 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Discover: Large Language Models Self-Compose Reasoning Structures
Feb 06, 2024



We introduce SELF-DISCOVER, a general framework for LLMs to self-discover the task-intrinsic reasoning structures to tackle complex reasoning problems that are challenging for typical prompting methods. Core to the framework is a self-discovery process where LLMs select multiple atomic reasoning modules such as critical thinking and step-by-step thinking, and compose them into an explicit reasoning structure for LLMs to follow during decoding. SELF-DISCOVER substantially improves GPT-4 and PaLM 2's performance on challenging reasoning benchmarks such as BigBench-Hard, grounded agent reasoning, and MATH, by as much as 32% compared to Chain of Thought (CoT). Furthermore, SELF-DISCOVER outperforms inference-intensive methods such as CoT-Self-Consistency by more than 20%, while requiring 10-40x fewer inference compute. Finally, we show that the self-discovered reasoning structures are universally applicable across model families: from PaLM 2-L to GPT-4, and from GPT-4 to Llama2, and share commonalities with human reasoning patterns.
AutoMix: Automatically Mixing Language Models
Oct 19, 2023



Large language models (LLMs) are now available in various sizes and configurations from cloud API providers. While this diversity offers a broad spectrum of choices, effectively leveraging the options to optimize computational cost and performance remains challenging. In this work, we present AutoMix, an approach that strategically routes queries to larger LMs, based on the approximate correctness of outputs from a smaller LM. Central to AutoMix is a few-shot self-verification mechanism, which estimates the reliability of its own outputs without requiring training. Given that verifications can be noisy, we employ a meta verifier in AutoMix to refine the accuracy of these assessments. Our experiments using LLAMA2-13/70B, on five context-grounded reasoning datasets demonstrate that AutoMix surpasses established baselines, improving the incremental benefit per cost by up to 89%. Our code and data are available at https://github.com/automix-llm/automix.
How FaR Are Large Language Models From Agents with Theory-of-Mind?
Oct 04, 2023



"Thinking is for Doing." Humans can infer other people's mental states from observations--an ability called Theory-of-Mind (ToM)--and subsequently act pragmatically on those inferences. Existing question answering benchmarks such as ToMi ask models questions to make inferences about beliefs of characters in a story, but do not test whether models can then use these inferences to guide their actions. We propose a new evaluation paradigm for large language models (LLMs): Thinking for Doing (T4D), which requires models to connect inferences about others' mental states to actions in social scenarios. Experiments on T4D demonstrate that LLMs such as GPT-4 and PaLM 2 seemingly excel at tracking characters' beliefs in stories, but they struggle to translate this capability into strategic action. Our analysis reveals the core challenge for LLMs lies in identifying the implicit inferences about mental states without being explicitly asked about as in ToMi, that lead to choosing the correct action in T4D. To bridge this gap, we introduce a zero-shot prompting framework, Foresee and Reflect (FaR), which provides a reasoning structure that encourages LLMs to anticipate future challenges and reason about potential actions. FaR boosts GPT-4's performance from 50% to 71% on T4D, outperforming other prompting methods such as Chain-of-Thought and Self-Ask. Moreover, FaR generalizes to diverse out-of-distribution story structures and scenarios that also require ToM inferences to choose an action, consistently outperforming other methods including few-shot in-context learning.
An AI Dungeon Master's Guide: Learning to Converse and Guide with Intents and Theory-of-Mind in Dungeons and Dragons
Dec 20, 2022We propose a novel task, G4C (Goal-driven Guidance Generation in Grounded Communication), for studying goal-driven and grounded natural language interactions. Specifically, we choose Dungeons and Dragons (D&D) -- a role-playing game consisting of multiple player characters and a Dungeon Master (DM) who collaborate to achieve a set of goals that are beneficial to the players -- as a testbed for this task. Here, each of the player characters is a student, with their own personas and abilities, and the DM is the teacher, an arbitrator of the rules of the world and responsible for assisting and guiding the students towards a global goal. We propose a theory-of-mind-inspired methodology for training such a DM with reinforcement learning (RL), where a DM: (1) learns to predict how the players will react to its utterances using a dataset of D&D dialogue transcripts; and (2) uses this prediction as a reward function providing feedback on how effective these utterances are at guiding the players towards a goal. Human and automated evaluations show that a DM trained with RL to generate guidance by incorporating a theory-of-mind of the players significantly improves the players' ability to achieve goals grounded in their shared world.
