 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHairCLIP: Design Your Hair by Text and Reference Image
Dec 09, 2021
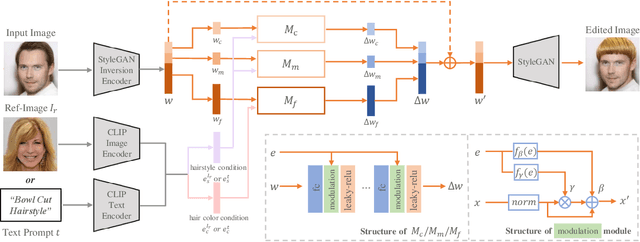
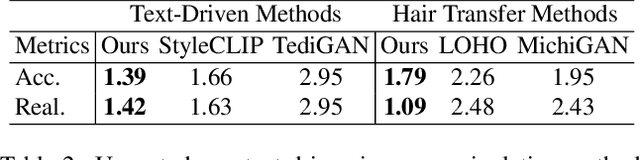

Hair editing is an interesting and challenging problem in computer vision and graphics. Many existing methods require well-drawn sketches or masks as conditional inputs for editing, however these interactions are neither straightforward nor efficient. In order to free users from the tedious interaction process, this paper proposes a new hair editing interaction mode, which enables manipulating hair attributes individually or jointly based on the texts or reference images provided by users. For this purpose, we encode the image and text conditions in a shared embedding space and propose a unified hair editing framework by leveraging the powerful image text representation capability of the Contrastive Language-Image Pre-Training (CLIP) model. With the carefully designed network structures and loss functions, our framework can perform high-quality hair editing in a disentangled manner. Extensive experiments demonstrate the superiority of our approach in terms of manipulation accuracy, visual realism of editing results, and irrelevant attribute preservation. Project repo is https://github.com/wty-ustc/HairCLIP.
PeCo: Perceptual Codebook for BERT Pre-training of Vision Transformers
Nov 24, 2021
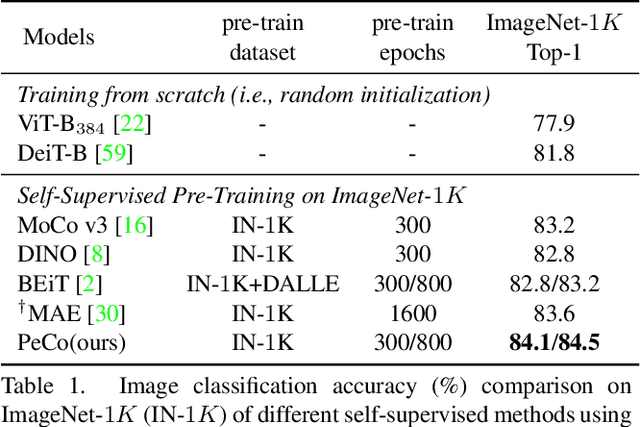
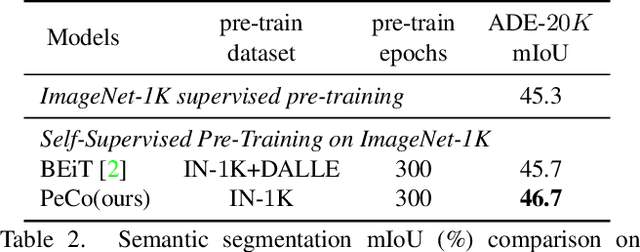

This paper explores a better codebook for BERT pre-training of vision transformers. The recent work BEiT successfully transfers BERT pre-training from NLP to the vision field. It directly adopts one simple discrete VAE as the visual tokenizer, but has not considered the semantic level of the resulting visual tokens. By contrast, the discrete tokens in NLP field are naturally highly semantic. This difference motivates us to learn a perceptual codebook. And we surprisingly find one simple yet effective idea: enforcing perceptual similarity during the dVAE training. We demonstrate that the visual tokens generated by the proposed perceptual codebook do exhibit better semantic meanings, and subsequently help pre-training achieve superior transfer performance in various downstream tasks. For example, we achieve 84.5 Top-1 accuracy on ImageNet-1K with ViT-B backbone, outperforming the competitive method BEiT by +1.3 with the same pre-training epochs. It can also improve the performance of object detection and segmentation tasks on COCO val by +1.3 box AP and +1.0 mask AP, semantic segmentation on ADE20k by +1.0 mIoU, The code and models will be available at \url{https://github.com/microsoft/PeCo}.
