 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRSFNet: A White-Box Image Retouching Approach using Region-Specific Color Filters
Mar 15, 2023



Retouching images is an essential aspect of enhancing the visual appeal of photos. Although users often share common aesthetic preferences, their retouching methods may vary based on their individual preferences. Therefore, there is a need for white-box approaches that produce satisfying results and enable users to conveniently edit their images simultaneously. Recent white-box retouching methods rely on cascaded global filters that provide image-level filter arguments but cannot perform fine-grained retouching. In contrast, colorists typically use a divide-and-conquer approach, performing a series of region-specific fine-grained enhancements when using traditional tools like Davinci Resolve. We draw on this insight to develop a white-box framework for photo retouching using parallel region-specific filters, called RSFNet. Our model generates filter arguments (e.g., saturation, contrast, hue) and attention maps of regions for each filter simultaneously. Instead of cascading filters, RSFNet employs linear summations of filters, allowing for a more diverse range of filter classes that can be trained more easily. Our experiments demonstrate that RSFNet achieves state-of-the-art results, offering satisfying aesthetic appeal and greater user convenience for editable white-box retouching.
Synthesizing Realistic Image Restoration Training Pairs: A Diffusion Approach
Mar 13, 2023In supervised image restoration tasks, one key issue is how to obtain the aligned high-quality (HQ) and low-quality (LQ) training image pairs. Unfortunately, such HQ-LQ training pairs are hard to capture in practice, and hard to synthesize due to the complex unknown degradation in the wild. While several sophisticated degradation models have been manually designed to synthesize LQ images from their HQ counterparts, the distribution gap between the synthesized and real-world LQ images remains large. We propose a new approach to synthesizing realistic image restoration training pairs using the emerging denoising diffusion probabilistic model (DDPM). First, we train a DDPM, which could convert a noisy input into the desired LQ image, with a large amount of collected LQ images, which define the target data distribution. Then, for a given HQ image, we synthesize an initial LQ image by using an off-the-shelf degradation model, and iteratively add proper Gaussian noises to it. Finally, we denoise the noisy LQ image using the pre-trained DDPM to obtain the final LQ image, which falls into the target distribution of real-world LQ images. Thanks to the strong capability of DDPM in distribution approximation, the synthesized HQ-LQ image pairs can be used to train robust models for real-world image restoration tasks, such as blind face image restoration and blind image super-resolution. Experiments demonstrated the superiority of our proposed approach to existing degradation models. Code and data will be released.
DDColor: Towards Photo-Realistic and Semantic-Aware Image Colorization via Dual Decoders
Dec 23, 2022



Automatic image colorization is a particularly challenging problem. Due to the high illness of the problem and multi-modal uncertainty, directly training a deep neural network usually leads to incorrect semantic colors and low color richness. Existing transformer-based methods can deliver better results but highly depend on hand-crafted dataset-level empirical distribution priors. In this work, we propose DDColor, a new end-to-end method with dual decoders, for image colorization. More specifically, we design a multi-scale image decoder and a transformer-based color decoder. The former manages to restore the spatial resolution of the image, while the latter establishes the correlation between semantic representations and color queries via cross-attention. The two decoders incorporate to learn semantic-aware color embedding by leveraging the multi-scale visual features. With the help of these two decoders, our method succeeds in producing semantically consistent and visually plausible colorization results without any additional priors. In addition, a simple but effective colorfulness loss is introduced to further improve the color richness of generated results. Our extensive experiments demonstrate that the proposed DDColor achieves significantly superior performance to existing state-of-the-art works both quantitatively and qualitatively. Codes will be made publicly available at https://github.com/piddnad/DDColor.
