 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Delta Learning Hypothesis: Preference Tuning on Weak Data can Yield Strong Gains
Jul 08, 2025Improvements in language models are often driven by improving the quality of the data we train them on, which can be limiting when strong supervision is scarce. In this work, we show that paired preference data consisting of individually weak data points can enable gains beyond the strength of each individual data point. We formulate the delta learning hypothesis to explain this phenomenon, positing that the relative quality delta between points suffices to drive learning via preference tuning--even when supervised finetuning on the weak data hurts. We validate our hypothesis in controlled experiments and at scale, where we post-train 8B models on preference data generated by pairing a small 3B model's responses with outputs from an even smaller 1.5B model to create a meaningful delta. Strikingly, on a standard 11-benchmark evaluation suite (MATH, MMLU, etc.), our simple recipe matches the performance of Tulu 3, a state-of-the-art open model tuned from the same base model while relying on much stronger supervisors (e.g., GPT-4o). Thus, delta learning enables simpler and cheaper open recipes for state-of-the-art post-training. To better understand delta learning, we prove in logistic regression that the performance gap between two weak teacher models provides useful signal for improving a stronger student. Overall, our work shows that models can learn surprisingly well from paired data that might typically be considered weak.
Frustratingly Simple Retrieval Improves Challenging, Reasoning-Intensive Benchmarks
Jul 02, 2025Retrieval-augmented Generation (RAG) has primarily been studied in limited settings, such as factoid question answering; more challenging, reasoning-intensive benchmarks have seen limited success from minimal RAG. In this work, we challenge this prevailing view on established, reasoning-intensive benchmarks: MMLU, MMLU Pro, AGI Eval, GPQA, and MATH. We identify a key missing component in prior work: a usable, web-scale datastore aligned with the breadth of pretraining data. To this end, we introduce CompactDS: a diverse, high-quality, web-scale datastore that achieves high retrieval accuracy and subsecond latency on a single-node. The key insights are (1) most web content can be filtered out without sacrificing coverage, and a compact, high-quality subset is sufficient; and (2) combining in-memory approximate nearest neighbor (ANN) retrieval and on-disk exact search balances speed and recall. Using CompactDS, we show that a minimal RAG pipeline achieves consistent accuracy improvements across all benchmarks and model sizes (8B--70B), with relative gains of 10% on MMLU, 33% on MMLU Pro, 14% on GPQA, and 19% on MATH. No single data source suffices alone, highlighting the importance of diversity of sources (web crawls, curated math, academic papers, textbooks). Finally, we show that our carefully designed in-house datastore matches or outperforms web search engines such as Google Search, as well as recently proposed, complex agent-based RAG systems--all while maintaining simplicity, reproducibility, and self-containment. We release CompactDS and our retrieval pipeline, supporting future research exploring retrieval-based AI systems.
Spurious Rewards: Rethinking Training Signals in RLVR
Jun 12, 2025



We show that reinforcement learning with verifiable rewards (RLVR) can elicit strong mathematical reasoning in certain models even with spurious rewards that have little, no, or even negative correlation with the correct answer. For example, RLVR improves MATH-500 performance for Qwen2.5-Math-7B in absolute points by 21.4% (random reward), 13.8% (format reward), 24.1% (incorrect label), 26.0% (1-shot RL), and 27.1% (majority voting) -- nearly matching the 29.1% gained with ground truth rewards. However, the spurious rewards that work for Qwen often fail to yield gains with other model families like Llama3 or OLMo2. In particular, we find code reasoning -- thinking in code without actual code execution -- to be a distinctive Qwen2.5-Math behavior that becomes significantly more frequent after RLVR, from 65% to over 90%, even with spurious rewards. Overall, we hypothesize that, given the lack of useful reward signal, RLVR must somehow be surfacing useful reasoning representations learned during pretraining, although the exact mechanism remains a topic for future work. We suggest that future RLVR research should possibly be validated on diverse models rather than a single de facto choice, as we show that it is easy to get significant performance gains on Qwen models even with completely spurious reward signals.
Precise Information Control in Long-Form Text Generation
Jun 06, 2025A central challenge in modern language models (LMs) is intrinsic hallucination: the generation of information that is plausible but unsubstantiated relative to input context. To study this problem, we propose Precise Information Control (PIC), a new task formulation that requires models to generate long-form outputs grounded in a provided set of short self-contained statements, known as verifiable claims, without adding any unsupported ones. For comprehensiveness, PIC includes a full setting that tests a model's ability to include exactly all input claims, and a partial setting that requires the model to selectively incorporate only relevant claims. We present PIC-Bench, a benchmark of eight long-form generation tasks (e.g., summarization, biography generation) adapted to the PIC setting, where LMs are supplied with well-formed, verifiable input claims. Our evaluation of a range of open and proprietary LMs on PIC-Bench reveals that, surprisingly, state-of-the-art LMs still intrinsically hallucinate in over 70% of outputs. To alleviate this lack of faithfulness, we introduce a post-training framework, using a weakly supervised preference data construction method, to train an 8B PIC-LM with stronger PIC ability--improving from 69.1% to 91.0% F1 in the full PIC setting. When integrated into end-to-end factual generation pipelines, PIC-LM improves exact match recall by 17.1% on ambiguous QA with retrieval, and factual precision by 30.5% on a birthplace verification task, underscoring the potential of precisely grounded generation.
