 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecommendation as Generation: Unifying Personalized Video Generation and Recommendation at Industrial Scale
Jun 24, 2026Traditional short-video recommendation systems match user interest to a fixed pool of pre-produced videos, which limits their ability to capture fine-grained and dynamic preferences. We propose Recommendation-as-Generation (RaG), a new paradigm that generates personalized videos on demand from inferred user interest. Our framework unifies generative recommendation and video generation through shared semantic IDs (SIDs), which disentangle video representation into content semantics and creative style semantics, enabling both fine-grained modeling of user interest and controllable generation of interest-aligned videos. We further develop Video Generation Agents (VGAs) that are conditioned on inferred SIDs to drive hierarchical planning and refinement for video creation, including visual composition, audio alignment, and artistic effect enhancement. To optimize the framework, we effectively introduce a synergistic cross-domain reward learning mechanism that jointly enforces interest alignment, user feedback, and video quality assessment. We deploy RaG on an industrial-scale platform with over 400 million daily active users and evaluate it in a revenue-critical advertising scenario. Online A/B tests show up to 1.87% ad revenue improvement compared to a strong production GRM baseline, demonstrating its effectiveness in driving further revenue gains beyond generative recommendation. Our results highlight a closed-loop generative system as a promising paradigm for integrating personalized video generation into recommendation.
Generative Recommendation for Large-Scale Advertising
Feb 26, 2026Generative recommendation has recently attracted widespread attention in industry due to its potential for scaling and stronger model capacity. However, deploying real-time generative recommendation in large-scale advertising requires designs beyond large-language-model (LLM)-style training and serving recipes. We present a production-oriented generative recommender co-designed across architecture, learning, and serving, named GR4AD (Generative Recommendation for ADdvertising). As for tokenization, GR4AD proposes UA-SID (Unified Advertisement Semantic ID) to capture complicated business information. Furthermore, GR4AD introduces LazyAR, a lazy autoregressive decoder that relaxes layer-wise dependencies for short, multi-candidate generation, preserving effectiveness while reducing inference cost, which facilitates scaling under fixed serving budgets. To align optimization with business value, GR4AD employs VSL (Value-Aware Supervised Learning) and proposes RSPO (Ranking-Guided Softmax Preference Optimization), a ranking-aware, list-wise reinforcement learning algorithm that optimizes value-based rewards under list-level metrics for continual online updates. For online inference, we further propose dynamic beam serving, which adapts beam width across generation levels and online load to control compute. Large-scale online A/B tests show up to 4.2% ad revenue improvement over an existing DLRM-based stack, with consistent gains from both model scaling and inference-time scaling. GR4AD has been fully deployed in Kuaishou advertising system with over 400 million users and achieves high-throughput real-time serving.
Punctuation-aware Hybrid Trainable Sparse Attention for Large Language Models
Jan 06, 2026Attention serves as the fundamental mechanism for long-context modeling in large language models (LLMs), yet dense attention becomes structurally prohibitive for long sequences due to its quadratic complexity. Consequently, sparse attention has received increasing attention as a scalable alternative. However, existing sparse attention methods rely on coarse-grained semantic representations during block selection, which blur intra-block semantic boundaries and lead to the loss of critical information. To address this issue, we propose \textbf{P}unctuation-aware \textbf{H}ybrid \textbf{S}parse \textbf{A}ttention \textbf{(PHSA)}, a natively trainable sparse attention framework that leverages punctuation tokens as semantic boundary anchors. Specifically, (1) we design a dual-branch aggregation mechanism that fuses global semantic representations with punctuation-enhanced boundary features, preserving the core semantic structure while introducing almost no additional computational overhead; (2) we introduce an extreme-sparsity-adaptive training and inference strategy that stabilizes model behavior under very low token activation ratios; Extensive experiments on general benchmarks and long-context evaluations demonstrate that PHSA consistently outperforms dense attention and state-of-the-art sparse attention baselines, including InfLLM v2. Specifically, for the 0.6B-parameter model with 32k-token input sequences, PHSA can reduce the information loss by 10.8\% at a sparsity ratio of 97.3\%.
Personalized Tree based progressive regression model for watch-time prediction in short video recommendation
May 28, 2025In online video platforms, accurate watch time prediction has become a fundamental and challenging problem in video recommendation. Previous research has revealed that the accuracy of watch time prediction highly depends on both the transformation of watch-time labels and the decomposition of the estimation process. TPM (Tree based Progressive Regression Model) achieves State-of-the-Art performance with a carefully designed and effective decomposition paradigm. TPM discretizes the watch time into several ordinal intervals and organizes them into a binary decision tree, where each node corresponds to a specific interval. At each non-leaf node, a binary classifier is used to determine the specific interval in which the watch time variable most likely falls, based on the prediction outcome at its parent node. The tree structure serves as the core of TPM, as it defines the decomposition of watch time estimation and determines how the ordinal intervals are discretized. However, in TPM, the tree is predefined as a full binary tree, which may be sub-optimal for the following reasons. First, a full binary tree implies an equal partitioning of the watch time space, which may struggle to capture the complexity of real-world watch time distributions. Second, instead of relying on a globally fixed tree structure, we advocate for a personalized, data-driven tree that can be learned in an end-to-end manner. Therefore, we propose PTPM to enable a highly personalized decomposition of watch estimation with better efficacy and efficiency. Moreover, we reveal that TPM is affected by selection bias due to conditional modeling and devise a simple approach to address it. We conduct extensive experiments on both offline datasets and online environments. PTPM has been fully deployed in core traffic scenarios and serves more than 400 million users per day.
