 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynergistic Development of Perovskite Memristors and Algorithms for Robust Analog Computing
Dec 03, 2024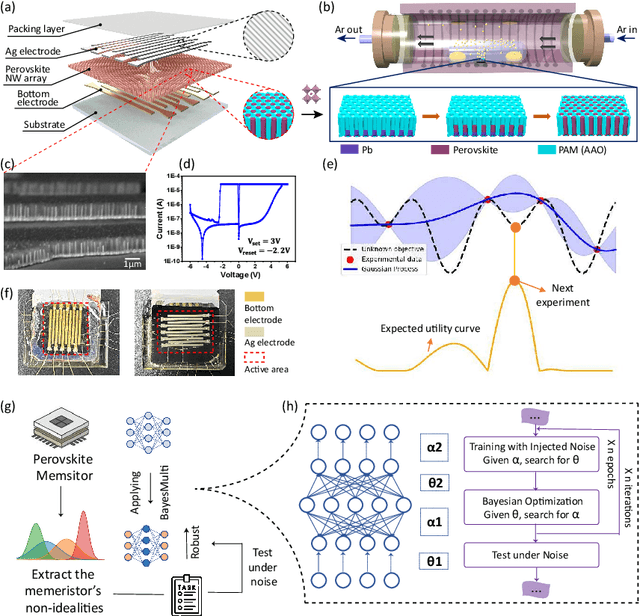

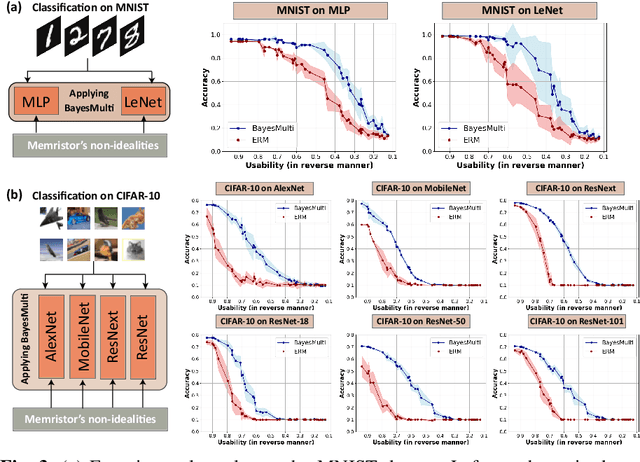
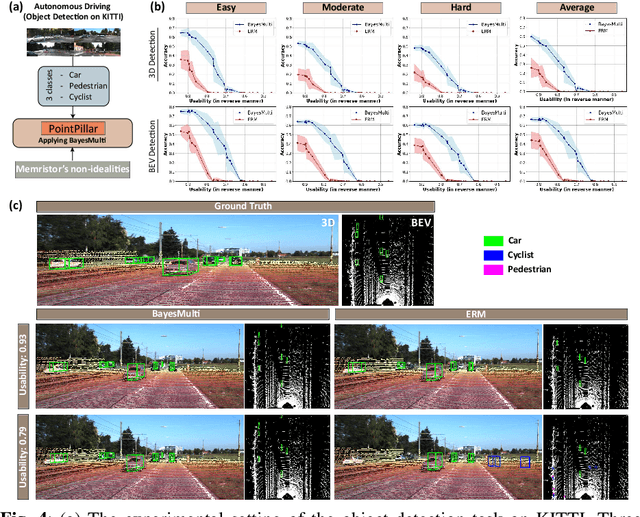
Analog computing using non-volatile memristors has emerged as a promising solution for energy-efficient deep learning. New materials, like perovskites-based memristors are recently attractive due to their cost-effectiveness, energy efficiency and flexibility. Yet, challenges in material diversity and immature fabrications require extensive experimentation for device development. Moreover, significant non-idealities in these memristors often impede them for computing. Here, we propose a synergistic methodology to concurrently optimize perovskite memristor fabrication and develop robust analog DNNs that effectively address the inherent non-idealities of these memristors. Employing Bayesian optimization (BO) with a focus on usability, we efficiently identify optimal materials and fabrication conditions for perovskite memristors. Meanwhile, we developed "BayesMulti", a DNN training strategy utilizing BO-guided noise injection to improve the resistance of analog DNNs to memristor imperfections. Our approach theoretically ensures that within a certain range of parameter perturbations due to memristor non-idealities, the prediction outcomes remain consistent. Our integrated approach enables use of analog computing in much deeper and wider networks, which significantly outperforms existing methods in diverse tasks like image classification, autonomous driving, species identification, and large vision-language models, achieving up to 100-fold improvements. We further validate our methodology on a 10$\times$10 optimized perovskite memristor crossbar, demonstrating high accuracy in a classification task and low energy consumption. This study offers a versatile solution for efficient optimization of various analog computing systems, encompassing both devices and algorithms.
MiniConGTS: A Near Ultimate Minimalist Contrastive Grid Tagging Scheme for Aspect Sentiment Triplet Extraction
Jun 17, 2024



