 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen AI Benchmarks Plateau: A Systematic Study of Benchmark Saturation
Feb 18, 2026Artificial Intelligence (AI) benchmarks play a central role in measuring progress in model development and guiding deployment decisions. However, many benchmarks quickly become saturated, meaning that they can no longer differentiate between the best-performing models, diminishing their long-term value. In this study, we analyze benchmark saturation across 60 Large Language Model (LLM) benchmarks selected from technical reports by major model developers. To identify factors driving saturation, we characterize benchmarks along 14 properties spanning task design, data construction, and evaluation format. We test five hypotheses examining how each property contributes to saturation rates. Our analysis reveals that nearly half of the benchmarks exhibit saturation, with rates increasing as benchmarks age. Notably, hiding test data (i.e., public vs. private) shows no protective effect, while expert-curated benchmarks resist saturation better than crowdsourced ones. Our findings highlight which design choices extend benchmark longevity and inform strategies for more durable evaluation.
Pearmut: Human Evaluation of Translation Made Trivial
Jan 06, 2026Human evaluation is the gold standard for multilingual NLP, but is often skipped in practice and substituted with automatic metrics, because it is notoriously complex and slow to set up with existing tools with substantial engineering and operational overhead. We introduce Pearmut, a lightweight yet feature-rich platform that makes end-to-end human evaluation as easy to run as automatic evaluation. Pearmut removes common entry barriers and provides support for evaluating multilingual tasks, with a particular focus on machine translation. The platform implements standard evaluation protocols, including DA, ESA, or MQM, but is also extensible to allow prototyping new protocols. It features document-level context, absolute and contrastive evaluation, attention checks, ESAAI pre-annotations and both static and active learning-based assignment strategies. Pearmut enables reliable human evaluation to become a practical, routine component of model development and diagnosis rather than an occasional effort.
Hearing to Translate: The Effectiveness of Speech Modality Integration into LLMs
Dec 24, 2025
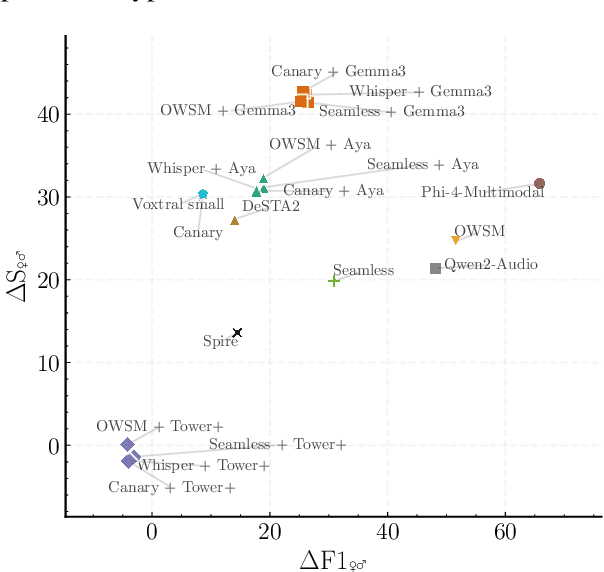
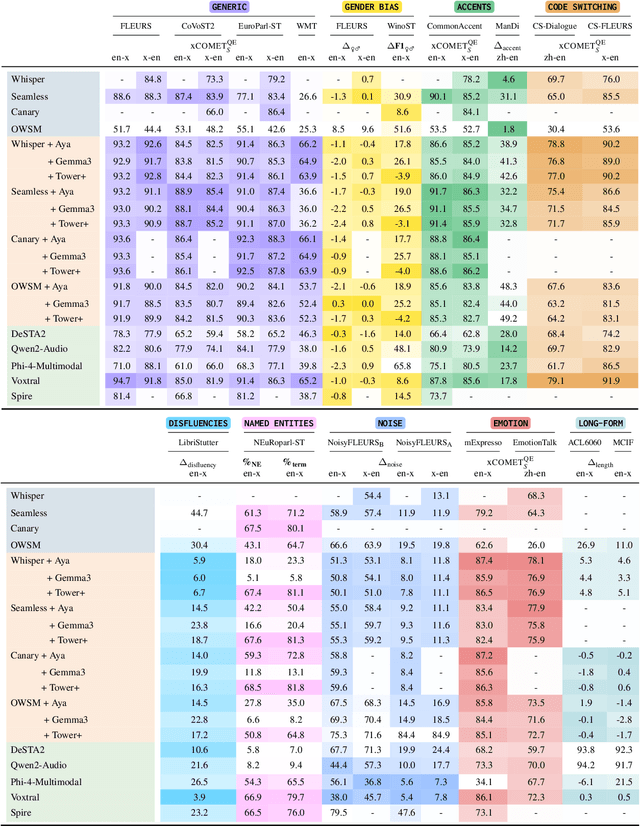
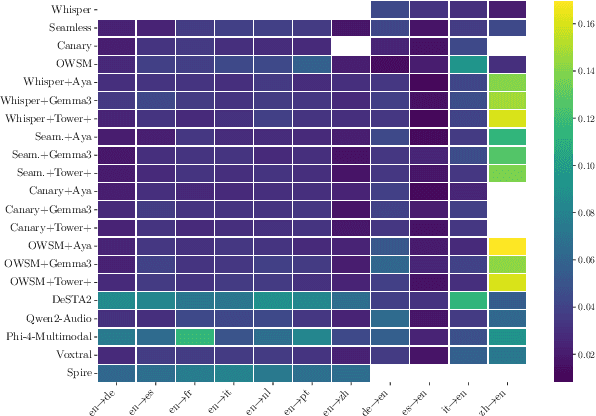
As Large Language Models (LLMs) expand beyond text, integrating speech as a native modality has given rise to SpeechLLMs, which aim to translate spoken language directly, thereby bypassing traditional transcription-based pipelines. Whether this integration improves speech-to-text translation quality over established cascaded architectures, however, remains an open question. We present Hearing to Translate, the first comprehensive test suite rigorously benchmarking 5 state-of-the-art SpeechLLMs against 16 strong direct and cascade systems that couple leading speech foundation models (SFM), with multilingual LLMs. Our analysis spans 16 benchmarks, 13 language pairs, and 9 challenging conditions, including disfluent, noisy, and long-form speech. Across this extensive evaluation, we find that cascaded systems remain the most reliable overall, while current SpeechLLMs only match cascades in selected settings and SFMs lag behind both, highlighting that integrating an LLM, either within the model or in a pipeline, is essential for high-quality speech translation.
