 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgocentric Visibility-Aware Human Pose Estimation
Feb 27, 2026Egocentric human pose estimation (HPE) using a head-mounted device is crucial for various VR and AR applications, but it faces significant challenges due to keypoint invisibility. Nevertheless, none of the existing egocentric HPE datasets provide keypoint visibility annotations, and the existing methods often overlook the invisibility problem, treating visible and invisible keypoints indiscriminately during estimation. As a result, their capacity to accurately predict visible keypoints is compromised. In this paper, we first present Eva-3M, a large-scale egocentric visibility-aware HPE dataset comprising over 3.0M frames, with 435K of them annotated with keypoint visibility labels. Additionally, we augment the existing EMHI dataset with keypoint visibility annotations to further facilitate the research in this direction. Furthermore, we propose EvaPose, a novel egocentric visibility-aware HPE method that explicitly incorporates visibility information to enhance pose estimation accuracy. Extensive experiments validate the significant value of ground-truth visibility labels in egocentric HPE settings, and demonstrate that our EvaPose achieves state-of-the-art performance in both Eva-3M and EMHI datasets.
PartCrafter: Structured 3D Mesh Generation via Compositional Latent Diffusion Transformers
Jun 05, 2025We introduce PartCrafter, the first structured 3D generative model that jointly synthesizes multiple semantically meaningful and geometrically distinct 3D meshes from a single RGB image. Unlike existing methods that either produce monolithic 3D shapes or follow two-stage pipelines, i.e., first segmenting an image and then reconstructing each segment, PartCrafter adopts a unified, compositional generation architecture that does not rely on pre-segmented inputs. Conditioned on a single image, it simultaneously denoises multiple 3D parts, enabling end-to-end part-aware generation of both individual objects and complex multi-object scenes. PartCrafter builds upon a pretrained 3D mesh diffusion transformer (DiT) trained on whole objects, inheriting the pretrained weights, encoder, and decoder, and introduces two key innovations: (1) A compositional latent space, where each 3D part is represented by a set of disentangled latent tokens; (2) A hierarchical attention mechanism that enables structured information flow both within individual parts and across all parts, ensuring global coherence while preserving part-level detail during generation. To support part-level supervision, we curate a new dataset by mining part-level annotations from large-scale 3D object datasets. Experiments show that PartCrafter outperforms existing approaches in generating decomposable 3D meshes, including parts that are not directly visible in input images, demonstrating the strength of part-aware generative priors for 3D understanding and synthesis. Code and training data will be released.
Joint Spatial-Temporal and Appearance Modeling with Transformer for Multiple Object Tracking
May 31, 2022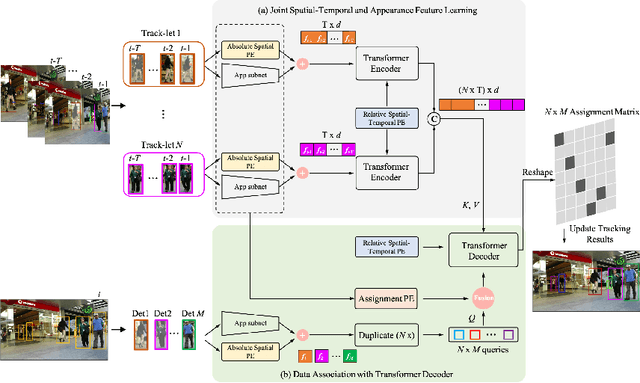

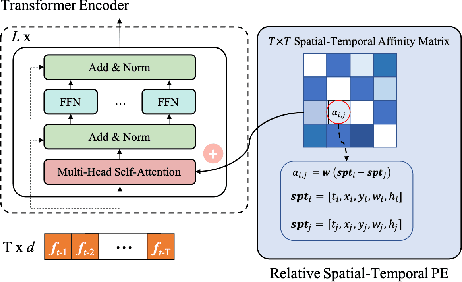
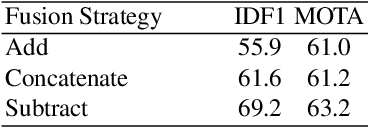
The recent trend in multiple object tracking (MOT) is heading towards leveraging deep learning to boost the tracking performance. In this paper, we propose a novel solution named TransSTAM, which leverages Transformer to effectively model both the appearance features of each object and the spatial-temporal relationships among objects. TransSTAM consists of two major parts: (1) The encoder utilizes the powerful self-attention mechanism of Transformer to learn discriminative features for each tracklet; (2) The decoder adopts the standard cross-attention mechanism to model the affinities between the tracklets and the detections by taking both spatial-temporal and appearance features into account. TransSTAM has two major advantages: (1) It is solely based on the encoder-decoder architecture and enjoys a compact network design, hence being computationally efficient; (2) It can effectively learn spatial-temporal and appearance features within one model, hence achieving better tracking accuracy. The proposed method is evaluated on multiple public benchmarks including MOT16, MOT17, and MOT20, and it achieves a clear performance improvement in both IDF1 and HOTA with respect to previous state-of-the-art approaches on all the benchmarks. Our code is available at \url{https://github.com/icicle4/TranSTAM}.