ReasonIR: Training Retrievers for Reasoning Tasks
Apr 29, 2025We present ReasonIR-8B, the first retriever specifically trained for general reasoning tasks. Existing retrievers have shown limited gains on reasoning tasks, in part because existing training datasets focus on short factual queries tied to documents that straightforwardly answer them. We develop a synthetic data generation pipeline that, for each document, our pipeline creates a challenging and relevant query, along with a plausibly related but ultimately unhelpful hard negative. By training on a mixture of our synthetic data and existing public data, ReasonIR-8B achieves a new state-of-the-art of 29.9 nDCG@10 without reranker and 36.9 nDCG@10 with reranker on BRIGHT, a widely-used reasoning-intensive information retrieval (IR) benchmark. When applied to RAG tasks, ReasonIR-8B improves MMLU and GPQA performance by 6.4% and 22.6% respectively, relative to the closed-book baseline, outperforming other retrievers and search engines. In addition, ReasonIR-8B uses test-time compute more effectively: on BRIGHT, its performance consistently increases with longer and more information-rich rewritten queries; it continues to outperform other retrievers when combined with an LLM reranker. Our training recipe is general and can be easily extended to future LLMs; to this end, we open-source our code, data, and model.
A False Sense of Privacy: Evaluating Textual Data Sanitization Beyond Surface-level Privacy Leakage
Apr 28, 2025Sanitizing sensitive text data typically involves removing personally identifiable information (PII) or generating synthetic data under the assumption that these methods adequately protect privacy; however, their effectiveness is often only assessed by measuring the leakage of explicit identifiers but ignoring nuanced textual markers that can lead to re-identification. We challenge the above illusion of privacy by proposing a new framework that evaluates re-identification attacks to quantify individual privacy risks upon data release. Our approach shows that seemingly innocuous auxiliary information -- such as routine social activities -- can be used to infer sensitive attributes like age or substance use history from sanitized data. For instance, we demonstrate that Azure's commercial PII removal tool fails to protect 74\% of information in the MedQA dataset. Although differential privacy mitigates these risks to some extent, it significantly reduces the utility of the sanitized text for downstream tasks. Our findings indicate that current sanitization techniques offer a \textit{false sense of privacy}, highlighting the need for more robust methods that protect against semantic-level information leakage.
ParaPO: Aligning Language Models to Reduce Verbatim Reproduction of Pre-training Data
Apr 20, 2025Language models (LMs) can memorize and reproduce segments from their pretraining data verbatim even in non-adversarial settings, raising concerns about copyright, plagiarism, privacy, and creativity. We introduce Paraphrase Preference Optimization (ParaPO), a post-training method that fine-tunes LMs to reduce unintentional regurgitation while preserving their overall utility. ParaPO trains LMs to prefer paraphrased versions of memorized segments over the original verbatim content from the pretraining data. To maintain the ability to recall famous quotations when appropriate, we develop a variant of ParaPO that uses system prompts to control regurgitation behavior. In our evaluation on Llama3.1-8B, ParaPO consistently reduces regurgitation across all tested datasets (e.g., reducing the regurgitation metric from 17.3 to 12.9 in creative writing), whereas unlearning methods used in prior work to mitigate regurgitation are less effective outside their targeted unlearned domain (from 17.3 to 16.9). When applied to the instruction-tuned Tulu3-8B model, ParaPO with system prompting successfully preserves famous quotation recall while reducing unintentional regurgitation (from 8.7 to 6.3 in creative writing) when prompted not to regurgitate. In contrast, without ParaPO tuning, prompting the model not to regurgitate produces only a marginal reduction (8.7 to 8.4).