Deconstructing Self-Bias in LLM-generated Translation Benchmarks
Sep 30, 2025As large language models (LLMs) begin to saturate existing benchmarks, automated benchmark creation using LLMs (LLM as a benchmark) has emerged as a scalable alternative to slow and costly human curation. While these generated test sets have to potential to cheaply rank models, we demonstrate a critical flaw. LLM generated benchmarks systematically favor the model that created the benchmark, they exhibit self bias on low resource languages to English translation tasks. We show three key findings on automatic benchmarking of LLMs for translation: First, this bias originates from two sources: the generated test data (LLM as a testset) and the evaluation method (LLM as an evaluator), with their combination amplifying the effect. Second, self bias in LLM as a benchmark is heavily influenced by the model's generation capabilities in the source language. For instance, we observe more pronounced bias in into English translation, where the model's generation system is developed, than in out of English translation tasks. Third, we observe that low diversity in source text is one attribution to self bias. Our results suggest that improving the diversity of these generated source texts can mitigate some of the observed self bias.
Generating Difficult-to-Translate Texts
Sep 30, 2025Machine translation benchmarks sourced from the real world are quickly obsoleted, due to most examples being easy for state-of-the-art translation models. This limits the benchmark's ability to distinguish which model is better or to reveal models' weaknesses. Current methods for creating difficult test cases, such as subsampling or from-scratch synthesis, either fall short of identifying difficult examples or suffer from a lack of diversity and naturalness. Inspired by the iterative process of human experts probing for model failures, we propose MT-breaker, a method where a large language model iteratively refines a source text to increase its translation difficulty. The LLM iteratively queries a target machine translation model to guide its generation of difficult examples. Our approach generates examples that are more challenging for the target MT model while preserving the diversity of natural texts. While the examples are tailored to a particular machine translation model during the generation, the difficulty also transfers to other models and languages.
Searching for Difficult-to-Translate Test Examples at Scale
Sep 30, 2025NLP models require test data that are sufficiently challenging. The difficulty of an example is linked to the topic it originates from (''seed topic''). The relationship between the topic and the difficulty of its instances is stochastic in nature: an example about a difficult topic can happen to be easy, and vice versa. At the scale of the Internet, there are tens of thousands of potential topics, and finding the most difficult one by drawing and evaluating a large number of examples across all topics is computationally infeasible. We formalize this task and treat it as a multi-armed bandit problem. In this framework, each topic is an ''arm,'' and pulling an arm (at a cost) involves drawing a single example, evaluating it, and measuring its difficulty. The goal is to efficiently identify the most difficult topics within a fixed computational budget. We illustrate the bandit problem setup of finding difficult examples for the task of machine translation. We find that various bandit strategies vastly outperform baseline methods like brute-force searching the most challenging topics.
Biased Tales: Cultural and Topic Bias in Generating Children's Stories
Sep 09, 2025



Stories play a pivotal role in human communication, shaping beliefs and morals, particularly in children. As parents increasingly rely on large language models (LLMs) to craft bedtime stories, the presence of cultural and gender stereotypes in these narratives raises significant concerns. To address this issue, we present Biased Tales, a comprehensive dataset designed to analyze how biases influence protagonists' attributes and story elements in LLM-generated stories. Our analysis uncovers striking disparities. When the protagonist is described as a girl (as compared to a boy), appearance-related attributes increase by 55.26%. Stories featuring non-Western children disproportionately emphasize cultural heritage, tradition, and family themes far more than those for Western children. Our findings highlight the role of sociocultural bias in making creative AI use more equitable and diverse.