MTMT: Consolidating Multiple Thinking Modes to Form a Thought Tree for Strengthening LLM
Dec 05, 2024



Large language models (LLMs) have shown limitations in tasks requiring complex logical reasoning and multi-step problem-solving. To address these challenges, researchers have employed carefully designed prompts and flowcharts, simulating human cognitive processes to enhance LLM performance, such as the Chain of Thought approach. In this paper, we introduce MTMT (Multi-thinking Modes Tree), a novel method that interacts with LLMs to construct a thought tree, simulating various advanced cognitive processes, including but not limited to association, counterfactual thinking, task decomposition, and comparison. By breaking down the original complex task into simpler sub-questions, MTMT facilitates easier problem-solving for LLMs, enabling more effective utilization of the latent knowledge within LLMs. We evaluate the performance of MTMT under different parameter configurations, using GPT-4o mini as the base model. Our results demonstrate that integrating multiple modes of thinking significantly enhances the ability of LLMs to handle complex tasks.
LDACP: Long-Delayed Ad Conversions Prediction Model for Bidding Strategy
Nov 25, 2024



In online advertising, once an ad campaign is deployed, the automated bidding system dynamically adjusts the bidding strategy to optimize Cost Per Action (CPA) based on the number of ad conversions. For ads with a long conversion delay, relying solely on the real-time tracked conversion number as a signal for bidding strategy can significantly overestimate the current CPA, leading to conservative bidding strategies. Therefore, it is crucial to predict the number of long-delayed conversions. Nonetheless, it is challenging to predict ad conversion numbers through traditional regression methods due to the wide range of ad conversion numbers. Previous regression works have addressed this challenge by transforming regression problems into bucket classification problems, achieving success in various scenarios. However, specific challenges arise when predicting the number of ad conversions: 1) The integer nature of ad conversion numbers exacerbates the discontinuity issue in one-hot hard labels; 2) The long-tail distribution of ad conversion numbers complicates tail data prediction. In this paper, we propose the Long-Delayed Ad Conversions Prediction model for bidding strategy (LDACP), which consists of two sub-modules. To alleviate the issue of discontinuity in one-hot hard labels, the Bucket Classification Module with label Smoothing method (BCMS) converts one-hot hard labels into non-normalized soft labels, then fits these soft labels by minimizing classification loss and regression loss. To address the challenge of predicting tail data, the Value Regression Module with Proxy labels (VRMP) uses the prediction bias of aggregated pCTCVR as proxy labels. Finally, a Mixture of Experts (MoE) structure integrates the predictions from BCMS and VRMP to obtain the final predicted ad conversion number.
GEAR: Graph-based Evidence Aggregating and Reasoning for Fact Verification
Jul 22, 2019
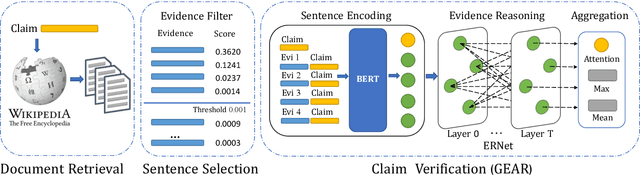
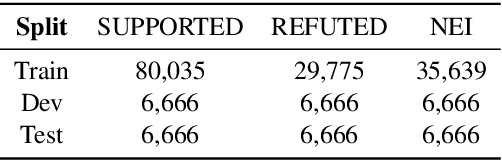
Fact verification (FV) is a challenging task which requires to retrieve relevant evidence from plain text and use the evidence to verify given claims. Many claims require to simultaneously integrate and reason over several pieces of evidence for verification. However, previous work employs simple models to extract information from evidence without letting evidence communicate with each other, e.g., merely concatenate the evidence for processing. Therefore, these methods are unable to grasp sufficient relational and logical information among the evidence. To alleviate this issue, we propose a graph-based evidence aggregating and reasoning (GEAR) framework which enables information to transfer on a fully-connected evidence graph and then utilizes different aggregators to collect multi-evidence information. We further employ BERT, an effective pre-trained language representation model, to improve the performance. Experimental results on a large-scale benchmark dataset FEVER have demonstrated that GEAR could leverage multi-evidence information for FV and thus achieves the promising result with a test FEVER score of 67.10%. Our code is available at https://github.com/thunlp/GEAR.