 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepoTransBench: A Real-World Benchmark for Repository-Level Code Translation
Dec 23, 2024



Repository-level code translation refers to translating an entire code repository from one programming language to another while preserving the functionality of the source repository. Many benchmarks have been proposed to evaluate the performance of such code translators. However, previous benchmarks mostly provide fine-grained samples, focusing at either code snippet, function, or file-level code translation. Such benchmarks do not accurately reflect real-world demands, where entire repositories often need to be translated, involving longer code length and more complex functionalities. To address this gap, we propose a new benchmark, named RepoTransBench, which is a real-world repository-level code translation benchmark with an automatically executable test suite. We conduct experiments on RepoTransBench to evaluate the translation performance of 11 advanced LLMs. We find that the Success@1 score (test success in one attempt) of the best-performing LLM is only 7.33%. To further explore the potential of LLMs for repository-level code translation, we provide LLMs with error-related feedback to perform iterative debugging and observe an average 7.09% improvement on Success@1. However, even with this improvement, the Success@1 score of the best-performing LLM is only 21%, which may not meet the need for reliable automatic repository-level code translation. Finally, we conduct a detailed error analysis and highlight current LLMs' deficiencies in repository-level code translation, which could provide a reference for further improvements.
Dual Adversarial Adaptation for Cross-Device Real-World Image Super-Resolution
May 07, 2022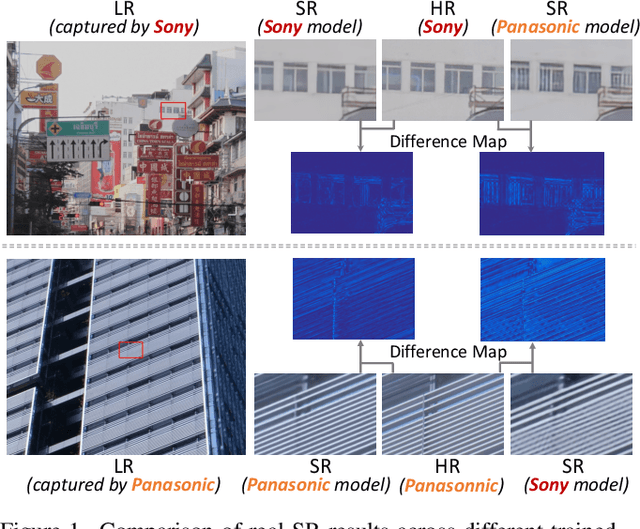
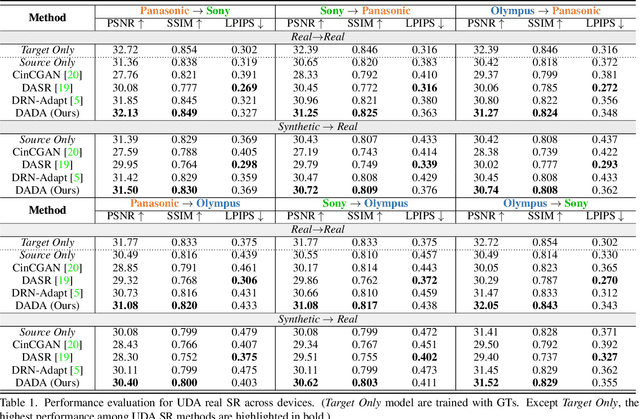
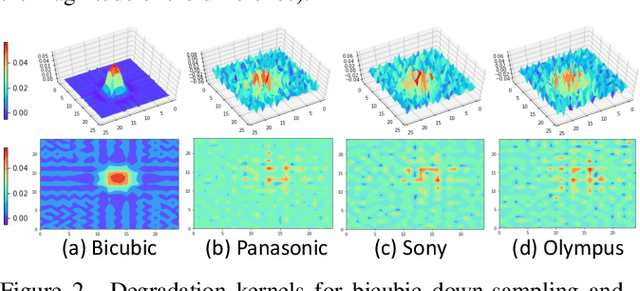
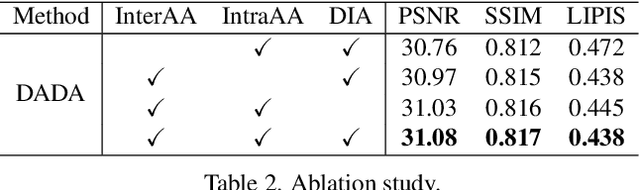
Due to the sophisticated imaging process, an identical scene captured by different cameras could exhibit distinct imaging patterns, introducing distinct proficiency among the super-resolution (SR) models trained on images from different devices. In this paper, we investigate a novel and practical task coded cross-device SR, which strives to adapt a real-world SR model trained on the paired images captured by one camera to low-resolution (LR) images captured by arbitrary target devices. The proposed task is highly challenging due to the absence of paired data from various imaging devices. To address this issue, we propose an unsupervised domain adaptation mechanism for real-world SR, named Dual ADversarial Adaptation (DADA), which only requires LR images in the target domain with available real paired data from a source camera. DADA employs the Domain-Invariant Attention (DIA) module to establish the basis of target model training even without HR supervision. Furthermore, the dual framework of DADA facilitates an Inter-domain Adversarial Adaptation (InterAA) in one branch for two LR input images from two domains, and an Intra-domain Adversarial Adaptation (IntraAA) in two branches for an LR input image. InterAA and IntraAA together improve the model transferability from the source domain to the target. We empirically conduct experiments under six Real to Real adaptation settings among three different cameras, and achieve superior performance compared with existing state-of-the-art approaches. We also evaluate the proposed DADA to address the adaptation to the video camera, which presents a promising research topic to promote the wide applications of real-world super-resolution. Our source code is publicly available at https://github.com/lonelyhope/DADA.git.