NTIRE 2022 Challenge on Efficient Super-Resolution: Methods and Results
May 11, 2022



This paper reviews the NTIRE 2022 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The task of the challenge was to super-resolve an input image with a magnification factor of $\times$4 based on pairs of low and corresponding high resolution images. The aim was to design a network for single image super-resolution that achieved improvement of efficiency measured according to several metrics including runtime, parameters, FLOPs, activations, and memory consumption while at least maintaining the PSNR of 29.00dB on DIV2K validation set. IMDN is set as the baseline for efficiency measurement. The challenge had 3 tracks including the main track (runtime), sub-track one (model complexity), and sub-track two (overall performance). In the main track, the practical runtime performance of the submissions was evaluated. The rank of the teams were determined directly by the absolute value of the average runtime on the validation set and test set. In sub-track one, the number of parameters and FLOPs were considered. And the individual rankings of the two metrics were summed up to determine a final ranking in this track. In sub-track two, all of the five metrics mentioned in the description of the challenge including runtime, parameter count, FLOPs, activations, and memory consumption were considered. Similar to sub-track one, the rankings of five metrics were summed up to determine a final ranking. The challenge had 303 registered participants, and 43 teams made valid submissions. They gauge the state-of-the-art in efficient single image super-resolution.
Beyond a Video Frame Interpolator: A Space Decoupled Learning Approach to Continuous Image Transition
Mar 18, 2022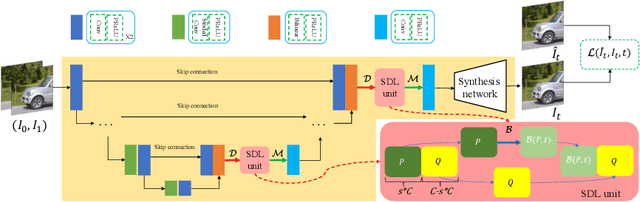
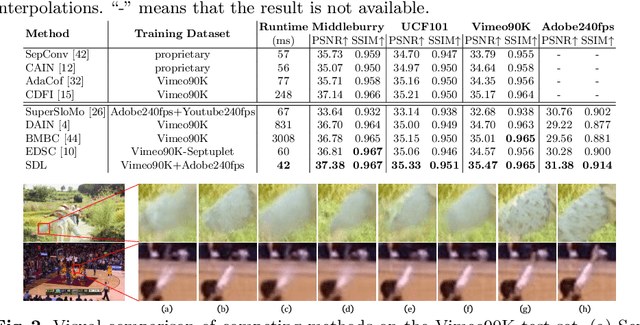


Video frame interpolation (VFI) aims to improve the temporal resolution of a video sequence. Most of the existing deep learning based VFI methods adopt off-the-shelf optical flow algorithms to estimate the bidirectional flows and interpolate the missing frames accordingly. Though having achieved a great success, these methods require much human experience to tune the bidirectional flows and often generate unpleasant results when the estimated flows are not accurate. In this work, we rethink the VFI problem and formulate it as a continuous image transition (CIT) task, whose key issue is to transition an image from one space to another space continuously. More specifically, we learn to implicitly decouple the images into a translatable flow space and a non-translatable feature space. The former depicts the translatable states between the given images, while the later aims to reconstruct the intermediate features that cannot be directly translated. In this way, we can easily perform image interpolation in the flow space and intermediate image synthesis in the feature space, obtaining a CIT model. The proposed space decoupled learning (SDL) approach is simple to implement, while it provides an effective framework to a variety of CIT problems beyond VFI, such as style transfer and image morphing. Our extensive experiments on a variety of CIT tasks demonstrate the superiority of SDL to existing methods. The source code and models can be found at \url{https://github.com/yangxy/SDL}.
