 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Select Datapoints for Efficient Human Evaluation of NLG Models?
Jan 30, 2025



Human evaluation is the gold-standard for evaluating text generation models. It is also expensive, and to fit budgetary constraints, a random subset of the test data is often chosen in practice. The randomly selected data may not accurately represent test performance, making this approach economically inefficient for model comparison. Thus, in this work, we develop a suite of selectors to get the most informative datapoints for human evaluation while taking the evaluation costs into account. We show that selectors based on variance in automated metric scores, diversity in model outputs, or Item Response Theory outperform random selection. We further develop an approach to distill these selectors to the scenario where the model outputs are not yet available. In particular, we introduce source-based estimators, which predict item usefulness for human evaluation just based on the source texts. We demonstrate the efficacy of our selectors in two common NLG tasks, machine translation and summarization, and show that up to only ~50% of the test data is needed to produce the same evaluation result as the entire data. Our implementations are published in the subset2evaluate package.
Exploring Aleatoric Uncertainty in Object Detection via Vision Foundation Models
Nov 26, 2024



Datasets collected from the open world unavoidably suffer from various forms of randomness or noiseness, leading to the ubiquity of aleatoric (data) uncertainty. Quantifying such uncertainty is particularly pivotal for object detection, where images contain multi-scale objects with occlusion, obscureness, and even noisy annotations, in contrast to images with centric and similar-scale objects in classification. This paper suggests modeling and exploiting the uncertainty inherent in object detection data with vision foundation models and develops a data-centric reliable training paradigm. Technically, we propose to estimate the data uncertainty of each object instance based on the feature space of vision foundation models, which are trained on ultra-large-scale datasets and able to exhibit universal data representation. In particular, we assume a mixture-of-Gaussian structure of the object features and devise Mahalanobis distance-based measures to quantify the data uncertainty. Furthermore, we suggest two curial and practical usages of the estimated uncertainty: 1) for defining uncertainty-aware sample filter to abandon noisy and redundant instances to avoid over-fitting, and 2) for defining sample adaptive regularizer to balance easy/hard samples for adaptive training. The estimated aleatoric uncertainty serves as an extra level of annotations of the dataset, so it can be utilized in a plug-and-play manner with any model. Extensive empirical studies verify the effectiveness of the proposed aleatoric uncertainty measure on various advanced detection models and challenging benchmarks.
LDACP: Long-Delayed Ad Conversions Prediction Model for Bidding Strategy
Nov 25, 2024



In online advertising, once an ad campaign is deployed, the automated bidding system dynamically adjusts the bidding strategy to optimize Cost Per Action (CPA) based on the number of ad conversions. For ads with a long conversion delay, relying solely on the real-time tracked conversion number as a signal for bidding strategy can significantly overestimate the current CPA, leading to conservative bidding strategies. Therefore, it is crucial to predict the number of long-delayed conversions. Nonetheless, it is challenging to predict ad conversion numbers through traditional regression methods due to the wide range of ad conversion numbers. Previous regression works have addressed this challenge by transforming regression problems into bucket classification problems, achieving success in various scenarios. However, specific challenges arise when predicting the number of ad conversions: 1) The integer nature of ad conversion numbers exacerbates the discontinuity issue in one-hot hard labels; 2) The long-tail distribution of ad conversion numbers complicates tail data prediction. In this paper, we propose the Long-Delayed Ad Conversions Prediction model for bidding strategy (LDACP), which consists of two sub-modules. To alleviate the issue of discontinuity in one-hot hard labels, the Bucket Classification Module with label Smoothing method (BCMS) converts one-hot hard labels into non-normalized soft labels, then fits these soft labels by minimizing classification loss and regression loss. To address the challenge of predicting tail data, the Value Regression Module with Proxy labels (VRMP) uses the prediction bias of aggregated pCTCVR as proxy labels. Finally, a Mixture of Experts (MoE) structure integrates the predictions from BCMS and VRMP to obtain the final predicted ad conversion number.
How to Engage Your Readers? Generating Guiding Questions to Promote Active Reading
Jul 19, 2024Using questions in written text is an effective strategy to enhance readability. However, what makes an active reading question good, what the linguistic role of these questions is, and what is their impact on human reading remains understudied. We introduce GuidingQ, a dataset of 10K in-text questions from textbooks and scientific articles. By analyzing the dataset, we present a comprehensive understanding of the use, distribution, and linguistic characteristics of these questions. Then, we explore various approaches to generate such questions using language models. Our results highlight the importance of capturing inter-question relationships and the challenge of question position identification in generating these questions. Finally, we conduct a human study to understand the implication of such questions on reading comprehension. We find that the generated questions are of high quality and are almost as effective as human-written questions in terms of improving readers' memorization and comprehension.
Topology-Aware Dynamic Reweighting for Distribution Shifts on Graph
Jun 03, 2024



