 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRich Insights from Cheap Signals: Efficient Evaluations via Tensor Factorization
Mar 04, 2026Moving beyond evaluations that collapse performance across heterogeneous prompts toward fine-grained evaluation at the prompt level, or within relatively homogeneous subsets, is necessary to diagnose generative models' strengths and weaknesses. Such fine-grained evaluations, however, suffer from a data bottleneck: human gold-standard labels are too costly at this scale, while automated ratings are often misaligned with human judgment. To resolve this challenge, we propose a novel statistical model based on tensor factorization that merges cheap autorater data with a limited set of human gold-standard labels. Specifically, our approach uses autorater scores to pretrain latent representations of prompts and generative models, and then aligns those pretrained representations to human preferences using a small calibration set. This sample-efficient methodology is robust to autorater quality, more accurately predicts human preferences on a per-prompt basis than standard baselines, and provides tight confidence intervals for key statistical parameters of interest. We also showcase the practical utility of our method by constructing granular leaderboards based on prompt qualities and by estimating model performance solely from autorater scores, eliminating the need for additional human annotations.
Benchmarking Diversity in Image Generation via Attribute-Conditional Human Evaluation
Nov 13, 2025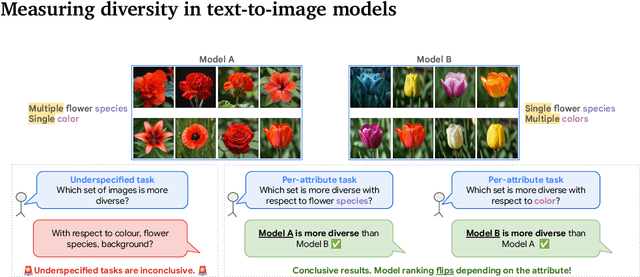
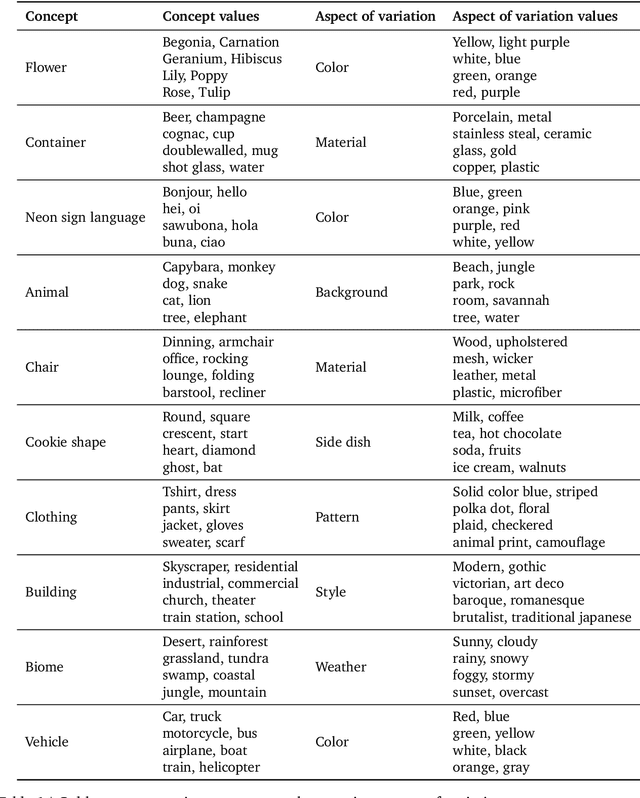
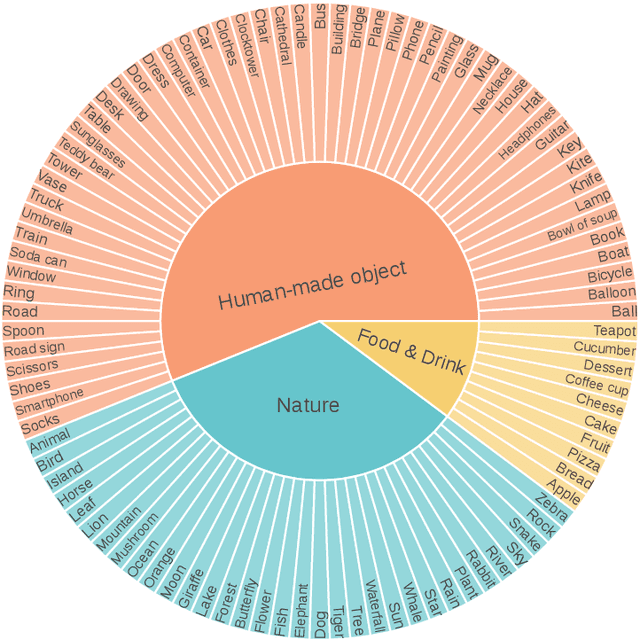
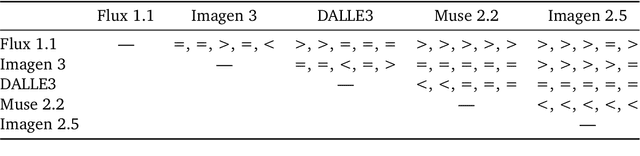
Despite advances in generation quality, current text-to-image (T2I) models often lack diversity, generating homogeneous outputs. This work introduces a framework to address the need for robust diversity evaluation in T2I models. Our framework systematically assesses diversity by evaluating individual concepts and their relevant factors of variation. Key contributions include: (1) a novel human evaluation template for nuanced diversity assessment; (2) a curated prompt set covering diverse concepts with their identified factors of variation (e.g. prompt: An image of an apple, factor of variation: color); and (3) a methodology for comparing models in terms of human annotations via binomial tests. Furthermore, we rigorously compare various image embeddings for diversity measurement. Notably, our principled approach enables ranking of T2I models by diversity, identifying categories where they particularly struggle. This research offers a robust methodology and insights, paving the way for improvements in T2I model diversity and metric development.
Dynamic Classifier-Free Diffusion Guidance via Online Feedback
Sep 19, 2025



