-the-arts.
Out-of-Candidate Rectification for Weakly Supervised Semantic Segmentation
Nov 22, 2022Weakly supervised semantic segmentation is typically inspired by class activation maps, which serve as pseudo masks with class-discriminative regions highlighted. Although tremendous efforts have been made to recall precise and complete locations for each class, existing methods still commonly suffer from the unsolicited Out-of-Candidate (OC) error predictions that not belongs to the label candidates, which could be avoidable since the contradiction with image-level class tags is easy to be detected. In this paper, we develop a group ranking-based Out-of-Candidate Rectification (OCR) mechanism in a plug-and-play fashion. Firstly, we adaptively split the semantic categories into In-Candidate (IC) and OC groups for each OC pixel according to their prior annotation correlation and posterior prediction correlation. Then, we derive a differentiable rectification loss to force OC pixels to shift to the IC group. Incorporating our OCR with seminal baselines (e.g., AffinityNet, SEAM, MCTformer), we can achieve remarkable performance gains on both Pascal VOC (+3.2%, +3.3%, +0.8% mIoU) and MS COCO (+1.0%, +1.3%, +0.5% mIoU) datasets with negligible extra training overhead, which justifies the effectiveness and generality of our OCR.
DreamArtist: Towards Controllable One-Shot Text-to-Image Generation via Contrastive Prompt-Tuning
Nov 21, 2022Large-scale text-to-image generation models with an exponential evolution can currently synthesize high-resolution, feature-rich, high-quality images based on text guidance. However, they are often overwhelmed by words of new concepts, styles, or object entities that always emerge. Although there are some recent attempts to use fine-tuning or prompt-tuning methods to teach the model a new concept as a new pseudo-word from a given reference image set, these methods are not only still difficult to synthesize diverse and high-quality images without distortion and artifacts, but also suffer from low controllability. To address these problems, we propose a DreamArtist method that employs a learning strategy of contrastive prompt-tuning, which introduces both positive and negative embeddings as pseudo-words and trains them jointly. The positive embedding aggressively learns characteristics in the reference image to drive the model diversified generation, while the negative embedding introspects in a self-supervised manner to rectify the mistakes and inadequacies from positive embedding in reverse. It learns not only what is correct but also what should be avoided. Extensive experiments on image quality and diversity analysis, controllability analysis, model learning analysis and task expansion have demonstrated that our model learns not only concept but also form, content and context. Pseudo-words of DreamArtist have similar properties as true words to generate high-quality images.
Robust Real-World Image Super-Resolution against Adversarial Attacks
Jul 31, 2022
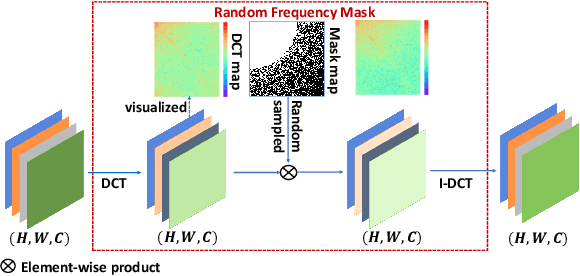
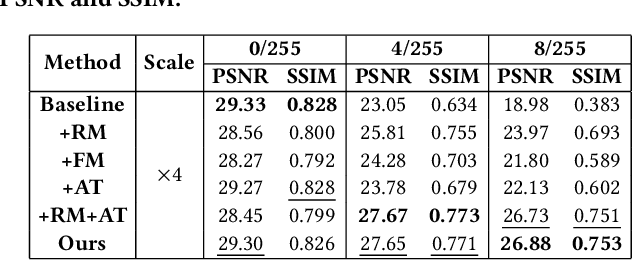
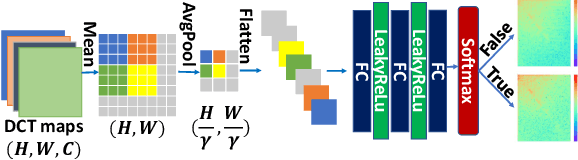
Recently deep neural networks (DNNs) have achieved significant success in real-world image super-resolution (SR). However, adversarial image samples with quasi-imperceptible noises could threaten deep learning SR models. In this paper, we propose a robust deep learning framework for real-world SR that randomly erases potential adversarial noises in the frequency domain of input images or features. The rationale is that on the SR task clean images or features have a different pattern from the attacked ones in the frequency domain. Observing that existing adversarial attacks usually add high-frequency noises to input images, we introduce a novel random frequency mask module that blocks out high-frequency components possibly containing the harmful perturbations in a stochastic manner. Since the frequency masking may not only destroys the adversarial perturbations but also affects the sharp details in a clean image, we further develop an adversarial sample classifier based on the frequency domain of images to determine if applying the proposed mask module. Based on the above ideas, we devise a novel real-world image SR framework that combines the proposed frequency mask modules and the proposed adversarial classifier with an existing super-resolution backbone network. Experiments show that our proposed method is more insensitive to adversarial attacks and presents more stable SR results than existing models and defenses.