Graph Neural Networks (GNNs) are widely used for node classification tasks but often fail to generalize when training and test nodes come from different distributions, limiting their practicality. To overcome this, recent approaches adopt invariant learning techniques from the out-of-distribution (OOD) generalization field, which seek to establish stable prediction methods across environments. However, the applicability of these invariant assumptions to graph data remains unverified, and such methods often lack solid theoretical support. In this work, we introduce the Topology-Aware Dynamic Reweighting (TAR) framework, which dynamically adjusts sample weights through gradient flow in the geometric Wasserstein space during training. Instead of relying on strict invariance assumptions, we prove that our method is able to provide distributional robustness, thereby enhancing the out-of-distribution generalization performance on graph data. By leveraging the inherent graph structure, TAR effectively addresses distribution shifts. Our framework's superiority is demonstrated through standard testing on four graph OOD datasets and three class-imbalanced node classification datasets, exhibiting marked improvements over existing methods.
Bridging Multicalibration and Out-of-distribution Generalization Beyond Covariate Shift
Jun 02, 2024



We establish a new model-agnostic optimization framework for out-of-distribution generalization via multicalibration, a criterion that ensures a predictor is calibrated across a family of overlapping groups. Multicalibration is shown to be associated with robustness of statistical inference under covariate shift. We further establish a link between multicalibration and robustness for prediction tasks both under and beyond covariate shift. We accomplish this by extending multicalibration to incorporate grouping functions that consider covariates and labels jointly. This leads to an equivalence of the extended multicalibration and invariance, an objective for robust learning in existence of concept shift. We show a linear structure of the grouping function class spanned by density ratios, resulting in a unifying framework for robust learning by designing specific grouping functions. We propose MC-Pseudolabel, a post-processing algorithm to achieve both extended multicalibration and out-of-distribution generalization. The algorithm, with lightweight hyperparameters and optimization through a series of supervised regression steps, achieves superior performance on real-world datasets with distribution shift.
Accurate and Reliable Predictions with Mutual-Transport Ensemble
May 30, 2024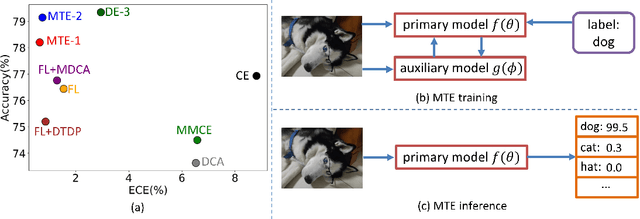
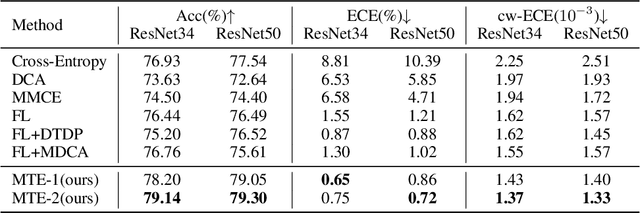
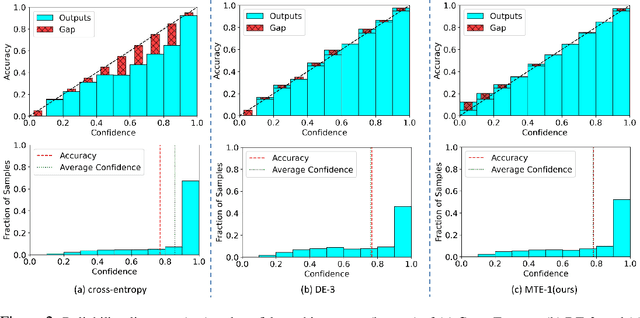
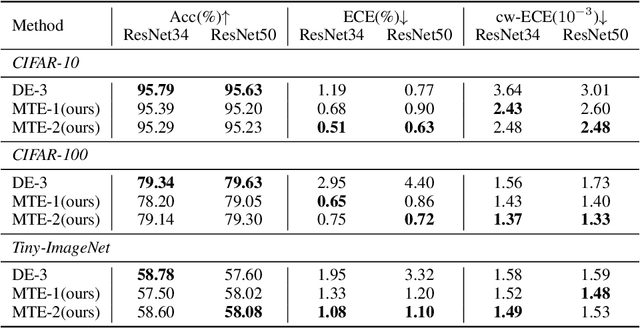
Deep Neural Networks (DNNs) have achieved remarkable success in a variety of tasks, especially when it comes to prediction accuracy. However, in complex real-world scenarios, particularly in safety-critical applications, high accuracy alone is not enough. Reliable uncertainty estimates are crucial. Modern DNNs, often trained with cross-entropy loss, tend to be overconfident, especially with ambiguous samples. To improve uncertainty calibration, many techniques have been developed, but they often compromise prediction accuracy. To tackle this challenge, we propose the ``mutual-transport ensemble'' (MTE). This approach introduces a co-trained auxiliary model and adaptively regularizes the cross-entropy loss using Kullback-Leibler (KL) divergence between the prediction distributions of the primary and auxiliary models. We conducted extensive studies on various benchmarks to validate the effectiveness of our method. The results show that MTE can simultaneously enhance both accuracy and uncertainty calibration. For example, on the CIFAR-100 dataset, our MTE method on ResNet34/50 achieved significant improvements compared to previous state-of-the-art method, with absolute accuracy increases of 2.4%/3.7%, relative reductions in ECE of $42.3%/29.4%, and relative reductions in classwise-ECE of 11.6%/15.3%.
Stability Evaluation via Distributional Perturbation Analysis
May 06, 2024



