 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrustratingly Simple Retrieval Improves Challenging, Reasoning-Intensive Benchmarks
Jul 02, 2025Retrieval-augmented Generation (RAG) has primarily been studied in limited settings, such as factoid question answering; more challenging, reasoning-intensive benchmarks have seen limited success from minimal RAG. In this work, we challenge this prevailing view on established, reasoning-intensive benchmarks: MMLU, MMLU Pro, AGI Eval, GPQA, and MATH. We identify a key missing component in prior work: a usable, web-scale datastore aligned with the breadth of pretraining data. To this end, we introduce CompactDS: a diverse, high-quality, web-scale datastore that achieves high retrieval accuracy and subsecond latency on a single-node. The key insights are (1) most web content can be filtered out without sacrificing coverage, and a compact, high-quality subset is sufficient; and (2) combining in-memory approximate nearest neighbor (ANN) retrieval and on-disk exact search balances speed and recall. Using CompactDS, we show that a minimal RAG pipeline achieves consistent accuracy improvements across all benchmarks and model sizes (8B--70B), with relative gains of 10% on MMLU, 33% on MMLU Pro, 14% on GPQA, and 19% on MATH. No single data source suffices alone, highlighting the importance of diversity of sources (web crawls, curated math, academic papers, textbooks). Finally, we show that our carefully designed in-house datastore matches or outperforms web search engines such as Google Search, as well as recently proposed, complex agent-based RAG systems--all while maintaining simplicity, reproducibility, and self-containment. We release CompactDS and our retrieval pipeline, supporting future research exploring retrieval-based AI systems.
HREF: Human Response-Guided Evaluation of Instruction Following in Language Models
Dec 20, 2024Evaluating the capability of Large Language Models (LLMs) in following instructions has heavily relied on a powerful LLM as the judge, introducing unresolved biases that deviate the judgments from human judges. In this work, we reevaluate various choices for automatic evaluation on a wide range of instruction-following tasks. We experiment with methods that leverage human-written responses and observe that they enhance the reliability of automatic evaluations across a wide range of tasks, resulting in up to a 3.2% improvement in agreement with human judges. We also discovered that human-written responses offer an orthogonal perspective to model-generated responses in following instructions and should be used as an additional context when comparing model responses. Based on these observations, we develop a new evaluation benchmark, Human Response-Guided Evaluation of Instruction Following (HREF), comprising 4,258 samples across 11 task categories with a composite evaluation setup, employing a composite evaluation setup that selects the most reliable method for each category. In addition to providing reliable evaluation, HREF emphasizes individual task performance and is free from contamination. Finally, we study the impact of key design choices in HREF, including the size of the evaluation set, the judge model, the baseline model, and the prompt template. We host a live leaderboard that evaluates LLMs on the private evaluation set of HREF.
Dolma: an Open Corpus of Three Trillion Tokens for Language Model Pretraining Research
Jan 31, 2024



Language models have become a critical technology to tackling a wide range of natural language processing tasks, yet many details about how the best-performing language models were developed are not reported. In particular, information about their pretraining corpora is seldom discussed: commercial language models rarely provide any information about their data; even open models rarely release datasets they are trained on, or an exact recipe to reproduce them. As a result, it is challenging to conduct certain threads of language modeling research, such as understanding how training data impacts model capabilities and shapes their limitations. To facilitate open research on language model pretraining, we release Dolma, a three trillion tokens English corpus, built from a diverse mixture of web content, scientific papers, code, public-domain books, social media, and encyclopedic materials. In addition, we open source our data curation toolkit to enable further experimentation and reproduction of our work. In this report, we document Dolma, including its design principles, details about its construction, and a summary of its contents. We interleave this report with analyses and experimental results from training language models on intermediate states of Dolma to share what we have learned about important data curation practices, including the role of content or quality filters, deduplication, and multi-source mixing. Dolma has been used to train OLMo, a state-of-the-art, open language model and framework designed to build and study the science of language modeling.
FActScore: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text Generation
May 23, 2023



Evaluating the factuality of long-form text generated by large language models (LMs) is non-trivial because (1) generations often contain a mixture of supported and unsupported pieces of information, making binary judgments of quality inadequate, and (2) human evaluation is time-consuming and costly. In this paper, we introduce FActScore (Factual precision in Atomicity Score), a new evaluation that breaks a generation into a series of atomic facts and computes the percentage of atomic facts supported by a reliable knowledge source. We conduct an extensive human evaluation to obtain FActScores of people biographies generated by several state-of-the-art commercial LMs -- InstructGPT, ChatGPT, and the retrieval-augmented PerplexityAI -- and report new analysis demonstrating the need for such a fine-grained score (e.g., ChatGPT only achieves 58%). Since human evaluation is costly, we also introduce an automated model that estimates FActScore, using retrieval and a strong language model, with less than a 2% error rate. Finally, we use this automated metric to evaluate 6,500 generations from a new set of 13 recent LMs that would have cost $26K if evaluated by humans, with various findings: GPT-4 and ChatGPT are more factual than public models, and Vicuna and Alpaca are some of the best public models.
Z-ICL: Zero-Shot In-Context Learning with Pseudo-Demonstrations
Dec 19, 2022Although large language models can be prompted for both zero- and few-shot learning, performance drops significantly when no demonstrations are available. In this paper, we introduce Z-ICL, a new zero-shot method that closes the gap by constructing pseudo-demonstrations for a given test input using a raw text corpus. Concretely, pseudo-demonstrations are constructed by (1) finding the nearest neighbors to the test input from the corpus and pairing them with random task labels, and (2) applying a set of techniques to reduce the amount of direct copying the model does from the resulting demonstrations. Evaluation on nine classification datasets shows that Z-ICL outperforms previous zero-shot methods by a significant margin, and is on par with in-context learning with labeled training data in the few-shot setting. Overall, Z-ICL provides a significantly higher estimate of the zero-shot performance levels of a model, and supports future efforts to develop better pseudo-demonstrations that further improve zero-shot results.
Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?
Feb 25, 2022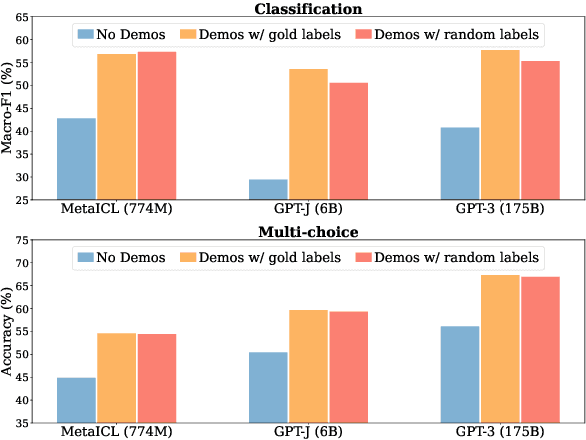

Large language models (LMs) are able to in-context learn -- perform a new task via inference alone by conditioning on a few input-label pairs (demonstrations) and making predictions for new inputs. However, there has been little understanding of how the model learns and which aspects of the demonstrations contribute to end task performance. In this paper, we show that ground truth demonstrations are in fact not required -- randomly replacing labels in the demonstrations barely hurts performance, consistently over 12 different models including GPT-3. Instead, we find that other aspects of the demonstrations are the key drivers of end task performance, including the fact that they provide a few examples of (1) the label space, (2) the distribution of the input text, and (3) the overall format of the sequence. Together, our analysis provides a new way of understanding how and why in-context learning works, while opening up new questions about how much can be learned from large language models through inference alone.