Speech Pattern based Black-box Model Watermarking for Automatic Speech Recognition
Oct 19, 2021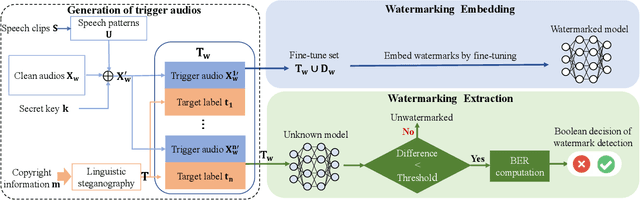

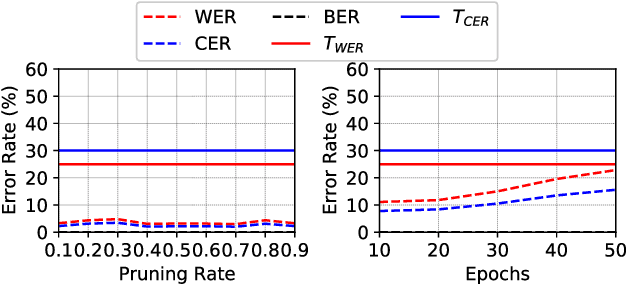

As an effective method for intellectual property (IP) protection, model watermarking technology has been applied on a wide variety of deep neural networks (DNN), including speech classification models. However, how to design a black-box watermarking scheme for automatic speech recognition (ASR) models is still an unsolved problem, which is a significant demand for protecting remote ASR Application Programming Interface (API) deployed in cloud servers. Due to conditional independence assumption and label-detection-based evasion attack risk of ASR models, the black-box model watermarking scheme for speech classification models cannot apply to ASR models. In this paper, we propose the first black-box model watermarking framework for protecting the IP of ASR models. Specifically, we synthesize trigger audios by spreading the speech clips of model owners over the entire input audios and labeling the trigger audios with the stego texts, which hides the authorship information with linguistic steganography. Experiments on the state-of-the-art open-source ASR system DeepSpeech demonstrate the feasibility of the proposed watermarking scheme, which is robust against five kinds of attacks and has little impact on accuracy.
Unsupervised Finetuning
Oct 18, 2021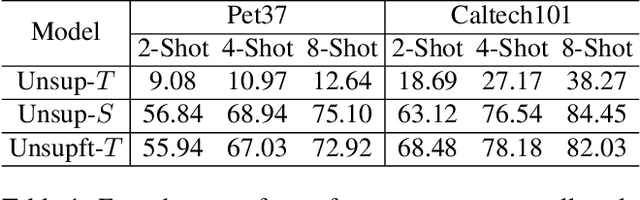

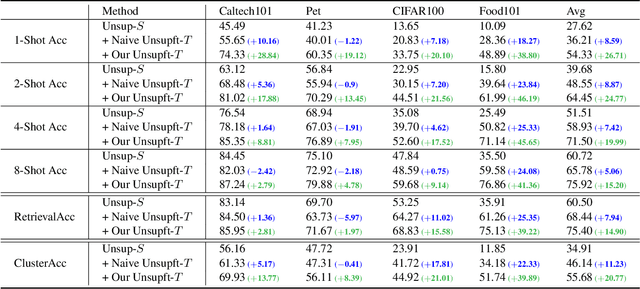
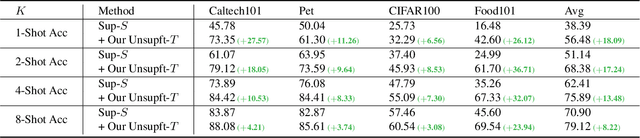
This paper studies "unsupervised finetuning", the symmetrical problem of the well-known "supervised finetuning". Given a pretrained model and small-scale unlabeled target data, unsupervised finetuning is to adapt the representation pretrained from the source domain to the target domain so that better transfer performance can be obtained. This problem is more challenging than the supervised counterpart, as the low data density in the small-scale target data is not friendly for unsupervised learning, leading to the damage of the pretrained representation and poor representation in the target domain. In this paper, we find the source data is crucial when shifting the finetuning paradigm from supervise to unsupervise, and propose two simple and effective strategies to combine source and target data into unsupervised finetuning: "sparse source data replaying", and "data mixing". The motivation of the former strategy is to add a small portion of source data back to occupy their pretrained representation space and help push the target data to reside in a smaller compact space; and the motivation of the latter strategy is to increase the data density and help learn more compact representation. To demonstrate the effectiveness of our proposed ``unsupervised finetuning'' strategy, we conduct extensive experiments on multiple different target datasets, which show better transfer performance than the naive strategy.
