 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Finetuning
Oct 18, 2021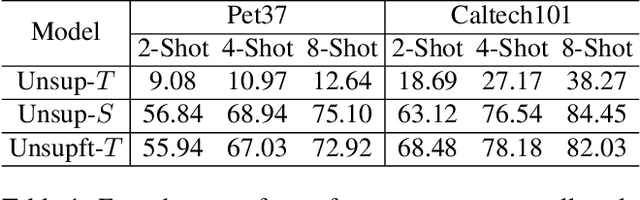

This paper studies "unsupervised finetuning", the symmetrical problem of the well-known "supervised finetuning". Given a pretrained model and small-scale unlabeled target data, unsupervised finetuning is to adapt the representation pretrained from the source domain to the target domain so that better transfer performance can be obtained. This problem is more challenging than the supervised counterpart, as the low data density in the small-scale target data is not friendly for unsupervised learning, leading to the damage of the pretrained representation and poor representation in the target domain. In this paper, we find the source data is crucial when shifting the finetuning paradigm from supervise to unsupervise, and propose two simple and effective strategies to combine source and target data into unsupervised finetuning: "sparse source data replaying", and "data mixing". The motivation of the former strategy is to add a small portion of source data back to occupy their pretrained representation space and help push the target data to reside in a smaller compact space; and the motivation of the latter strategy is to increase the data density and help learn more compact representation. To demonstrate the effectiveness of our proposed ``unsupervised finetuning'' strategy, we conduct extensive experiments on multiple different target datasets, which show better transfer performance than the naive strategy.
Improve Unsupervised Pretraining for Few-label Transfer
Jul 26, 2021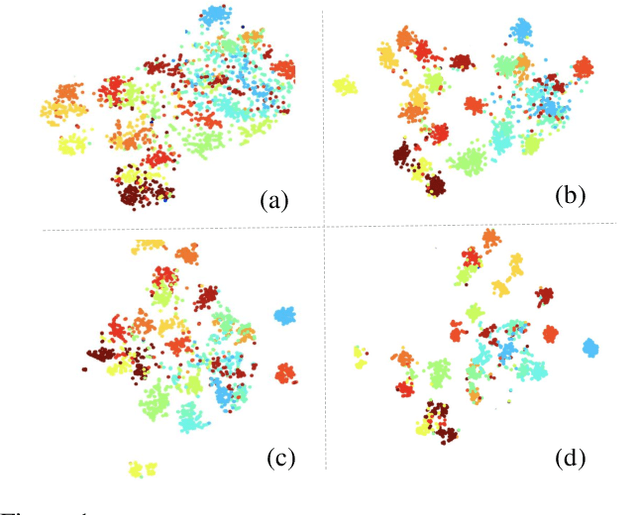
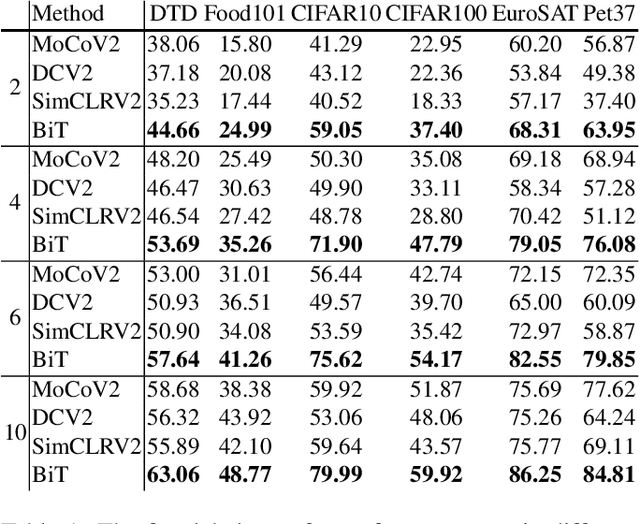
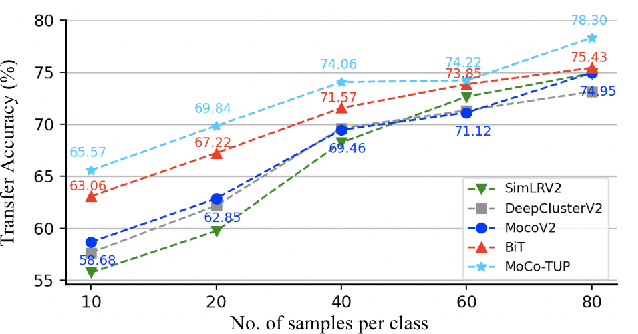
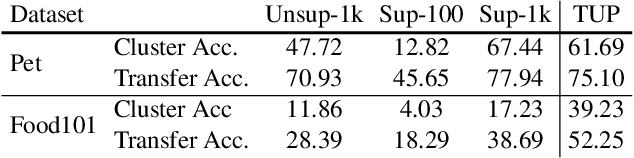
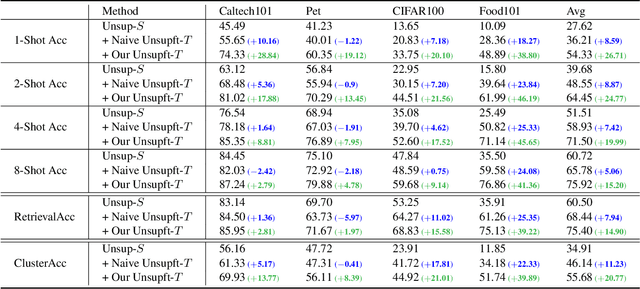
Unsupervised pretraining has achieved great success and many recent works have shown unsupervised pretraining can achieve comparable or even slightly better transfer performance than supervised pretraining on downstream target datasets. But in this paper, we find this conclusion may not hold when the target dataset has very few labeled samples for finetuning, \ie, few-label transfer. We analyze the possible reason from the clustering perspective: 1) The clustering quality of target samples is of great importance to few-label transfer; 2) Though contrastive learning is essential to learn how to cluster, its clustering quality is still inferior to supervised