* ACM-MM 2021, Code: https://github.com/lhaof/Robust-SR-against-Adversarial-Attacks
Adversarially-Aware Robust Object Detector
Jul 22, 2022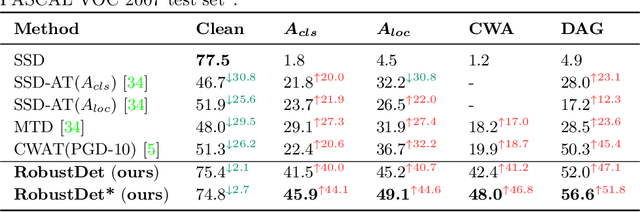
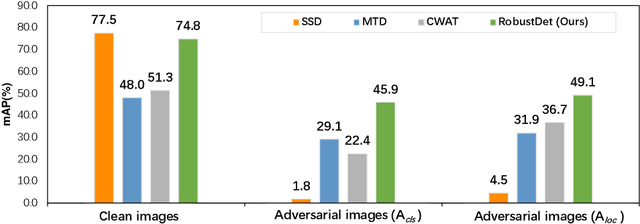
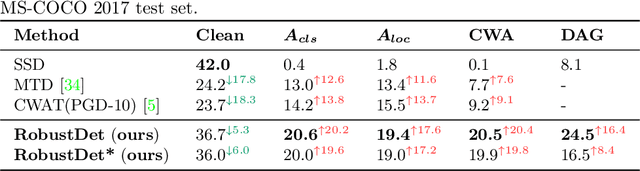
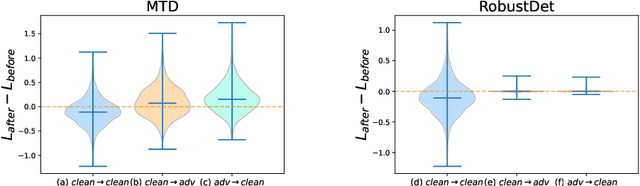
Object detection, as a fundamental computer vision task, has achieved a remarkable progress with the emergence of deep neural networks. Nevertheless, few works explore the adversarial robustness of object detectors to resist adversarial attacks for practical applications in various real-world scenarios. Detectors have been greatly challenged by unnoticeable perturbation, with sharp performance drop on clean images and extremely poor performance on adversarial images. In this work, we empirically explore the model training for adversarial robustness in object detection, which greatly attributes to the conflict between learning clean images and adversarial images. To mitigate this issue, we propose a Robust Detector (RobustDet) based on adversarially-aware convolution to disentangle gradients for model learning on clean and adversarial images. RobustDet also employs the Adversarial Image Discriminator (AID) and Consistent Features with Reconstruction (CFR) to ensure a reliable robustness. Extensive experiments on PASCAL VOC and MS-COCO demonstrate that our model effectively disentangles gradients and significantly enhances the detection robustness with maintaining the detection ability on clean images.
* ECCV2022 oral paper
Real-World Image Super-Resolution by Exclusionary Dual-Learning
Jun 06, 2022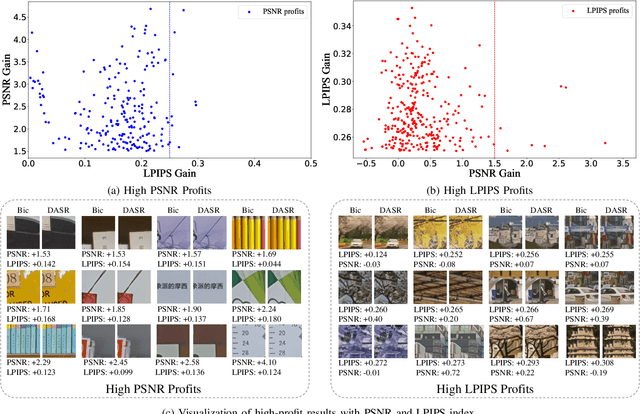

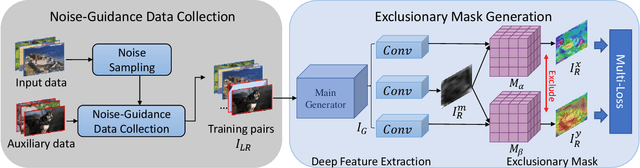
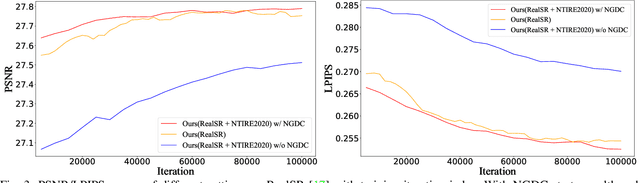
Real-world image super-resolution is a practical image restoration problem that aims to obtain high-quality images from in-the-wild input, has recently received considerable attention with regard to its tremendous application potentials. Although deep learning-based methods have achieved promising restoration quality on real-world image super-resolution datasets, they ignore the relationship between L1- and perceptual- minimization and roughly adopt auxiliary large-scale datasets for pre-training. In this paper, we discuss the image types within a corrupted image and the property of perceptual- and Euclidean- based evaluation protocols. Then we propose a method, Real-World image Super-Resolution by Exclusionary Dual-Learning (RWSR-EDL) to address the feature diversity in perceptual- and L1- based cooperative learning. Moreover, a noise-guidance data collection strategy is developed to address the training time consumption in multiple datasets optimization. When an auxiliary dataset is incorporated, RWSR-EDL achieves promising results and repulses any training time increment by adopting the noise-guidance data collection strategy. Extensive experiments show that RWSR-EDL achieves competitive performance over state-of-the-art methods on four in-the-wild image super-resolution datasets.