Temporal RoI Align for Video Object Recognition
Sep 11, 2021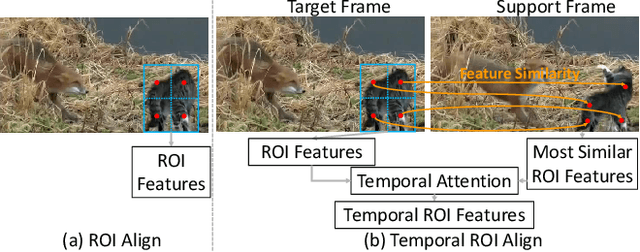
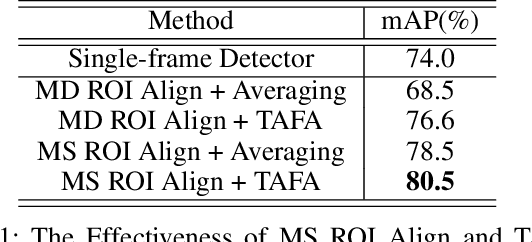
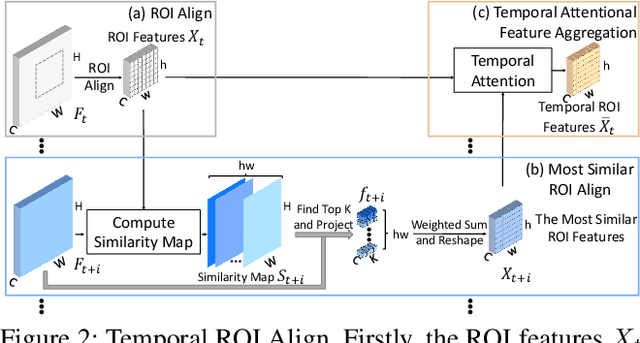

Video object detection is challenging in the presence of appearance deterioration in certain video frames. Therefore, it is a natural choice to aggregate temporal information from other frames of the same video into the current frame. However, RoI Align, as one of the most core procedures of video detectors, still remains extracting features from a single-frame feature map for proposals, making the extracted RoI features lack temporal information from videos. In this work, considering the features of the same object instance are highly similar among frames in a video, a novel Temporal RoI Align operator is proposed to extract features from other frames feature maps for current frame proposals by utilizing feature similarity. The proposed Temporal RoI Align operator can extract temporal information from the entire video for proposals. We integrate it into single-frame video detectors and other state-of-the-art video detectors, and conduct quantitative experiments to demonstrate that the proposed Temporal RoI Align operator can consistently and significantly boost the performance. Besides, the proposed Temporal RoI Align can also be applied into video instance segmentation. Codes are available at https://github.com/open-mmlab/mmtracking
ISNet: Integrate Image-Level and Semantic-Level Context for Semantic Segmentation
Aug 27, 2021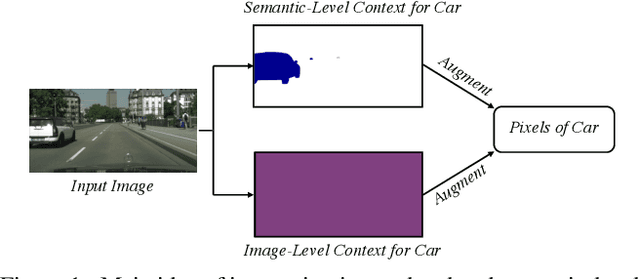

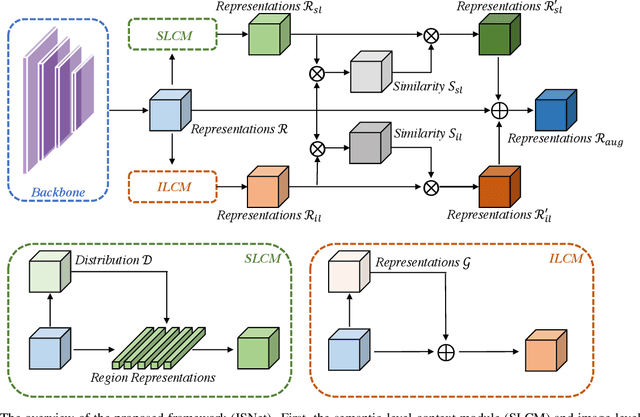
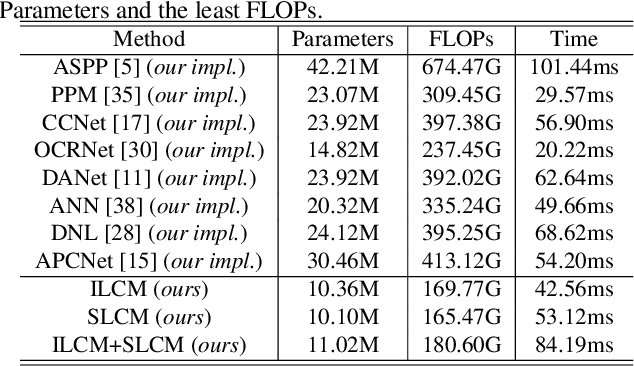
Co-occurrent visual pattern makes aggregating contextual information a common paradigm to enhance the pixel representation for semantic image segmentation. The existing approaches focus on modeling the context from the perspective of the whole image, i.e., aggregating the image-level contextual information. Despite impressive, these methods weaken the significance of the pixel representations of the same category, i.e., the semantic-level contextual information. To address this, this paper proposes to augment the pixel representations by aggregating the image-level and semantic-level contextual information, respectively. First, an image-level context module is designed to capture the contextual