Defeats GAN: A Simpler Model Outperforms in Knowledge Representation Learning
Apr 03, 2019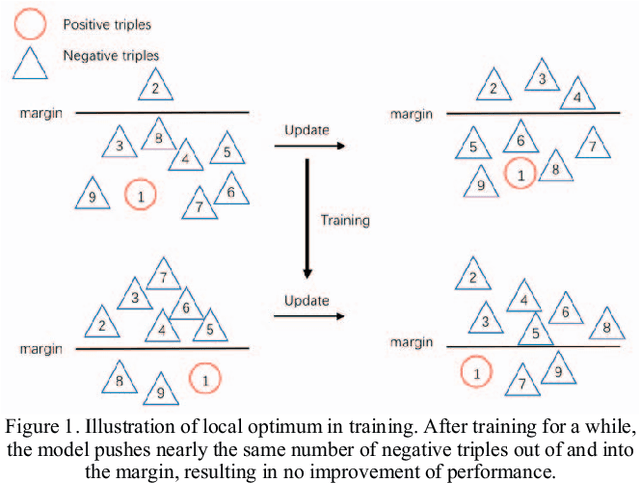
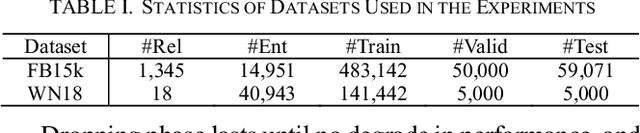
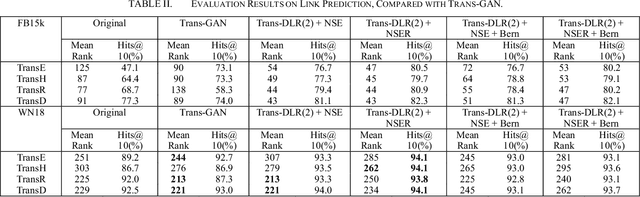
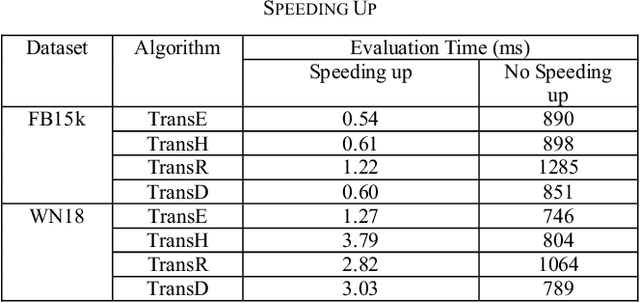
The goal of knowledge representation learning is to embed entities and relations into a low-dimensional, continuous vector space. How to push a model to its limit and obtain better results is of great significance in knowledge graph's applications. We propose a simple and elegant method, Trans-DLR, whose main idea is dynamic learning rate control during training. Our method achieves remarkable improvement, compared with recent GAN-based method. Moreover, we introduce a new negative sampling trick which corrupts not only entities, but also relations, in different probabilities. We also develop an efficient way, which fully utilizes multiprocessing and parallel computing, to speed up evaluation of the model in link prediction tasks. Experiments show that our method is effective.
* 5 pages, 1 figure, has been accepted as a conference paper of the 3rd IEEE International Conference on Computational Intelligence and Applications (ICCIA 2018)