Dual Adversarial Adaptation for Cross-Device Real-World Image Super-Resolution
May 07, 2022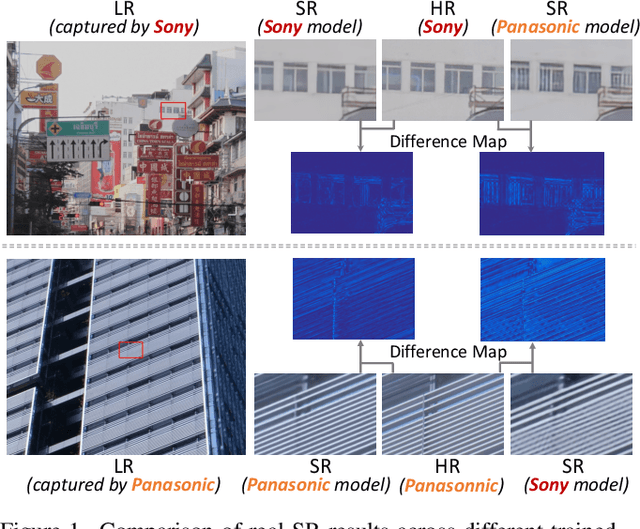
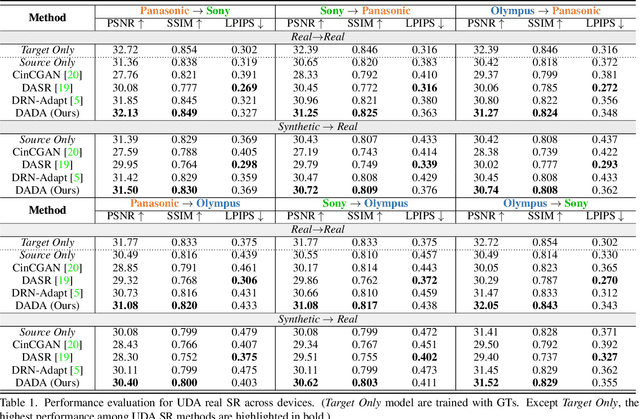
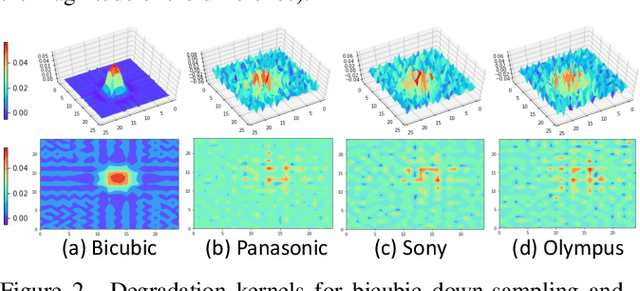
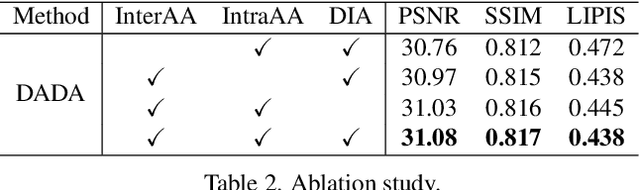
Due to the sophisticated imaging process, an identical scene captured by different cameras could exhibit distinct imaging patterns, introducing distinct proficiency among the super-resolution (SR) models trained on images from different devices. In this paper, we investigate a novel and practical task coded cross-device SR, which strives to adapt a real-world SR model trained on the paired images captured by one camera to low-resolution (LR) images captured by arbitrary target devices. The proposed task is highly challenging due to the absence of paired data from various imaging devices. To address this issue, we propose an unsupervised domain adaptation mechanism for real-world SR, named Dual ADversarial Adaptation (DADA), which only requires LR images in the target domain with available real paired data from a source camera. DADA employs the Domain-Invariant Attention (DIA) module to establish the basis of target model training even without HR supervision. Furthermore, the dual framework of DADA facilitates an Inter-domain Adversarial Adaptation (InterAA) in one branch for two LR input images from two domains, and an Intra-domain Adversarial Adaptation (IntraAA) in two branches for an LR input image. InterAA and IntraAA together improve the model transferability from the source domain to the target. We empirically conduct experiments under six Real to Real adaptation settings among three different cameras, and achieve superior performance compared with existing state-of-the-art approaches. We also evaluate the proposed DADA to address the adaptation to the video camera, which presents a promising research topic to promote the wide applications of real-world super-resolution. Our source code is publicly available at https://github.com/lonelyhope/DADA.git.