SODA: Million-scale Dialogue Distillation with Social Commonsense Contextualization
Dec 20, 2022



We present SODA: the first publicly available, million-scale high-quality social dialogue dataset. Using SODA, we train COSMO: a generalizable conversation agent outperforming previous best-performing agents on both in- and out-of-domain datasets. In contrast to most existing crowdsourced, small-scale dialogue corpora, we distill 1.5M socially-grounded dialogues from a pre-trained language model (InstructGPT; Ouyang et al., 2022). Dialogues are distilled by contextualizing social commonsense knowledge from a knowledge graph (Atomic10x; West et al., 2022). Human evaluation shows that dialogues in SODA are more consistent, specific, and (surprisingly) natural than prior human-authored datasets - e.g., DailyDialog (Li et al., 2017), BlendedSkillTalk (Smith et al., 2020). In addition, extensive evaluations show that COSMO is significantly more natural and consistent on unseen datasets than best-performing dialogue models - e.g., GODEL (Peng et al., 2022), BlenderBot (Roller et al., 2021), DialoGPT (Zhang et al., 2020). Furthermore, it is sometimes even preferred to the original human-written gold responses. We make our data, models, and code public.
Reflect, Not Reflex: Inference-Based Common Ground Improves Dialogue Response Quality
Nov 16, 2022Human communication relies on common ground (CG), the mutual knowledge and beliefs shared by participants, to produce coherent and interesting conversations. In this paper, we demonstrate that current response generation (RG) models produce generic and dull responses in dialogues because they act reflexively, failing to explicitly model CG, both due to the lack of CG in training data and the standard RG training procedure. We introduce Reflect, a dataset that annotates dialogues with explicit CG (materialized as inferences approximating shared knowledge and beliefs) and solicits 9k diverse human-generated responses each following one common ground. Using Reflect, we showcase the limitations of current dialogue data and RG models: less than half of the responses in current data are rated as high quality (sensible, specific, and interesting) and models trained using this data have even lower quality, while most Reflect responses are judged high quality. Next, we analyze whether CG can help models produce better-quality responses by using Reflect CG to guide RG models. Surprisingly, we find that simply prompting GPT3 to "think" about CG generates 30% more quality responses, showing promising benefits to integrating CG into the RG process.
Detecting Political Biases of Named Entities and Hashtags on Twitter
Sep 16, 2022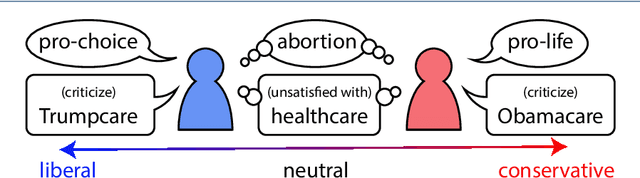

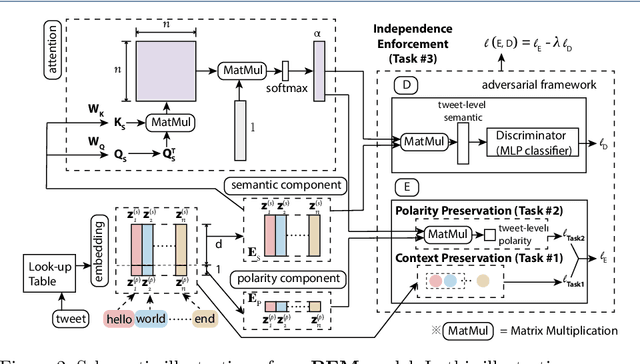
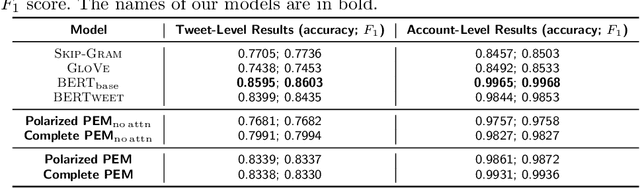
Ideological divisions in the United States have become increasingly prominent in daily communication. Accordingly, there has been much research on political polarization, including many recent efforts that take a computational perspective. By detecting political biases in a corpus of text, one can attempt to describe and discern the polarity of that text. Intuitively, the named entities (i.e., the nouns and phrases that act as nouns) and hashtags in text often carry information about political views. For example, people who use the term "pro-choice" are likely to be liberal, whereas people who use the term "pro-life" are likely to be conservative. In this paper, we seek to reveal political polarities in social-media text data and to quantify these polarities by explicitly assigning a polarity score to entities and hashtags. Although this idea is straightforward, it is difficult to perform such inference in a trustworthy quantitative way. Key challenges include the small number of known labels, the continuous spectrum of political views, and the preservation of both a polarity score and a polarity-neutral semantic meaning in an embedding vector of words. To attempt to overcome these challenges, we propose the Polarity-aware Embedding Multi-task learning (PEM) model. This model consists of (1) a self-supervised context-preservation task, (2) an attention-based tweet-level polarity-inference task, and (3) an adversarial learning task that promotes independence between an embedding's polarity dimension and its semantic dimensions. Our experimental results demonstrate that our PEM model can successfully learn polarity-aware embeddings. We examine a variety of applications and we thereby demonstrate the effectiveness of our PEM model. We also discuss important limitations of our work and stress caution when applying the PEM model to real-world scenarios.