Aspect Sentiment Triplet Extraction (ASTE) aims to co-extract the sentiment triplets in a given corpus. Existing approaches within the pretraining-finetuning paradigm tend to either meticulously craft complex tagging schemes and classification heads, or incorporate external semantic augmentation to enhance performance. In this study, we, for the first time, re-evaluate the redundancy in tagging schemes and the internal enhancement in pretrained representations. We propose a method to improve and utilize pretrained representations by integrating a minimalist tagging scheme and a novel token-level contrastive learning strategy. The proposed approach demonstrates comparable or superior performance compared to state-of-the-art techniques while featuring a more compact design and reduced computational overhead. Additionally, we are the first to formally evaluate GPT-4's performance in few-shot learning and Chain-of-Thought scenarios for this task. The results demonstrate that the pretraining-finetuning paradigm remains highly effective even in the era of large language models.
CRoFT: Robust Fine-Tuning with Concurrent Optimization for OOD Generalization and Open-Set OOD Detection
May 26, 2024



Recent vision-language pre-trained models (VL-PTMs) have shown remarkable success in open-vocabulary tasks. However, downstream use cases often involve further fine-tuning of VL-PTMs, which may distort their general knowledge and impair their ability to handle distribution shifts. In real-world scenarios, machine learning systems inevitably encounter both covariate shifts (e.g., changes in image styles) and semantic shifts (e.g., test-time unseen classes). This highlights the importance of enhancing out-of-distribution (OOD) generalization on covariate shifts and simultaneously detecting semantic-shifted unseen classes. Thus a critical but underexplored question arises: How to improve VL-PTMs' generalization ability to closed-set OOD data, while effectively detecting open-set unseen classes during fine-tuning? In this paper, we propose a novel objective function of OOD detection that also serves to improve OOD generalization. We show that minimizing the gradient magnitude of energy scores on training data leads to domain-consistent Hessians of classification loss, a strong indicator for OOD generalization revealed by theoretical analysis. Based on this finding, we have developed a unified fine-tuning framework that allows for concurrent optimization of both tasks. Extensive experiments have demonstrated the superiority of our method. The code is available at https://github.com/LinLLLL/CRoFT.
PNAS-MOT: Multi-Modal Object Tracking with Pareto Neural Architecture Search
Mar 23, 2024



Multiple object tracking is a critical task in autonomous driving. Existing works primarily focus on the heuristic design of neural networks to obtain high accuracy. As tracking accuracy improves, however, neural networks become increasingly complex, posing challenges for their practical application in real driving scenarios due to the high level of latency. In this paper, we explore the use of the neural architecture search (NAS) methods to search for efficient architectures for tracking, aiming for low real-time latency while maintaining relatively high accuracy. Another challenge for object tracking is the unreliability of a single sensor, therefore, we propose a multi-modal framework to improve the robustness. Experiments demonstrate that our algorithm can run on edge devices within lower latency constraints, thus greatly reducing the computational requirements for multi-modal object tracking while keeping lower latency.
* IEEE Robotics and Automation Letters 2024. Code is available at https://github.com/PholyPeng/PNAS-MOT
Rethinking ASTE: A Minimalist Tagging Scheme Alongside Contrastive Learning
Mar 12, 2024