DataDecide: How to Predict Best Pretraining Data with Small Experiments
Apr 15, 2025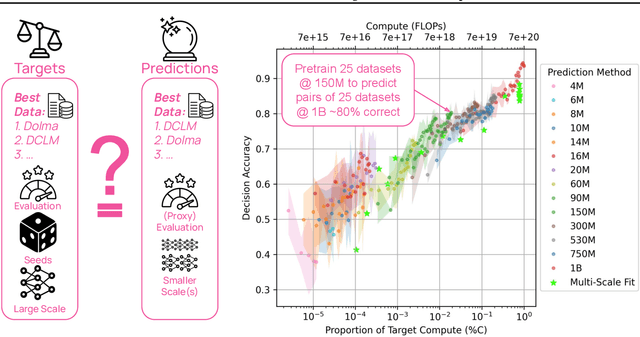
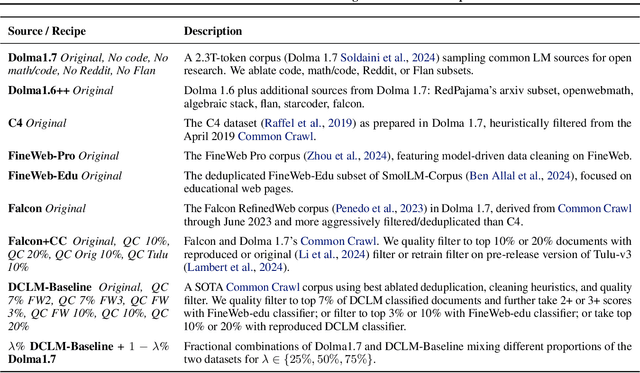
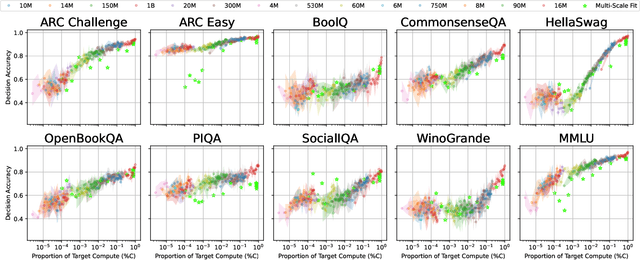
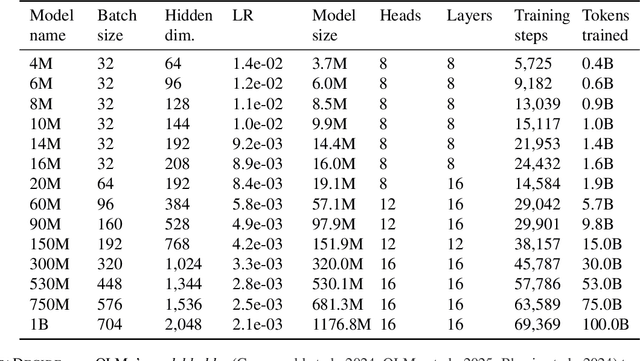
Because large language models are expensive to pretrain on different datasets, using smaller-scale experiments to decide on data is crucial for reducing costs. Which benchmarks and methods of making decisions from observed performance at small scale most accurately predict the datasets that yield the best large models? To empower open exploration of this question, we release models, data, and evaluations in DataDecide -- the most extensive open suite of models over differences in data and scale. We conduct controlled pretraining experiments across 25 corpora with differing sources, deduplication, and filtering up to 100B tokens, model sizes up to 1B parameters, and 3 random seeds. We find that the ranking of models at a single, small size (e.g., 150M parameters) is a strong baseline for predicting best models at our larger target scale (1B) (~80% of com parisons correct). No scaling law methods among 8 baselines exceed the compute-decision frontier of single-scale predictions, but DataDecide can measure improvement in future scaling laws. We also identify that using continuous likelihood metrics as proxies in small experiments makes benchmarks including MMLU, ARC, HellaSwag, MBPP, and HumanEval >80% predictable at the target 1B scale with just 0.01% of the compute.
OLMoTrace: Tracing Language Model Outputs Back to Trillions of Training Tokens
Apr 09, 2025We present OLMoTrace, the first system that traces the outputs of language models back to their full, multi-trillion-token training data in real time. OLMoTrace finds and shows verbatim matches between segments of language model output and documents in the training text corpora. Powered by an extended version of infini-gram (Liu et al., 2024), our system returns tracing results within a few seconds. OLMoTrace can help users understand the behavior of language models through the lens of their training data. We showcase how it can be used to explore fact checking, hallucination, and the creativity of language models. OLMoTrace is publicly available and fully open-source.
EvalTree: Profiling Language Model Weaknesses via Hierarchical Capability Trees
Mar 11, 2025An ideal model evaluation should achieve two goals: identifying where the model fails and providing actionable improvement guidance. Toward these goals for Language Model (LM) evaluations, we formulate the problem of generating a weakness profile, a set of weaknesses expressed in natural language, given an LM's performance on every individual instance in a benchmark. We introduce a suite of quantitative assessments to compare different weakness profiling methods. We also propose a weakness profiling method EvalTree. It constructs a capability tree where each node represents a capability described in natural language and is linked to a subset of benchmark instances that specifically evaluate this capability; it then extracts nodes where the LM performs poorly to generate a weakness profile. On the MATH and WildChat benchmarks, we show that EvalTree outperforms baseline weakness profiling methods by identifying weaknesses more precisely and comprehensively. Weakness profiling further enables weakness-guided data collection, and training data collection guided by EvalTree-identified weaknesses improves LM performance more than other data collection strategies. We also show how EvalTree exposes flaws in Chatbot Arena's human-voter-based evaluation practice. To facilitate future work, we release our code and an interface that allows practitioners to interactively explore the capability trees built by EvalTree.