The Role of Facial Expressions and Emotion in ASL
Jan 19, 2022There is little prior work on quantifying the relationships between facial expressions and emotionality in American Sign Language. In this final report, we provide two methods for studying these relationships through probability and prediction. Using a large corpus of natural signing manually annotated with facial features paired with lexical emotion datasets, we find that there exist many relationships between emotionality and the face, and that a simple classifier can predict what someone is saying in terms of broad emotional categories only by looking at the face.
An Intelligent Self-driving Truck System For Highway Transportation
Dec 31, 2021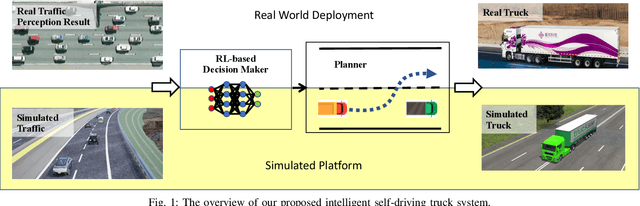
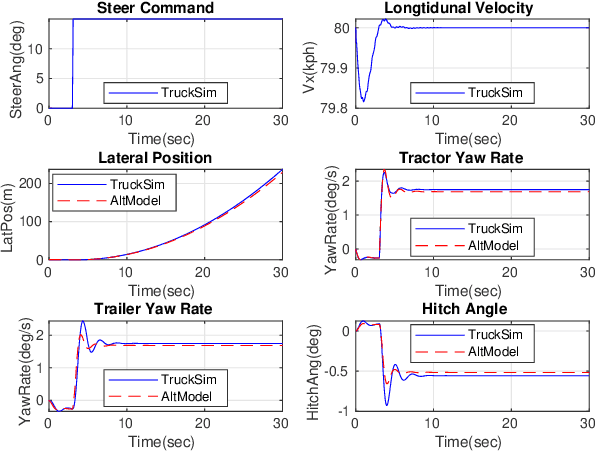
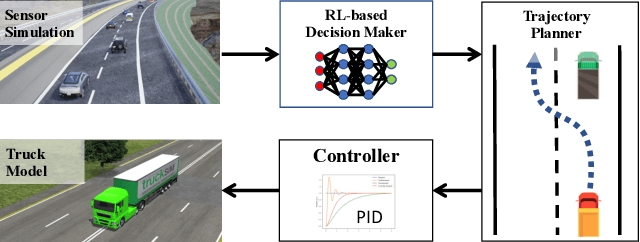
Recently, there have been many advances in autonomous driving society, attracting a lot of attention from academia and industry. However, existing works mainly focus on cars, extra development is still required for self-driving truck algorithms and models. In this paper, we introduce an intelligent self-driving truck system. Our presented system consists of three main components, 1) a realistic traffic simulation module for generating realistic traffic flow in testing scenarios, 2) a high-fidelity truck model which is designed and evaluated for mimicking real truck response in real-world deployment, 3) an intelligent planning module with learning-based decision making algorithm and multi-mode trajectory planner, taking into account the truck's constraints, road slope changes, and the surrounding traffic flow. We provide quantitative evaluations for each component individually to demonstrate the fidelity and performance of each part. We also deploy our proposed system on a real truck and conduct real world experiments which shows our system's capacity of mitigating sim-to-real gap. Our code is available at https://github.com/InceptioResearch/IITS