information for each pixel in the whole image. Second, we aggregate the representations of the same category for each pixel where the category regions are learned under the supervision of the ground-truth segmentation. Third, we compute the similarities between each pixel representation and the image-level contextual information, the semantic-level contextual information, respectively. At last, a pixel representation is augmented by weighted aggregating both the image-level contextual information and the semantic-level contextual information with the similarities as the weights. Integrating the image-level and semantic-level context allows this paper to report state-of-the-art accuracy on four benchmarks, i.e., ADE20K, LIP, COCOStuff and Cityscapes.
Poison Ink: Robust and Invisible Backdoor Attack
Aug 14, 2021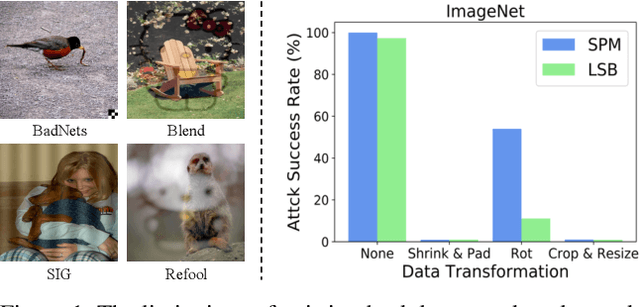
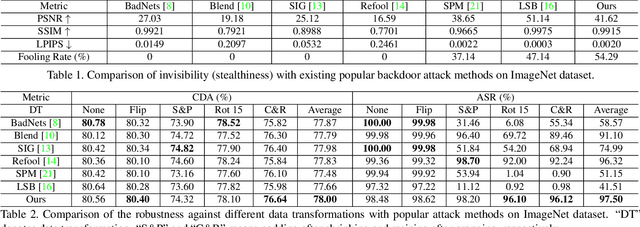
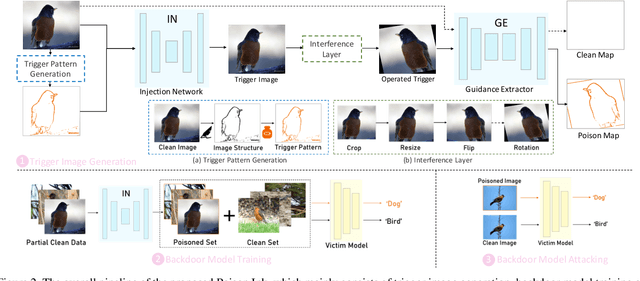

Recent research shows deep neural networks are vulnerable to different types of attacks, such as adversarial attack, data poisoning attack and backdoor attack. Among them, backdoor attack is the most cunning one and can occur in almost every stage of deep learning pipeline. Therefore, backdoor attack has attracted lots of interests from both academia and industry. However, most existing backdoor attack methods are either visible or fragile to some effortless pre-processing such as common data transformations. To address these limitations, we propose a robust and invisible backdoor attack called "Poison Ink". Concretely, we first leverage the image structures as target poisoning areas, and fill them with poison ink (information) to generate the trigger pattern. As the image structure can keep its semantic meaning during the data transformation, such trigger pattern is inherently robust to data transformations. Then we leverage a deep injection network to embed such trigger pattern into the cover image to achieve stealthiness. Compared to existing popular backdoor attack methods, Poison Ink outperforms both in stealthiness and robustness. Through extensive experiments, we demonstrate Poison Ink is not only general to different datasets and network architectures, but also flexible for different attack scenarios. Besides, it also has very strong resistance against many state-of-the-art defense techniques.
