 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGO-NeRF: Generating Virtual Objects in Neural Radiance Fields
Jan 11, 2024



Despite advances in 3D generation, the direct creation of 3D objects within an existing 3D scene represented as NeRF remains underexplored. This process requires not only high-quality 3D object generation but also seamless composition of the generated 3D content into the existing NeRF. To this end, we propose a new method, GO-NeRF, capable of utilizing scene context for high-quality and harmonious 3D object generation within an existing NeRF. Our method employs a compositional rendering formulation that allows the generated 3D objects to be seamlessly composited into the scene utilizing learned 3D-aware opacity maps without introducing unintended scene modification. Moreover, we also develop tailored optimization objectives and training strategies to enhance the model's ability to exploit scene context and mitigate artifacts, such as floaters, originating from 3D object generation within a scene. Extensive experiments on both feed-forward and $360^o$ scenes show the superior performance of our proposed GO-NeRF in generating objects harmoniously composited with surrounding scenes and synthesizing high-quality novel view images. Project page at {\url{https://daipengwa.github.io/GO-NeRF/}.
Random resistive memory-based deep extreme point learning machine for unified visual processing
Dec 14, 2023



Visual sensors, including 3D LiDAR, neuromorphic DVS sensors, and conventional frame cameras, are increasingly integrated into edge-side intelligent machines. Realizing intensive multi-sensory data analysis directly on edge intelligent machines is crucial for numerous emerging edge applications, such as augmented and virtual reality and unmanned aerial vehicles, which necessitates unified data representation, unprecedented hardware energy efficiency and rapid model training. However, multi-sensory data are intrinsically heterogeneous, causing significant complexity in the system development for edge-side intelligent machines. In addition, the performance of conventional digital hardware is limited by the physically separated processing and memory units, known as the von Neumann bottleneck, and the physical limit of transistor scaling, which contributes to the slowdown of Moore's law. These limitations are further intensified by the tedious training of models with ever-increasing sizes. We propose a novel hardware-software co-design, random resistive memory-based deep extreme point learning machine (DEPLM), that offers efficient unified point set analysis. We show the system's versatility across various data modalities and two different learning tasks. Compared to a conventional digital hardware-based system, our co-design system achieves huge energy efficiency improvements and training cost reduction when compared to conventional systems. Our random resistive memory-based deep extreme point learning machine may pave the way for energy-efficient and training-friendly edge AI across various data modalities and tasks.
Texture Generation on 3D Meshes with Point-UV Diffusion
Aug 21, 2023



In this work, we focus on synthesizing high-quality textures on 3D meshes. We present Point-UV diffusion, a coarse-to-fine pipeline that marries the denoising diffusion model with UV mapping to generate 3D consistent and high-quality texture images in UV space. We start with introducing a point diffusion model to synthesize low-frequency texture components with our tailored style guidance to tackle the biased color distribution. The derived coarse texture offers global consistency and serves as a condition for the subsequent UV diffusion stage, aiding in regularizing the model to generate a 3D consistent UV texture image. Then, a UV diffusion model with hybrid conditions is developed to enhance the texture fidelity in the 2D UV space. Our method can process meshes of any genus, generating diversified, geometry-compatible, and high-fidelity textures. Code is available at https://cvmi-lab.github.io/Point-UV-Diffusion
Hybrid Neural Rendering for Large-Scale Scenes with Motion Blur
Apr 25, 2023



Rendering novel view images is highly desirable for many applications. Despite recent progress, it remains challenging to render high-fidelity and view-consistent novel views of large-scale scenes from in-the-wild images with inevitable artifacts (e.g., motion blur). To this end, we develop a hybrid neural rendering model that makes image-based representation and neural 3D representation join forces to render high-quality, view-consistent images. Besides, images captured in the wild inevitably contain artifacts, such as motion blur, which deteriorates the quality of rendered images. Accordingly, we propose strategies to simulate blur effects on the rendered images to mitigate the negative influence of blurriness images and reduce their importance during training based on precomputed quality-aware weights. Extensive experiments on real and synthetic data demonstrate our model surpasses state-of-the-art point-based methods for novel view synthesis. The code is available at https://daipengwa.github.io/Hybrid-Rendering-ProjectPage.
ISS++: Image as Stepping Stone for Text-Guided 3D Shape Generation
Mar 24, 2023