Classifier-free guidance (CFG) is a cornerstone of text-to-image diffusion models, yet its effectiveness is limited by the use of static guidance scales. This "one-size-fits-all" approach fails to adapt to the diverse requirements of different prompts; moreover, prior solutions like gradient-based correction or fixed heuristic schedules introduce additional complexities and fail to generalize. In this work, we challeng this static paradigm by introducing a framework for dynamic CFG scheduling. Our method leverages online feedback from a suite of general-purpose and specialized small-scale latent-space evaluations, such as CLIP for alignment, a discriminator for fidelity and a human preference reward model, to assess generation quality at each step of the reverse diffusion process. Based on this feedback, we perform a greedy search to select the optimal CFG scale for each timestep, creating a unique guidance schedule tailored to every prompt and sample. We demonstrate the effectiveness of our approach on both small-scale models and the state-of-the-art Imagen 3, showing significant improvements in text alignment, visual quality, text rendering and numerical reasoning. Notably, when compared against the default Imagen 3 baseline, our method achieves up to 53.8% human preference win-rate for overall preference, a figure that increases up to to 55.5% on prompts targeting specific capabilities like text rendering. Our work establishes that the optimal guidance schedule is inherently dynamic and prompt-dependent, and provides an efficient and generalizable framework to achieve it.
Imagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Evaluating Numerical Reasoning in Text-to-Image Models
Jun 20, 2024



Text-to-image generative models are capable of producing high-quality images that often faithfully depict concepts described using natural language. In this work, we comprehensively evaluate a range of text-to-image models on numerical reasoning tasks of varying difficulty, and show that even the most advanced models have only rudimentary numerical skills. Specifically, their ability to correctly generate an exact number of objects in an image is limited to small numbers, it is highly dependent on the context the number term appears in, and it deteriorates quickly with each successive number. We also demonstrate that models have poor understanding of linguistic quantifiers (such as "a few" or "as many as"), the concept of zero, and struggle with more advanced concepts such as partial quantities and fractional representations. We bundle prompts, generated images and human annotations into GeckoNum, a novel benchmark for evaluation of numerical reasoning.
Revisiting Text-to-Image Evaluation with Gecko: On Metrics, Prompts, and Human Ratings
Apr 25, 2024While text-to-image (T2I) generative models have become ubiquitous, they do not necessarily generate images that align with a given prompt. While previous work has evaluated T2I alignment by proposing metrics, benchmarks, and templates for collecting human judgements, the quality of these components is not systematically measured. Human-rated prompt sets are generally small and the reliability of the ratings -- and thereby the prompt set used to compare models -- is not evaluated. We address this gap by performing an extensive study evaluating auto-eval metrics and human templates. We provide three main contributions: (1) We introduce a comprehensive skills-based benchmark that can discriminate models across different human templates. This skills-based benchmark categorises prompts into sub-skills, allowing a practitioner to pinpoint not only which skills are challenging, but at what level of complexity a skill becomes challenging. (2) We gather human ratings across four templates and four T2I models for a total of >100K annotations. This allows us to understand where differences arise due to inherent ambiguity in the prompt and where they arise due to differences in metric and model quality. (3) Finally, we introduce a new QA-based auto-eval metric that is better correlated with human ratings than existing metrics for our new dataset, across different human templates, and on TIFA160.
How FaR Are Large Language Models From Agents with Theory-of-Mind?
Oct 04, 2023