The performance of learning models often deteriorates when deployed in out-of-sample environments. To ensure reliable deployment, we propose a stability evaluation criterion based on distributional perturbations. Conceptually, our stability evaluation criterion is defined as the minimal perturbation required on our observed dataset to induce a prescribed deterioration in risk evaluation. In this paper, we utilize the optimal transport (OT) discrepancy with moment constraints on the \textit{(sample, density)} space to quantify this perturbation. Therefore, our stability evaluation criterion can address both \emph{data corruptions} and \emph{sub-population shifts} -- the two most common types of distribution shifts in real-world scenarios. To further realize practical benefits, we present a series of tractable convex formulations and computational methods tailored to different classes of loss functions. The key technical tool to achieve this is the strong duality theorem provided in this paper. Empirically, we validate the practical utility of our stability evaluation criterion across a host of real-world applications. These empirical studies showcase the criterion's ability not only to compare the stability of different learning models and features but also to provide valuable guidelines and strategies to further improve models.
Debiased Collaborative Filtering with Kernel-Based Causal Balancing
Apr 30, 2024Debiased collaborative filtering aims to learn an unbiased prediction model by removing different biases in observational datasets. To solve this problem, one of the simple and effective methods is based on the propensity score, which adjusts the observational sample distribution to the target one by reweighting observed instances. Ideally, propensity scores should be learned with causal balancing constraints. However, existing methods usually ignore such constraints or implement them with unreasonable approximations, which may affect the accuracy of the learned propensity scores. To bridge this gap, in this paper, we first analyze the gaps between the causal balancing requirements and existing methods such as learning the propensity with cross-entropy loss or manually selecting functions to balance. Inspired by these gaps, we propose to approximate the balancing functions in reproducing kernel Hilbert space and demonstrate that, based on the universal property and representer theorem of kernel functions, the causal balancing constraints can be better satisfied. Meanwhile, we propose an algorithm that adaptively balances the kernel function and theoretically analyze the generalization error bound of our methods. We conduct extensive experiments to demonstrate the effectiveness of our methods, and to promote this research direction, we have released our project at https://github.com/haoxuanli-pku/ICLR24-Kernel-Balancing.
PPA-Game: Characterizing and Learning Competitive Dynamics Among Online Content Creators
Mar 22, 2024



We introduce the Proportional Payoff Allocation Game (PPA-Game) to model how agents, akin to content creators on platforms like YouTube and TikTok, compete for divisible resources and consumers' attention. Payoffs are allocated to agents based on heterogeneous weights, reflecting the diversity in content quality among creators. Our analysis reveals that although a pure Nash equilibrium (PNE) is not guaranteed in every scenario, it is commonly observed, with its absence being rare in our simulations. Beyond analyzing static payoffs, we further discuss the agents' online learning about resource payoffs by integrating a multi-player multi-armed bandit framework. We propose an online algorithm facilitating each agent's maximization of cumulative payoffs over $T$ rounds. Theoretically, we establish that the regret of any agent is bounded by $O(\log^{1 + \eta} T)$ for any $\eta > 0$. Empirical results further validate the effectiveness of our approach.