Think Before You Speak: Using Self-talk to Generate Implicit Commonsense Knowledge for Response Generation
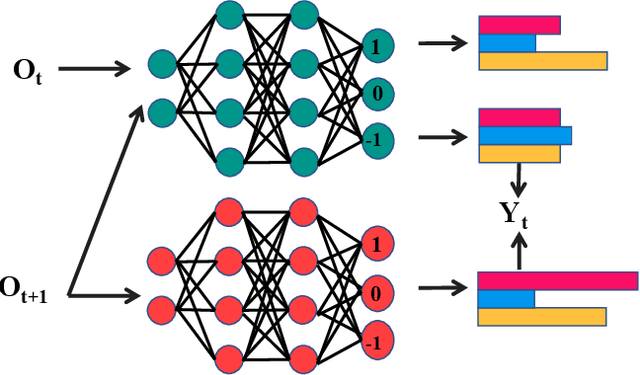
Oct 16, 2021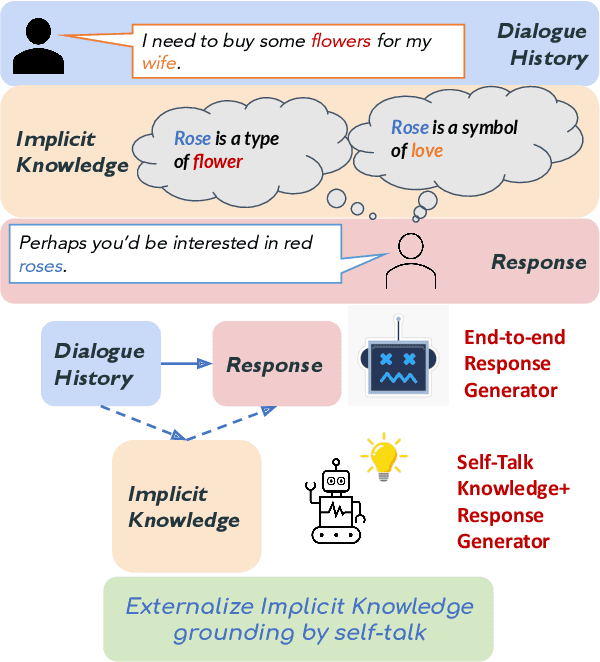
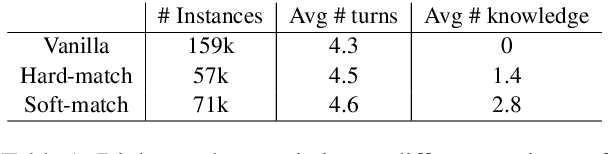
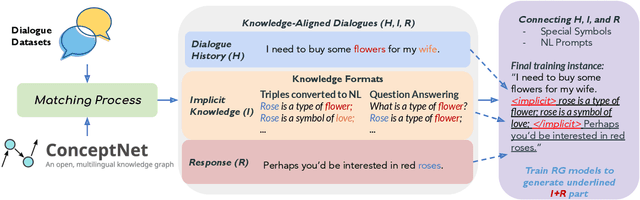

Implicit knowledge, such as common sense, is key to fluid human conversations. Current neural response generation (RG) models are trained end-to-end, omitting unstated implicit knowledge. In this paper, we present a self-talk approach that first generates the implicit commonsense knowledge and then generates response by referencing the externalized knowledge, all using one generative model. We analyze different choices to collect knowledge-aligned dialogues, represent implicit knowledge, and elicit knowledge and responses. We introduce three evaluation aspects: knowledge quality, knowledge-response connection, and response quality and perform extensive human evaluations. Our experimental results show that compared with end-to-end RG models, self-talk models that externalize the knowledge grounding process by explicitly generating implicit knowledge also produce responses that are more informative, specific, and follow common sense. We also find via human evaluation that self-talk models generate high-quality knowledge around 75% of the time. We hope that our findings encourage further work on different approaches to modeling implicit commonsense knowledge and training knowledgeable RG models.