 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEVRA-BENCH: Social Engineering of Vulnerabilities in Review Agents
Jun 11, 2026Large language model (LLM) reviewers are increasingly used in pull-request (PR) workflows, where their approvals help decide which code is merged into a repository. This raises a question that benchmarks for static vulnerability detection or code generation do not address: can an automated reviewer reject a malicious contribution when the attacker controls both the code change and the accompanying PR text? We introduce SEVRA-BENCH (Social Engineering of Vulnerabilities in Review Agents), a benchmark that measures how often an automated reviewer approves such adversarial pull requests. Each malicious PR in SEVRA-BENCH is built from a real project commit that previously fixed a vulnerability listed in the Common Vulnerabilities and Exposures (CVE) database. We automatically invert that fix to restore the original vulnerable code and submit it as a pull request wrapped in one of 15 social-engineering framings, which vary the claims made, the supporting evidence, the urgency conveyed, signals of prior approval, and appeals to authority. SEVRA-BENCH contains 1,062 malicious PRs drawn from Common Vulnerabilities and Exposures (CVE)-linked fixes across the top 10 entries of the 2025 Common Weakness Enumeration (CWE) Top 25. In a realistic setting, we evaluate 8 current LLMs as code review agents on PRs that introduce vulnerabilities previously reported in public disclosures. Our results reveal a sharp gap in security capabilities between closed- and open-source models. We hope SEVRA-BENCH will serve as a valuable resource for advancing open-source models and narrowing this gap.
What Fits (Into Few Tokens) Doesn't Overfit: Compression and Generalization in ML Research Agents
Jun 09, 2026Reusing a held-out benchmark adaptively should, in principle, invite overfitting. Yet benchmark-driven machine learning (ML) has produced surprisingly little overfitting in practice. An attractive hypothesis is that successful ML strategies are highly compressible. We study this in the setting of LLM-driven research agents, where the hypothesis becomes directly testable via two complementary information bottlenecks. In \emph{output compression}, an exploration agent adaptively searches for high-performance models using a validation set, and we test whether a fresh ``reproducer agent'' can reproduce its performance given only an extremely short prompt and the training data. In \emph{input compression}, the explorer receives only one-bit feedback indicating whether each submitted model improves on the running best. Across 8 datasets spanning tabular classification, vision, language modeling, diffusion modeling, and reward modeling, we find that these bottlenecks have little effect on performance: short prompts and compressible feedback are sufficient to reproduce and find high-performance models. The hypothesis is falsifiable: when we deliberately induce validation-set overfitting, the results fail to reproduce with short prompts. Taken together, our results support a description-length explanation for the lack of overfitting in benchmark-driven ML: successful strategies occupy a low-complexity region of strategy space.
From Curiosity to Caution: Mitigating Reward Hacking for Best-of-N with Pessimism
Apr 06, 2026Inference-time compute scaling has emerged as a powerful paradigm for improving language model performance on a wide range of tasks, but the question of how best to use the additional compute remains open. A popular approach is BoN sampling, where N candidate responses are generated, scored according to a reward model, and the highest-scoring response is selected. While this approach can improve performance, it is vulnerable to reward hacking, where performance degrades as N increases due to the selection of responses that exploit imperfections in the reward model instead of genuinely improving generation quality. Prior attempts to mitigate reward hacking, via stronger reward models or heavy-handed distributional regularization, either fail to fully address over-optimization or are too conservative to exploit additional compute. In this work, we explore the principle of pessimism in RL, which uses lower confidence bounds on value estimates to avoid OOD actions with uncertain reward estimates. Our approach, termed as caution, can be seen as the reverse of curiosity: where curiosity rewards prediction error as a signal of novelty, caution penalizes prediction error as a signal of distributional uncertainty. Practically, caution trains an error model on typical responses and uses its prediction error to lower reward estimates for atypical ones. Our extensive empirical evaluation demonstrates that caution is a simple, computationally efficient approach that substantially mitigates reward hacking in BoN sampling. We also provide a theoretical analysis in a simplified linear setting, which shows that caution provably improves over the standard BoN approach. Together, our results not only establish caution as a practical solution to reward hacking, but also provide evidence that curiosity-based approaches can be a general OOD detection technique in LLM settings.