In this paper, we present a new text-guided 3D shape generation approach (ISS++) that uses images as a stepping stone to bridge the gap between text and shape modalities for generating 3D shapes without requiring paired text and 3D data. The core of our approach is a two-stage feature-space alignment strategy that leverages a pre-trained single-view reconstruction (SVR) model to map CLIP features to shapes: to begin with, map the CLIP image feature to the detail-rich 3D shape space of the SVR model, then map the CLIP text feature to the 3D shape space through encouraging the CLIP-consistency between rendered images and the input text. Besides, to extend beyond the generative capability of the SVR model, we design a text-guided 3D shape stylization module that can enhance the output shapes with novel structures and textures. Further, we exploit pre-trained text-to-image diffusion models to enhance the generative diversity, fidelity, and stylization capability. Our approach is generic, flexible, and scalable, and it can be easily integrated with various SVR models to expand the generative space and improve the generative fidelity. Extensive experimental results demonstrate that our approach outperforms the state-of-the-art methods in terms of generative quality and consistency with the input text. Codes and models are released at https://github.com/liuzhengzhe/ISS-Image-as-Stepping-Stone-for-Text-Guided-3D-Shape-Generation.
Learning a Room with the Occ-SDF Hybrid: Signed Distance Function Mingled with Occupancy Aids Scene Representation
Mar 16, 2023



Implicit neural rendering, which uses signed distance function (SDF) representation with geometric priors (such as depth or surface normal), has led to impressive progress in the surface reconstruction of large-scale scenes. However, applying this method to reconstruct a room-level scene from images may miss structures in low-intensity areas or small and thin objects. We conducted experiments on three datasets to identify limitations of the original color rendering loss and priors-embedded SDF scene representation. We found that the color rendering loss results in optimization bias against low-intensity areas, causing gradient vanishing and leaving these areas unoptimized. To address this issue, we propose a feature-based color rendering loss that utilizes non-zero feature values to bring back optimization signals. Additionally, the SDF representation can be influenced by objects along a ray path, disrupting the monotonic change of SDF values when a single object is present. To counteract this, we explore using the occupancy representation, which encodes each point separately and is unaffected by objects along a querying ray. Our experimental results demonstrate that the joint forces of the feature-based rendering loss and Occ-SDF hybrid representation scheme can provide high-quality reconstruction results, especially in challenging room-level scenarios. The code would be released.
Multi-Behavior Graph Neural Networks for Recommender System
Feb 17, 2023Recommender systems have been demonstrated to be effective to meet user's personalized interests for many online services (e.g., E-commerce and online advertising platforms). Recent years have witnessed the emerging success of many deep learning-based recommendation models for augmenting collaborative filtering architectures with various neural network architectures, such as multi-layer perceptron and autoencoder. However, the majority of them model the user-item relationship with single type of interaction, while overlooking the diversity of user behaviors on interacting with items, which can be click, add-to-cart, tag-as-favorite and purchase. Such various types of interaction behaviors have great potential in providing rich information for understanding the user preferences. In this paper, we pay special attention on user-item relationships with the exploration of multi-typed user behaviors. Technically, we contribute a new multi-behavior graph neural network (MBRec), which specially accounts for diverse interaction patterns as well as the underlying cross-type behavior inter-dependencies. In the MBRec framework, we develop a graph-structured learning framework to perform expressive modeling of high-order connectivity in behavior-aware user-item interaction graph. After that, a mutual relation encoder is proposed to adaptively uncover complex relational structures and make aggregations across layer-specific behavior representations. Through comprehensive evaluation on real-world datasets, the advantages of our MBRec method have been validated under different experimental settings. Further analysis verifies the positive effects of incorporating the multi-behavioral context into the recommendation paradigm. Additionally, the conducted case studies offer insights into the interpretability of user multi-behavior representations.
ISS: Image as Stepping Stone for Text-Guided 3D Shape Generation
Sep 22, 2022

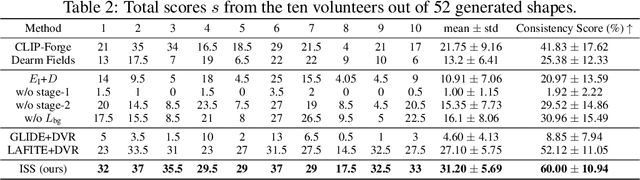

Text-guided 3D shape generation remains challenging due to the absence of large paired text-shape data, the substantial semantic gap between these two modalities, and the structural complexity of 3D shapes. This paper presents a new framework called Image as Stepping Stone (ISS) for the task by introducing 2D image as a stepping stone to connect the two modalities and to eliminate the need for paired text-shape data. Our key contribution is a two-stage feature-space-alignment approach that maps CLIP features to shapes by harnessing a pre-trained single-view reconstruction (SVR) model with multi-view supervisions: first map the CLIP image feature to the detail-rich shape space in the SVR model, then map the CLIP text feature to the shape space and optimize the mapping by encouraging CLIP consistency between the input text and the rendered images. Further, we formulate a text-guided shape stylization module to dress up the output shapes with novel textures. Beyond existing works on 3D shape generation from text, our new approach is general for creating shapes in a broad range of categories, without requiring paired text-shape data. Experimental results manifest that our approach outperforms the state-of-the-arts and our baselines in terms of fidelity and consistency with text. Further, our approach can stylize the generated shapes with both realistic and fantasy structures and textures.
Towards Efficient and Scale-Robust Ultra-High-Definition Image Demoireing
Jul 20, 2022