Exploring Structure Consistency for Deep Model Watermarking
Aug 05, 2021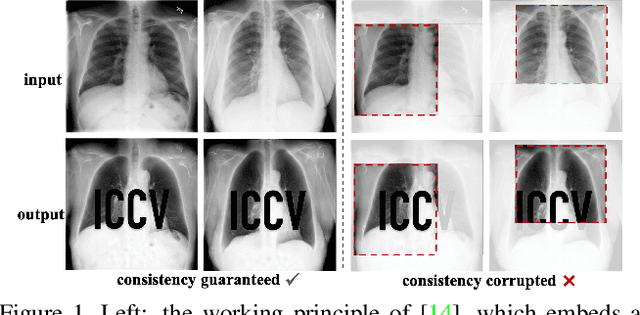
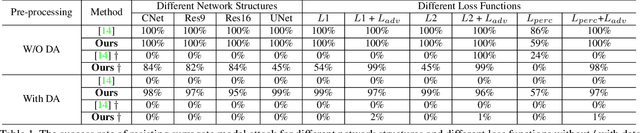

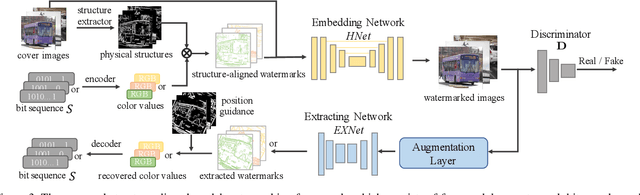
The intellectual property (IP) of Deep neural networks (DNNs) can be easily ``stolen'' by surrogate model attack. There has been significant progress in solutions to protect the IP of DNN models in classification tasks. However, little attention has been devoted to the protection of DNNs in image processing tasks. By utilizing consistent invisible spatial watermarks, one recent work first considered model watermarking for deep image processing networks and demonstrated its efficacy in many downstream tasks. Nevertheless, it highly depends on the hypothesis that the embedded watermarks in the network outputs are consistent. When the attacker uses some common data augmentation attacks (e.g., rotate, crop, and resize) during surrogate model training, it will totally fail because the underlying watermark consistency is destroyed. To mitigate this issue, we propose a new watermarking methodology, namely ``structure consistency'', based on which a new deep structure-aligned model watermarking algorithm is designed. Specifically, the embedded watermarks are designed to be aligned with physically consistent image structures, such as edges or semantic regions. Experiments demonstrate that our method is much more robust than the baseline method in resisting data augmentation attacks for model IP protection. Besides that, we further test the generalization ability and robustness of our method to a broader range of circumvention attacks.