Noise-Resistant Deep Metric Learning with Probabilistic Instance Filtering
Aug 03, 2021
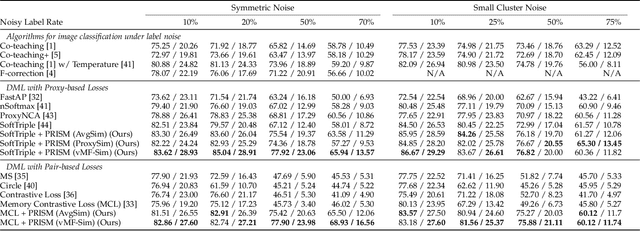
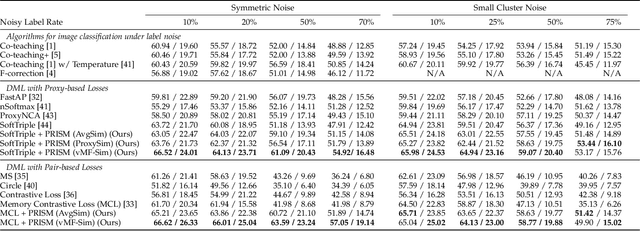
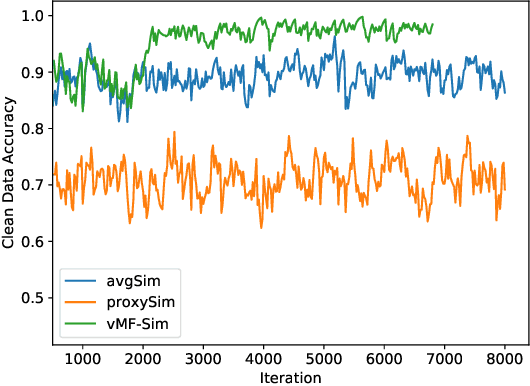
Noisy labels are commonly found in real-world data, which cause performance degradation of deep neural networks. Cleaning data manually is labour-intensive and time-consuming. Previous research mostly focuses on enhancing classification models against noisy labels, while the robustness of deep metric learning (DML) against noisy labels remains less well-explored. In this paper, we bridge this important gap by proposing Probabilistic Ranking-based Instance Selection with Memory (PRISM) approach for DML. PRISM calculates the probability of a label being clean, and filters out potentially noisy samples. Specifically, we propose three methods to calculate this probability: 1) Average Similarity Method (AvgSim), which calculates the average similarity between potentially noisy data and clean data; 2) Proxy Similarity Method (ProxySim), which replaces the centers maintained by AvgSim with the proxies trained by proxy-based method; and 3) von Mises-Fisher Distribution Similarity (vMF-Sim), which estimates a von Mises-Fisher distribution for each data class. With such a design, the proposed approach can deal with challenging DML situations in which the majority of the samples are noisy. Extensive experiments on both synthetic and real-world noisy dataset show that the proposed approach achieves up to 8.37% higher Precision@1 compared with the best performing state-of-the-art baseline approaches, within reasonable training time.
Attention-guided Temporal Coherent Video Object Matting
May 24, 2021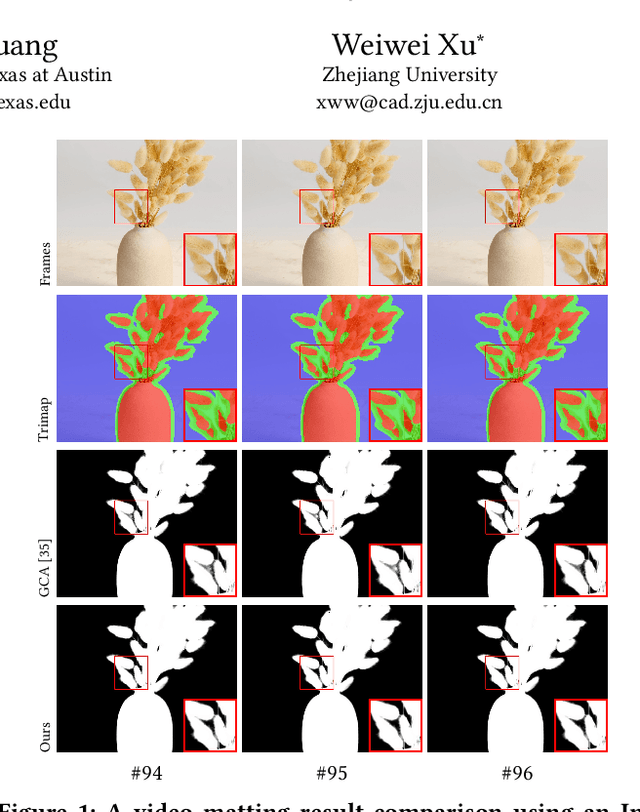
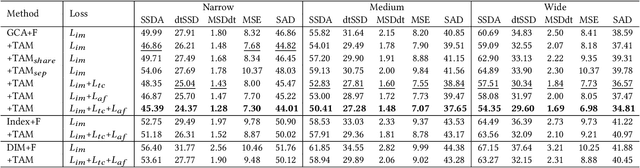
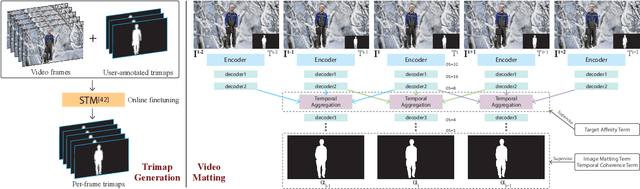
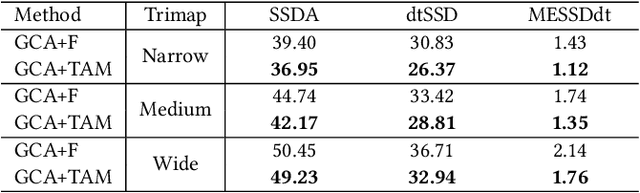
This paper proposes a novel deep learning-based video object matting method that can achieve temporally coherent matting results. Its key component is an attention-based temporal aggregation module that maximizes image matting networks' strength for video matting networks. This module computes temporal correlations for pixels adjacent to each other along the time axis in feature space to be robust against motion noises. We