Estimating Machine Translation Difficulty
Aug 13, 2025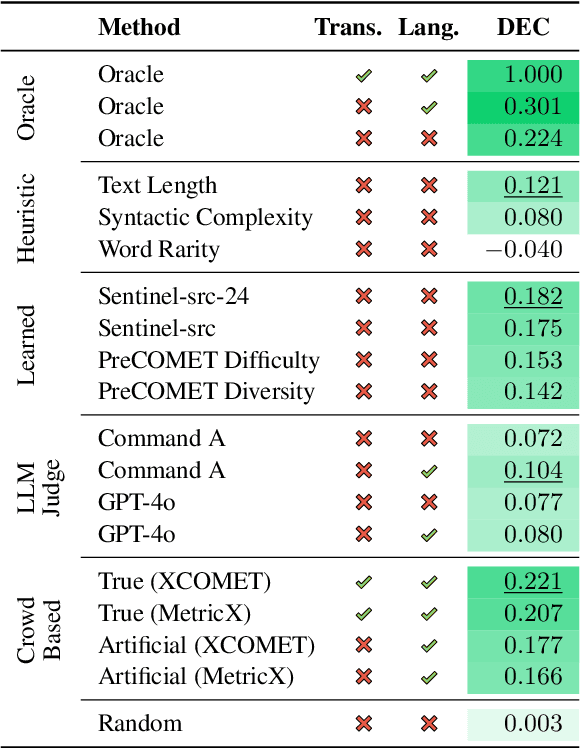
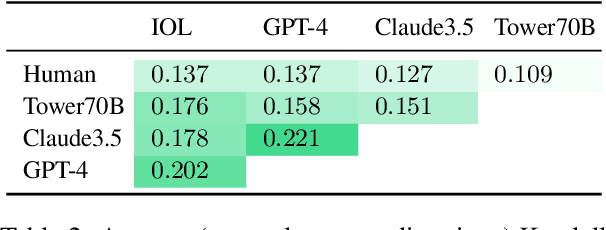
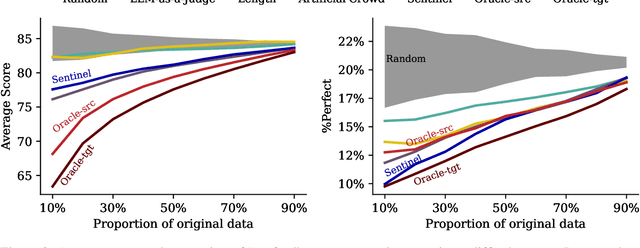
Machine translation quality has began achieving near-perfect translations in some setups. These high-quality outputs make it difficult to distinguish between state-of-the-art models and to identify areas for future improvement. Automatically identifying texts where machine translation systems struggle holds promise for developing more discriminative evaluations and guiding future research. We formalize the task of translation difficulty estimation, defining a text's difficulty based on the expected quality of its translations. We introduce a new metric to evaluate difficulty estimators and use it to assess both baselines and novel approaches. Finally, we demonstrate the practical utility of difficulty estimators by using them to construct more challenging machine translation benchmarks. Our results show that dedicated models (dubbed Sentinel-src) outperform both heuristic-based methods (e.g. word rarity or syntactic complexity) and LLM-as-a-judge approaches. We release two improved models for difficulty estimation, Sentinel-src-24 and Sentinel-src-25, which can be used to scan large collections of texts and select those most likely to challenge contemporary machine translation systems.
Can Large Language Models Capture Human Annotator Disagreements?
Jun 24, 2025Human annotation variation (i.e., annotation disagreements) is common in NLP and often reflects important information such as task subjectivity and sample ambiguity. While Large Language Models (LLMs) are increasingly used for automatic annotation to reduce human effort, their evaluation often focuses on predicting the majority-voted "ground truth" labels. It is still unclear, however, whether these models also capture informative human annotation variation. Our work addresses this gap by extensively evaluating LLMs' ability to predict annotation disagreements without access to repeated human labels. Our results show that LLMs struggle with modeling disagreements, which can be overlooked by majority label-based evaluations. Notably, while RLVR-style (Reinforcement learning with verifiable rewards) reasoning generally boosts LLM performance, it degrades performance in disagreement prediction. Our findings highlight the critical need for evaluating and improving LLM annotators in disagreement modeling. Code and data at https://github.com/EdisonNi-hku/Disagreement_Prediction.
Unsupervised Word-level Quality Estimation for Machine Translation Through the Lens of Annotators (Dis)agreement
May 29, 2025Word-level quality estimation (WQE) aims to automatically identify fine-grained error spans in machine-translated outputs and has found many uses, including assisting translators during post-editing. Modern WQE techniques are often expensive, involving prompting of large language models or ad-hoc training on large amounts of human-labeled data. In this work, we investigate efficient alternatives exploiting recent advances in language model interpretability and uncertainty quantification to identify translation errors from the inner workings of translation models. In our evaluation spanning 14 metrics across 12 translation directions, we quantify the impact of human label variation on metric performance by using multiple sets of human labels. Our results highlight the untapped potential of unsupervised metrics, the shortcomings of supervised methods when faced with label uncertainty, and the brittleness of single-annotator evaluation practices.