pretraining due to lack of label supervision. Based on the analysis, we interestingly discover that only involving some unlabeled target domain into the unsupervised pretraining can improve the clustering quality, subsequently reducing the transfer performance gap with supervised pretraining. This finding also motivates us to propose a new progressive few-label transfer algorithm for real applications, which aims to maximize the transfer performance under a limited annotation budget. To support our analysis and proposed method, we conduct extensive experiments on nine different target datasets. Experimental results show our proposed method can significantly boost the few-label transfer performance of unsupervised pretraining.
Are Fewer Labels Possible for Few-shot Learning?
Dec 10, 2020
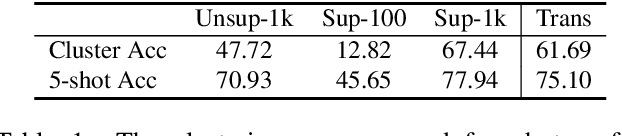
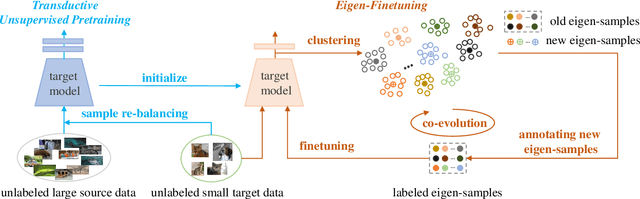
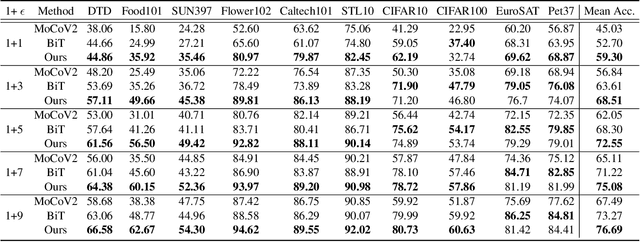
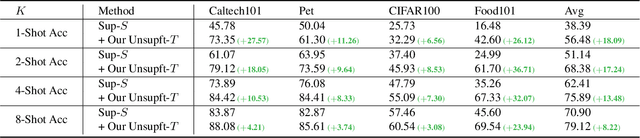
Few-shot learning is challenging due to its very limited data and labels. Recent studies in big transfer (BiT) show that few-shot learning can greatly benefit from pretraining on large scale labeled dataset in a different domain. This paper asks a more challenging question: "can we use as few as possible labels for few-shot learning in both pretraining (with no labels) and fine-tuning (with fewer labels)?". Our key insight is that the clustering of target samples in the feature space is all we need for few-shot finetuning. It explains why the vanilla unsupervised pretraining (poor clustering) is worse than the supervised one. In this paper, we propose transductive unsupervised pretraining that achieves a better clustering by involving target data even though its amount is very limited. The improved clustering result is of great value for identifying the most representative samples ("eigen-samples") for users to label, and in return, continued finetuning with the labeled eigen-samples further improves the clustering. Thus, we propose eigen-finetuning to enable fewer shot learning by leveraging the co-evolution of clustering and eigen-samples in the finetuning. We conduct experiments on 10 different few-shot target datasets, and our average few-shot performance outperforms both vanilla inductive unsupervised transfer and supervised transfer by a large margin. For instance, when each target category only has 10 labeled samples, the mean accuracy gain over the above two baselines is 9.2% and 3.42 respectively.