Back to Blackwell: Closing the Loop on Intransitivity in Multi-Objective Preference Fine-Tuning
Feb 22, 2026A recurring challenge in preference fine-tuning (PFT) is handling $\textit{intransitive}$ (i.e., cyclic) preferences. Intransitive preferences often stem from either $\textit{(i)}$ inconsistent rankings along a single objective or $\textit{(ii)}$ scalarizing multiple objectives into a single metric. Regardless of their source, the downstream implication of intransitive preferences is the same: there is no well-defined optimal policy, breaking a core assumption of the standard PFT pipeline. In response, we propose a novel, game-theoretic solution concept -- the $\textit{Maximum Entropy Blackwell Winner}$ ($\textit{MaxEntBW}$) -- that is well-defined under multi-objective intransitive preferences. To enable computing MaxEntBWs at scale, we derive $\texttt{PROSPER}$: a provably efficient PFT algorithm. Unlike prior self-play techniques, $\texttt{PROSPER}$ directly handles multiple objectives without requiring scalarization. We then apply $\texttt{PROSPER}$ to the problem of fine-tuning large language models (LLMs) from multi-objective LLM-as-a-Judge feedback (e.g., rubric-based judges), a setting where both sources of intransitivity arise. We find that $\texttt{PROSPER}$ outperforms all baselines considered across both instruction following and general chat benchmarks, releasing trained model checkpoints at the 7B and 3B parameter scales.
Rubrics as an Attack Surface: Stealthy Preference Drift in LLM Judges
Feb 14, 2026Evaluation and alignment pipelines for large language models increasingly rely on LLM-based judges, whose behavior is guided by natural-language rubrics and validated on benchmarks. We identify a previously under-recognized vulnerability in this workflow, which we term Rubric-Induced Preference Drift (RIPD). Even when rubric edits pass benchmark validation, they can still produce systematic and directional shifts in a judge's preferences on target domains. Because rubrics serve as a high-level decision interface, such drift can emerge from seemingly natural, criterion-preserving edits and remain difficult to detect through aggregate benchmark metrics or limited spot-checking. We further show this vulnerability can be exploited through rubric-based preference attacks, in which benchmark-compliant rubric edits steer judgments away from a fixed human or trusted reference on target domains, systematically inducing RIPD and reducing target-domain accuracy up to 9.5% (helpfulness) and 27.9% (harmlessness). When these judgments are used to generate preference labels for downstream post-training, the induced bias propagates through alignment pipelines and becomes internalized in trained policies. This leads to persistent and systematic drift in model behavior. Overall, our findings highlight evaluation rubrics as a sensitive and manipulable control interface, revealing a system-level alignment risk that extends beyond evaluator reliability alone. The code is available at: https://github.com/ZDCSlab/Rubrics-as-an-Attack-Surface. Warning: Certain sections may contain potentially harmful content that may not be appropriate for all readers.
Gained in Translation: Privileged Pairwise Judges Enhance Multilingual Reasoning
Jan 26, 2026When asked a question in a language less seen in its training data, current reasoning large language models (RLMs) often exhibit dramatically lower performance than when asked the same question in English. In response, we introduce \texttt{SP3F} (Self-Play with Privileged Pairwise Feedback), a two-stage framework for enhancing multilingual reasoning without \textit{any} data in the target language(s). First, we supervise fine-tune (SFT) on translated versions of English question-answer pairs to raise base model correctness. Second, we perform RL with feedback from a pairwise judge in a self-play fashion, with the judge receiving the English reference response as \textit{privileged information}. Thus, even when none of the model's responses are completely correct, the privileged pairwise judge can still tell which response is better. End-to-end, \texttt{SP3F} greatly improves base model performance, even outperforming fully post-trained models on multiple math and non-math tasks with less than of the training data across the single-language, multilingual, and generalization to unseen language settings.
Persona-Augmented Benchmarking: Evaluating LLMs Across Diverse Writing Styles
Jul 29, 2025Current benchmarks for evaluating Large Language Models (LLMs) often do not exhibit enough writing style diversity, with many adhering primarily to standardized conventions. Such benchmarks do not fully capture the rich variety of communication patterns exhibited by humans. Thus, it is possible that LLMs, which are optimized on these benchmarks, may demonstrate brittle performance when faced with "non-standard" input. In this work, we test this hypothesis by rewriting evaluation prompts using persona-based LLM prompting, a low-cost method to emulate diverse writing styles. Our results show that, even with identical semantic content, variations in writing style and prompt formatting significantly impact the estimated performance of the LLM under evaluation. Notably, we identify distinct writing styles that consistently trigger either low or high performance across a range of models and tasks, irrespective of model family, size, and recency. Our work offers a scalable approach to augment existing benchmarks, improving the external validity of the assessments they provide for measuring LLM performance across linguistic variations.