Aspect Sentiment Triplet Extraction (ASTE) is a burgeoning subtask of fine-grained sentiment analysis, aiming to extract structured sentiment triplets from unstructured textual data. Existing approaches to ASTE often complicate the task with additional structures or external data. In this research, we propose a novel tagging scheme and employ a contrastive learning approach to mitigate these challenges. The proposed approach demonstrates comparable or superior performance in comparison to state-of-the-art techniques, while featuring a more compact design and reduced computational overhead. Notably, even in the era of Large Language Models (LLMs), our method exhibits superior efficacy compared to GPT 3.5 and GPT 4 in a few-shot learning scenarios. This study also provides valuable insights for the advancement of ASTE techniques within the paradigm of large language models.
AceMap: Knowledge Discovery through Academic Graph
Mar 05, 2024



The exponential growth of scientific literature requires effective management and extraction of valuable insights. While existing scientific search engines excel at delivering search results based on relational databases, they often neglect the analysis of collaborations between scientific entities and the evolution of ideas, as well as the in-depth analysis of content within scientific publications. The representation of heterogeneous graphs and the effective measurement, analysis, and mining of such graphs pose significant challenges. To address these challenges, we present AceMap, an academic system designed for knowledge discovery through academic graph. We present advanced database construction techniques to build the comprehensive AceMap database with large-scale academic publications that contain rich visual, textual, and numerical information. AceMap also employs innovative visualization, quantification, and analysis methods to explore associations and logical relationships among academic entities. AceMap introduces large-scale academic network visualization techniques centered on nebular graphs, providing a comprehensive view of academic networks from multiple perspectives. In addition, AceMap proposes a unified metric based on structural entropy to quantitatively measure the knowledge content of different academic entities. Moreover, AceMap provides advanced analysis capabilities, including tracing the evolution of academic ideas through citation relationships and concept co-occurrence, and generating concise summaries informed by this evolutionary process. In addition, AceMap uses machine reading methods to generate potential new ideas at the intersection of different fields. Exploring the integration of large language models and knowledge graphs is a promising direction for future research in idea evolution. Please visit \url{https://www.acemap.info} for further exploration.
G-NAS: Generalizable Neural Architecture Search for Single Domain Generalization Object Detection
Feb 07, 2024