"Thinking is for Doing." Humans can infer other people's mental states from observations--an ability called Theory-of-Mind (ToM)--and subsequently act pragmatically on those inferences. Existing question answering benchmarks such as ToMi ask models questions to make inferences about beliefs of characters in a story, but do not test whether models can then use these inferences to guide their actions. We propose a new evaluation paradigm for large language models (LLMs): Thinking for Doing (T4D), which requires models to connect inferences about others' mental states to actions in social scenarios. Experiments on T4D demonstrate that LLMs such as GPT-4 and PaLM 2 seemingly excel at tracking characters' beliefs in stories, but they struggle to translate this capability into strategic action. Our analysis reveals the core challenge for LLMs lies in identifying the implicit inferences about mental states without being explicitly asked about as in ToMi, that lead to choosing the correct action in T4D. To bridge this gap, we introduce a zero-shot prompting framework, Foresee and Reflect (FaR), which provides a reasoning structure that encourages LLMs to anticipate future challenges and reason about potential actions. FaR boosts GPT-4's performance from 50% to 71% on T4D, outperforming other prompting methods such as Chain-of-Thought and Self-Ask. Moreover, FaR generalizes to diverse out-of-distribution story structures and scenarios that also require ToM inferences to choose an action, consistently outperforming other methods including few-shot in-context learning.
Weakly-Supervised Learning of Visual Relations in Multimodal Pretraining
May 23, 2023



Recent work in vision-and-language pretraining has investigated supervised signals from object detection data to learn better, fine-grained multimodal representations. In this work, we take a step further and explore how we add supervision from small-scale visual relation data. In particular, we propose two pretraining approaches to contextualise visual entities in a multimodal setup. With verbalised scene graphs, we transform visual relation triplets into structured captions, and treat them as additional views of images. With masked relation prediction, we further encourage relating entities from visually masked contexts. When applied to strong baselines pretrained on large amounts of Web data, zero-shot evaluations on both coarse-grained and fine-grained tasks show the efficacy of our methods in learning multimodal representations from weakly-supervised relations data.
Measuring Progress in Fine-grained Vision-and-Language Understanding
May 12, 2023While pretraining on large-scale image-text data from the Web has facilitated rapid progress on many vision-and-language (V&L) tasks, recent work has demonstrated that pretrained models lack "fine-grained" understanding, such as the ability to recognise relationships, verbs, and numbers in images. This has resulted in an increased interest in the community to either develop new benchmarks or models for such capabilities. To better understand and quantify progress in this direction, we investigate four competitive V&L models on four fine-grained benchmarks. Through our analysis, we find that X-VLM (Zeng et al., 2022) consistently outperforms other baselines, and that modelling innovations can impact performance more than scaling Web data, which even degrades performance sometimes. Through a deeper investigation of X-VLM, we highlight the importance of both novel losses and rich data sources for learning fine-grained skills. Finally, we inspect training dynamics, and discover that for some tasks, performance peaks early in training or significantly fluctuates, never converging.
Evaluating Visual Number Discrimination in Deep Neural Networks
Mar 13, 2023



The ability to discriminate between large and small quantities is a core aspect of basic numerical competence in both humans and animals. In this work, we examine the extent to which the state-of-the-art neural networks designed for vision exhibit this basic ability. Motivated by studies in animal and infant numerical cognition, we use the numerical bisection procedure to test number discrimination in different families of neural architectures. Our results suggest that vision-specific inductive biases are helpful in numerosity discrimination, as models with such biases have lowest test errors on the task, and often have psychometric curves that qualitatively resemble those of humans and animals performing the task. However, even the strongest models, as measured on standard metrics of performance, fail to discriminate quantities in transfer experiments with differing training and testing conditions, indicating that such inductive biases might not be sufficient.