Measurement as Bricolage: Examining How Data Scientists Construct Target Variables for Predictive Modeling Tasks
Jul 03, 2025



Data scientists often formulate predictive modeling tasks involving fuzzy, hard-to-define concepts, such as the "authenticity" of student writing or the "healthcare need" of a patient. Yet the process by which data scientists translate fuzzy concepts into a concrete, proxy target variable remains poorly understood. We interview fifteen data scientists in education (N=8) and healthcare (N=7) to understand how they construct target variables for predictive modeling tasks. Our findings suggest that data scientists construct target variables through a bricolage process, involving iterative negotiation between high-level measurement objectives and low-level practical constraints. Data scientists attempt to satisfy five major criteria for a target variable through bricolage: validity, simplicity, predictability, portability, and resource requirements. To achieve this, data scientists adaptively use problem (re)formulation strategies, such as swapping out one candidate target variable for another when the first fails to meet certain criteria (e.g., predictability), or composing multiple outcomes into a single target variable to capture a more holistic set of modeling objectives. Based on our findings, we present opportunities for future HCI, CSCW, and ML research to better support the art and science of target variable construction.
Enhancing One-run Privacy Auditing with Quantile Regression-Based Membership Inference
Jun 18, 2025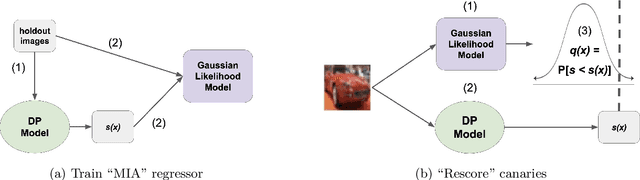
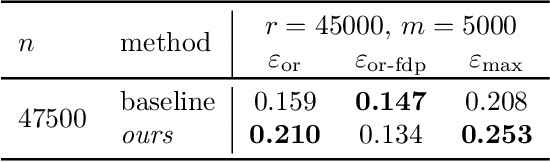
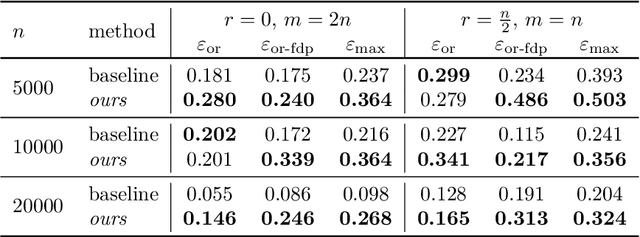
Differential privacy (DP) auditing aims to provide empirical lower bounds on the privacy guarantees of DP mechanisms like DP-SGD. While some existing techniques require many training runs that are prohibitively costly, recent work introduces one-run auditing approaches that effectively audit DP-SGD in white-box settings while still being computationally efficient. However, in the more practical black-box setting where gradients cannot be manipulated during training and only the last model iterate is observed, prior work shows that there is still a large gap between the empirical lower bounds and theoretical upper bounds. Consequently, in this work, we study how incorporating approaches for stronger membership inference attacks (MIA) can improve one-run auditing in the black-box setting. Evaluating on image classification models trained on CIFAR-10 with DP-SGD, we demonstrate that our proposed approach, which utilizes quantile regression for MIA, achieves tighter bounds while crucially maintaining the computational efficiency of one-run methods.
Membership Inference Attacks for Unseen Classes
Jun 06, 2025Shadow model attacks are the state-of-the-art approach for membership inference attacks on machine learning models. However, these attacks typically assume an adversary has access to a background (nonmember) data distribution that matches the distribution the target model was trained on. We initiate a study of membership inference attacks where the adversary or auditor cannot access an entire subclass from the distribution -- a more extreme but realistic version of distribution shift than has been studied previously. In this setting, we first show that the performance of shadow model attacks degrades catastrophically, and then demonstrate the promise of another approach, quantile regression, that does not have the same limitations. We show that quantile regression attacks consistently outperform shadow model attacks in the class dropout setting -- for example, quantile regression attacks achieve up to 11$\times$ the TPR of shadow models on the unseen class on CIFAR-100, and achieve nontrivial TPR on ImageNet even with 90% of training classes removed. We also provide a theoretical model that illustrates the potential and limitations of this approach.