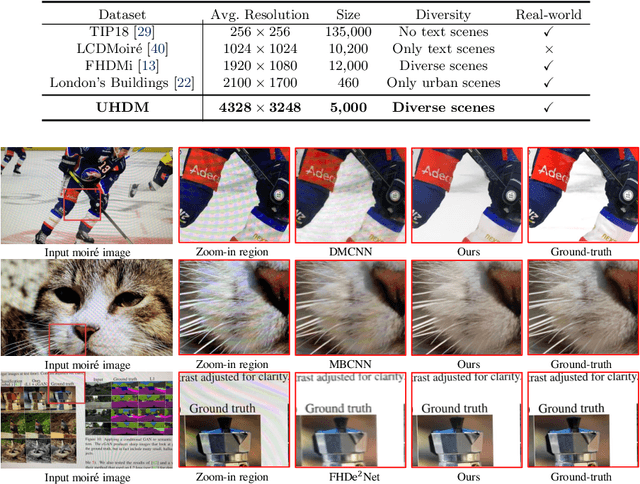
With the rapid development of mobile devices, modern widely-used mobile phones typically allow users to capture 4K resolution (i.e., ultra-high-definition) images. However, for image demoireing, a challenging task in low-level vision, existing works are generally carried out on low-resolution or synthetic images. Hence, the effectiveness of these methods on 4K resolution images is still unknown. In this paper, we explore moire pattern removal for ultra-high-definition images. To this end, we propose the first ultra-high-definition demoireing dataset (UHDM), which contains 5,000 real-world 4K resolution image pairs, and conduct a benchmark study on current state-of-the-art methods. Further, we present an efficient baseline model ESDNet for tackling 4K moire images, wherein we build a semantic-aligned scale-aware module to address the scale variation of moire patterns. Extensive experiments manifest the effectiveness of our approach, which outperforms state-of-the-art methods by a large margin while being much more lightweight. Code and dataset are available at https://xinyu-andy.github.io/uhdm-page.
Joint Spatial-Temporal and Appearance Modeling with Transformer for Multiple Object Tracking
May 31, 2022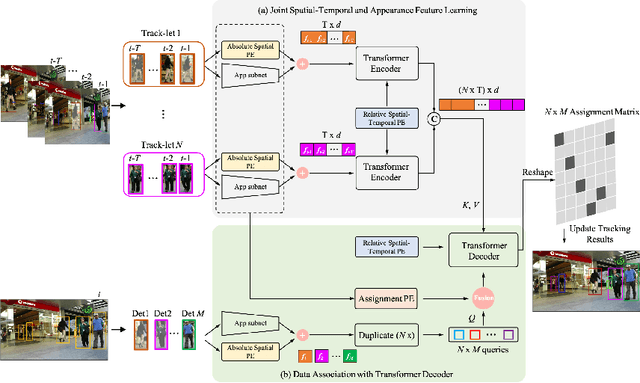

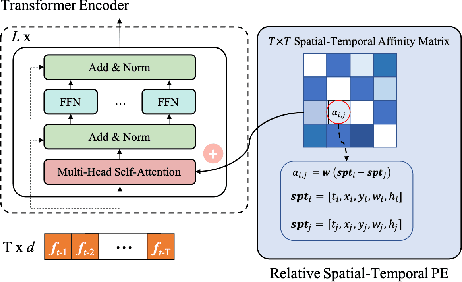
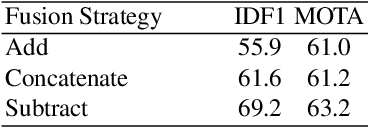
The recent trend in multiple object tracking (MOT) is heading towards leveraging deep learning to boost the tracking performance. In this paper, we propose a novel solution named TransSTAM, which leverages Transformer to effectively model both the appearance features of each object and the spatial-temporal relationships among objects. TransSTAM consists of two major parts: (1) The encoder utilizes the powerful self-attention mechanism of Transformer to learn discriminative features for each tracklet; (2) The decoder adopts the standard cross-attention mechanism to model the affinities between the tracklets and the detections by taking both spatial-temporal and appearance features into account. TransSTAM has two major advantages: (1) It is solely based on the encoder-decoder architecture and enjoys a compact network design, hence being computationally efficient; (2) It can effectively learn spatial-temporal and appearance features within one model, hence achieving better tracking accuracy. The proposed method is evaluated on multiple public benchmarks including MOT16, MOT17, and MOT20, and it achieves a clear performance improvement in both IDF1 and HOTA with respect to previous state-of-the-art approaches on all the benchmarks. Our code is available at \url{https://github.com/icicle4/TranSTAM}.