Density-Aware Graph for Deep Semi-Supervised Visual Recognition
Mar 30, 2020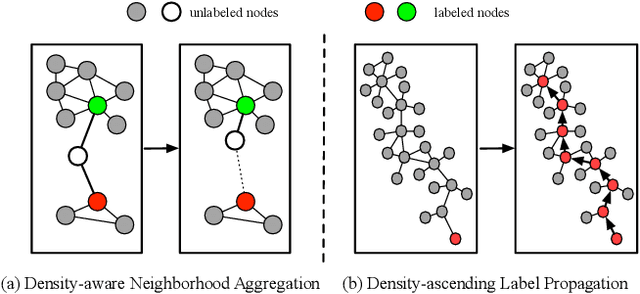

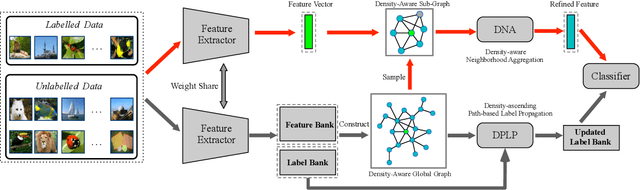
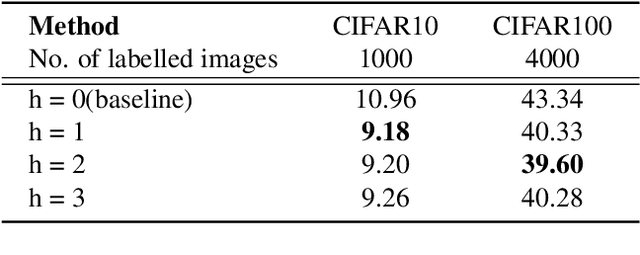
Semi-supervised learning (SSL) has been extensively studied to improve the generalization ability of deep neural networks for visual recognition. To involve the unlabelled data, most existing SSL methods are based on common density-based cluster assumption: samples lying in the same high-density region are likely to belong to the same class, including the methods performing consistency regularization or generating pseudo-labels for the unlabelled images. Despite their impressive performance, we argue three limitations exist: 1) Though the density information is demonstrated to be an important clue, they all use it in an implicit way and have not exploited it in depth. 2) For feature learning, they often learn the feature embedding based on the single data sample and ignore the neighborhood information. 3) For label-propagation based pseudo-label generation, it is often done offline and difficult to be end-to-end trained with feature learning. Motivated by these limitations, this paper proposes to solve the SSL problem by building a novel density-aware graph, based on which the neighborhood information can be easily leveraged and the feature learning and label propagation can also be trained in an end-to-end way. Specifically, we first propose a new Density-aware Neighborhood Aggregation(DNA) module to learn more discriminative features by incorporating the neighborhood information in a density-aware manner. Then a novel Density-ascending Path based Label Propagation(DPLP) module is proposed to generate the pseudo-labels for unlabeled samples more efficiently according to the feature distribution characterized by density. Finally, the DNA module and DPLP module evolve and improve each other end-to-end.