also design a novel loss term to train the attention weights, which drastically boosts the video matting performance. Besides, we show how to effectively solve the trimap generation problem by fine-tuning a state-of-the-art video object segmentation network with a sparse set of user-annotated keyframes. To facilitate video matting and trimap generation networks' training, we construct a large-scale video matting dataset with 80 training and 28 validation foreground video clips with ground-truth alpha mattes. Experimental results show that our method can generate high-quality alpha mattes for various videos featuring appearance change, occlusion, and fast motion. Our code and dataset can be found at https://github.com/yunkezhang/TCVOM
GAN Prior Embedded Network for Blind Face Restoration in the Wild
May 13, 2021
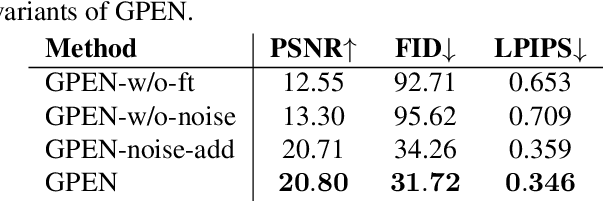
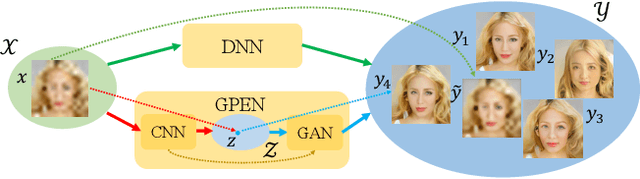
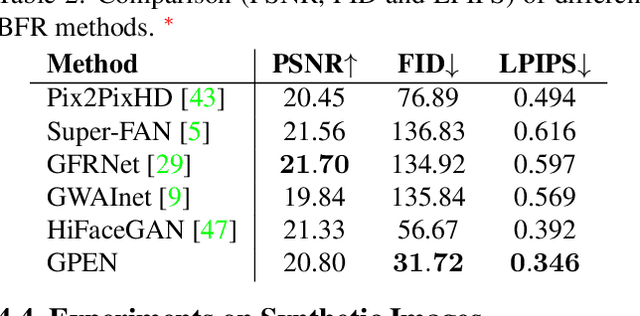
Blind face restoration (BFR) from severely degraded face images in the wild is a very challenging problem. Due to the high illness of the problem and the complex unknown degradation, directly training a deep neural network (DNN) usually cannot lead to acceptable results. Existing generative adversarial network (GAN) based methods can produce better results but tend to generate over-smoothed restorations. In this work, we propose a new method by first learning a GAN for high-quality face image generation and embedding it into a U-shaped DNN as a prior decoder, then fine-tuning the GAN prior embedded DNN with a set of synthesized low-quality face images. The GAN blocks are designed to ensure that the latent code and noise input to the GAN can be respectively generated from the deep and shallow features of the DNN, controlling the global face structure, local face details and background of the reconstructed image. The proposed GAN prior embedded network (GPEN) is easy-to-implement, and it can generate visually photo-realistic results. Our experiments demonstrated that the proposed GPEN achieves significantly superior results to state-of-the-art BFR methods both quantitatively and qualitatively, especially for the restoration of severely degraded face images in the wild. The source code and models can be found at https://github.com/yangxy/GPEN.