Cascaded Residual Density Network for Crowd Counting
Jul 29, 2021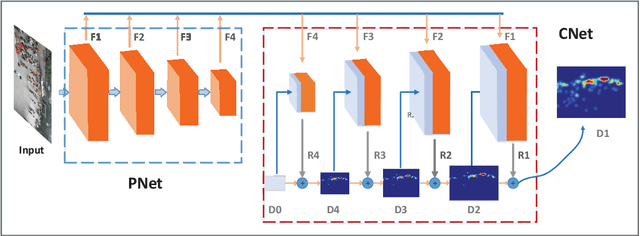
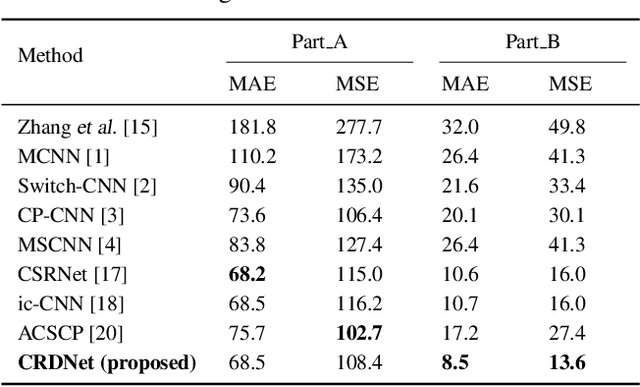
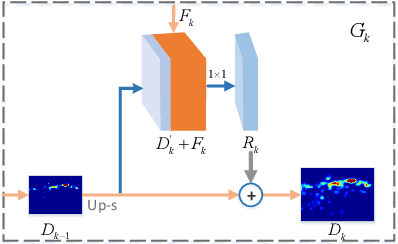
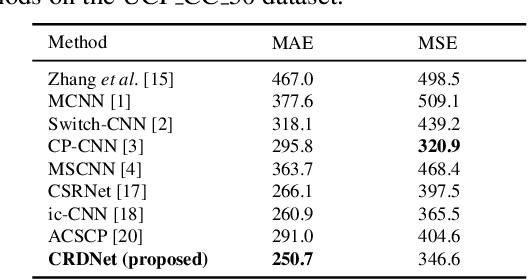
Crowd counting is a challenging task due to the issues such as scale variation and perspective variation in real crowd scenes. In this paper, we propose a novel Cascaded Residual Density Network (CRDNet) in a coarse-to-fine approach to generate the high-quality density map for crowd counting more accurately. (1) We estimate the residual density maps by multi-scale pyramidal features through cascaded residual density modules. It can improve the quality of density map layer by layer effectively. (2) A novel additional local count loss is presented to refine the accuracy of crowd counting, which reduces the errors of pixel-wise Euclidean loss by restricting the number of people in the local crowd areas. Experiments on two public benchmark datasets show that the proposed method achieves effective improvement compared with the state-of-the-art methods.
Abnormal Behavior Detection Based on Target Analysis
Jul 29, 2021
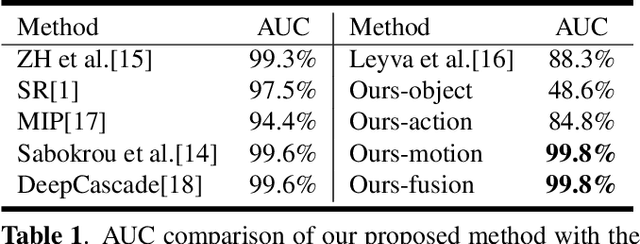
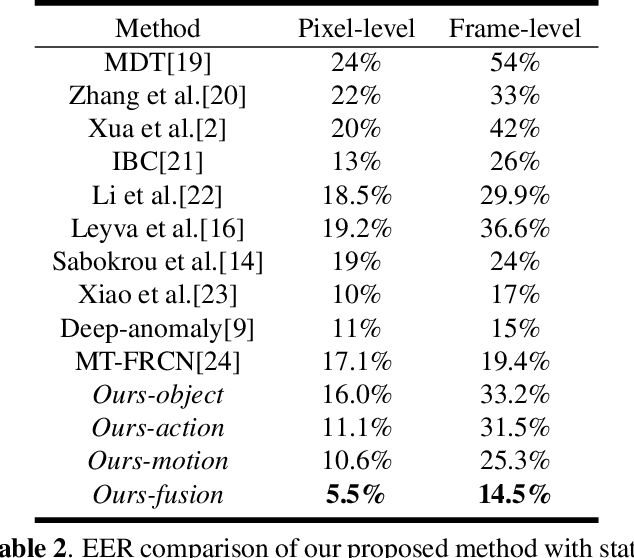

Abnormal behavior detection in surveillance video is a pivotal part of the intelligent city. Most existing methods only consider how to detect anomalies, with less considering to explain the reason of the anomalies. We investigate an orthogonal perspective based on the reason of these abnormal behaviors. To this end, we propose a multivariate fusion method that analyzes each target through three branches: object, action and motion. The object branch focuses on the appearance information, the motion branch focuses on the distribution of the motion features, and the action branch focuses on the action category of the target. The information that these branches focus on is different, and they can complement each other and jointly detect abnormal behavior. The final abnormal score can then be obtained by combining the abnormal scores of the three branches.