Memory-Based Neighbourhood Embedding for Visual Recognition
Aug 14, 2019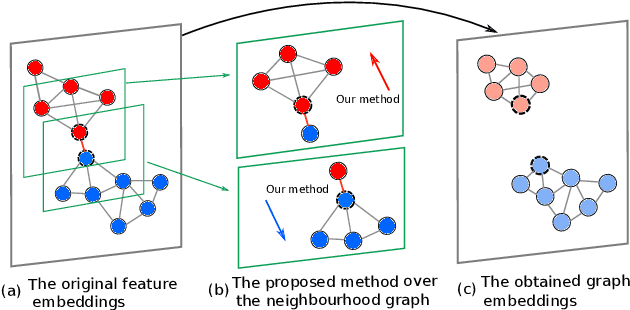
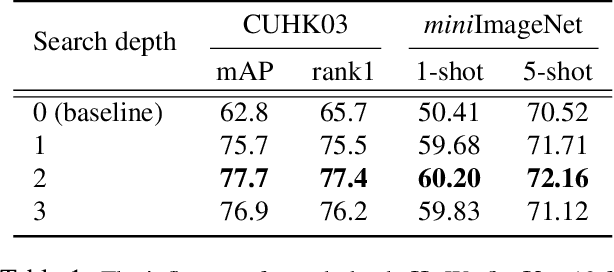
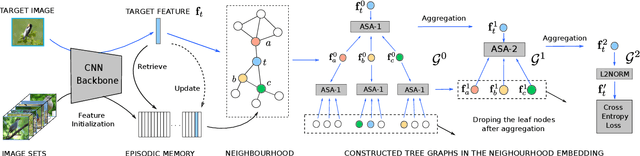
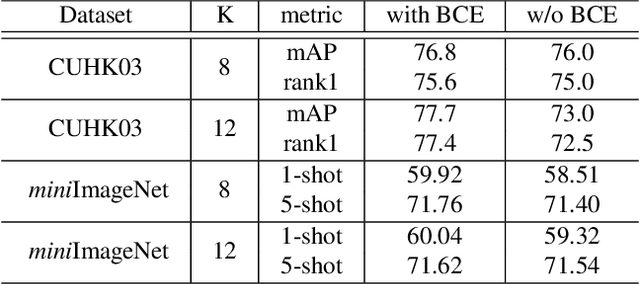
Learning discriminative image feature embeddings is of great importance to visual recognition. To achieve better feature embeddings, most current methods focus on designing different network structures or loss functions, and the estimated feature embeddings are usually only related to the input images. In this paper, we propose Memory-based Neighbourhood Embedding (MNE) to enhance a general CNN feature by considering its neighbourhood. The method aims to solve two critical problems, i.e., how to acquire more relevant neighbours in the network training and how to aggregate the neighbourhood information for a more discriminative embedding. We first augment an episodic memory module into the network, which can provide more relevant neighbours for both training and testing. Then the neighbours are organized in a tree graph with the target instance as the root node. The neighbourhood information is gradually aggregated to the root node in a bottom-up manner, and aggregation weights are supervised by the class relationships between the nodes. We apply MNE on image search and few shot learning tasks. Extensive ablation studies demonstrate the effectiveness of each component, and our method significantly outperforms the state-of-the-art approaches.
3D-DETNet: a Single Stage Video-Based Vehicle Detector
Jan 15, 2018Video-based vehicle detection has received considerable attention over the last ten years and there are many deep learning based detection methods which can be applied to it. However, these methods are devised for still images and applying them for video vehicle detection directly always obtains poor performance. In this work, we propose a new single-stage video-based vehicle detector integrated with 3DCovNet and focal loss, called 3D-DETNet. Draw support from 3D Convolution network and focal loss, our method has ability to capture motion information and is more suitable to detect vehicle in video than other single-stage methods devised for static images. The multiple video frames are initially fed to 3D-DETNet to generate multiple spatial feature maps, then sub-model 3DConvNet takes spatial feature maps as input to capture temporal information which is fed to final fully convolution model for predicting locations of vehicles in video frames. We evaluate our method on UA-DETAC vehicle detection dataset and our 3D-DETNet yields best performance and keeps a higher detection speed of 26 fps compared with other competing methods.