Noise-resistant Deep Metric Learning with Ranking-based Instance Selection
Apr 12, 2021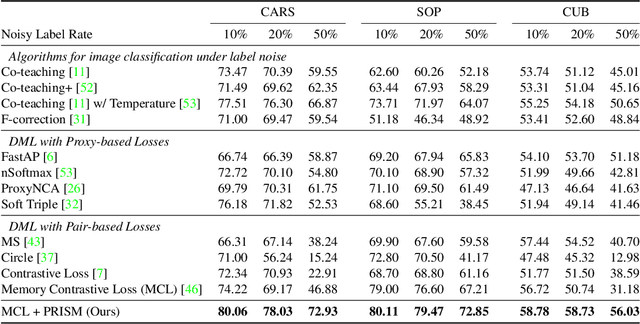

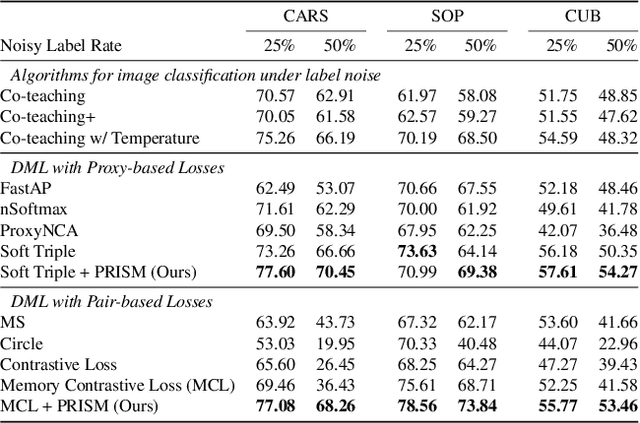
The existence of noisy labels in real-world data negatively impacts the performance of deep learning models. Although much research effort has been devoted to improving robustness to noisy labels in classification tasks, the problem of noisy labels in deep metric learning (DML) remains open. In this paper, we propose a noise-resistant training technique for DML, which we name Probabilistic Ranking-based Instance Selection with Memory (PRISM). PRISM identifies noisy data in a minibatch using average similarity against image features extracted by several previous versions of the neural network. These features are stored in and retrieved from a memory bank. To alleviate the high computational cost brought by the memory bank, we introduce an acceleration method that replaces individual data points with the class centers. In extensive comparisons with 12 existing approaches under both synthetic and real-world label noise, PRISM demonstrates superior performance of up to 6.06% in Precision@1.
Active Boundary Loss for Semantic Segmentation
Feb 04, 2021
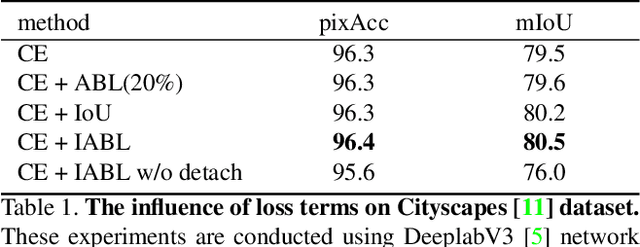

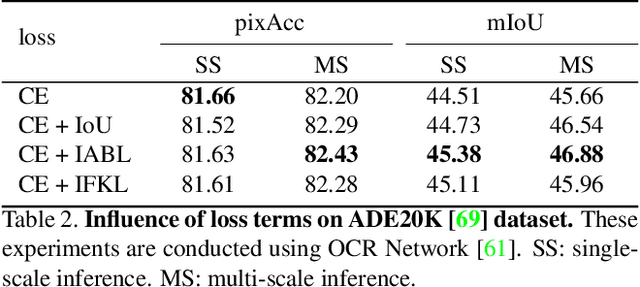
This paper proposes a novel active boundary loss for semantic segmentation. It can progressively encourage the alignment between predicted boundaries and ground-truth boundaries during end-to-end training, which is not explicitly enforced in commonly used cross-entropy loss. Based on the predicted boundaries detected from the segmentation results using current network parameters, we formulate the boundary alignment problem as a differentiable direction vector prediction problem to guide the movement of predicted boundaries in each iteration. Our loss is model-agnostic and can be plugged into the training of segmentation networks to improve the boundary details. Experimental results show that training with the active boundary loss can effectively improve the boundary F-score and mean Intersection-over-Union on challenging image and video object segmentation datasets.