In this paper, we focus on a realistic yet challenging task, Single Domain Generalization Object Detection (S-DGOD), where only one source domain's data can be used for training object detectors, but have to generalize multiple distinct target domains. In S-DGOD, both high-capacity fitting and generalization abilities are needed due to the task's complexity. Differentiable Neural Architecture Search (NAS) is known for its high capacity for complex data fitting and we propose to leverage Differentiable NAS to solve S-DGOD. However, it may confront severe over-fitting issues due to the feature imbalance phenomenon, where parameters optimized by gradient descent are biased to learn from the easy-to-learn features, which are usually non-causal and spuriously correlated to ground truth labels, such as the features of background in object detection data. Consequently, this leads to serious performance degradation, especially in generalizing to unseen target domains with huge domain gaps between the source domain and target domains. To address this issue, we propose the Generalizable loss (G-loss), which is an OoD-aware objective, preventing NAS from over-fitting by using gradient descent to optimize parameters not only on a subset of easy-to-learn features but also the remaining predictive features for generalization, and the overall framework is named G-NAS. Experimental results on the S-DGOD urban-scene datasets demonstrate that the proposed G-NAS achieves SOTA performance compared to baseline methods. Codes are available at https://github.com/wufan-cse/G-NAS.
Domain Invariant Learning for Gaussian Processes and Bayesian Exploration
Dec 18, 2023Out-of-distribution (OOD) generalization has long been a challenging problem that remains largely unsolved. Gaussian processes (GP), as popular probabilistic model classes, especially in the small data regime, presume strong OOD generalization abilities. Surprisingly, their OOD generalization abilities have been under-explored before compared with other lines of GP research. In this paper, we identify that GP is not free from the problem and propose a domain invariant learning algorithm for Gaussian processes (DIL-GP) with a min-max optimization on the likelihood. DIL-GP discovers the heterogeneity in the data and forces invariance across partitioned subsets of data. We further extend the DIL-GP to improve Bayesian optimization's adaptability on changing environments. Numerical experiments demonstrate the superiority of DIL-GP for predictions on several synthetic and real-world datasets. We further demonstrate the effectiveness of the DIL-GP Bayesian optimization method on a PID parameters tuning experiment for a quadrotor. The full version and source code are available at: https://github.com/Billzxl/DIL-GP.
BayesFT: Bayesian Optimization for Fault Tolerant Neural Network Architecture
Sep 30, 2022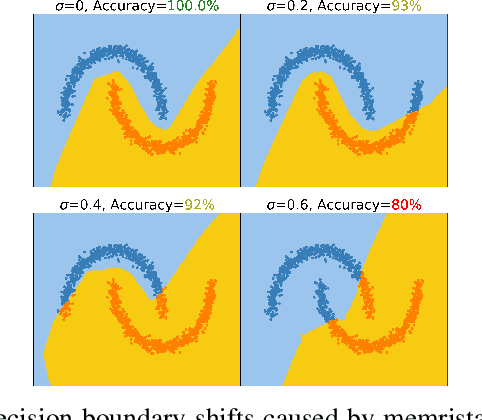
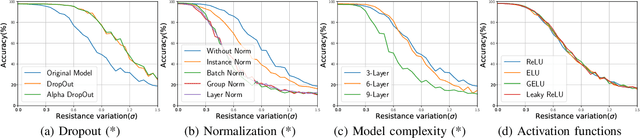
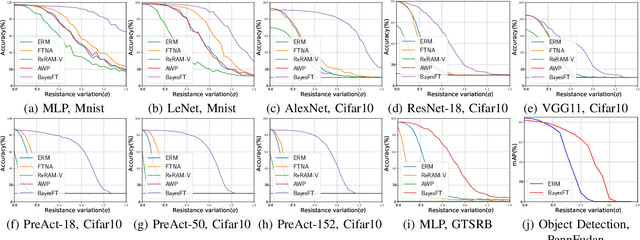

To deploy deep learning algorithms on resource-limited scenarios, an emerging device-resistive random access memory (ReRAM) has been regarded as promising via analog computing. However, the practicability of ReRAM is primarily limited due to the weight drifting of ReRAM neural networks due to multi-factor reasons, including manufacturing, thermal noises, and etc. In this paper, we propose a novel Bayesian optimization method for fault tolerant neural network architecture (BayesFT). For neural architecture search space design, instead of conducting neural architecture search on the whole feasible neural architecture search space, we first systematically explore the weight drifting tolerance of different neural network components, such as dropout, normalization, number of layers, and activation functions in which dropout is found to be able to improve the neural network robustness to weight drifting. Based on our analysis, we propose an efficient search space by only searching for dropout rates for each layer. Then, we use Bayesian optimization to search for the optimal neural architecture robust to weight drifting. Empirical experiments demonstrate that our algorithmic framework has outperformed the state-of-the-art methods by up to 10 times on various tasks, such as image classification and object detection.
Regularization Penalty Optimization for Addressing Data Quality Variance in OoD Algorithms
Jun 12, 2022
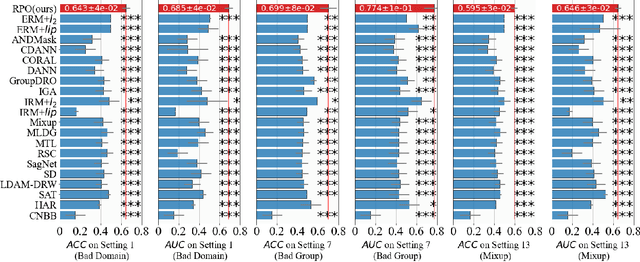

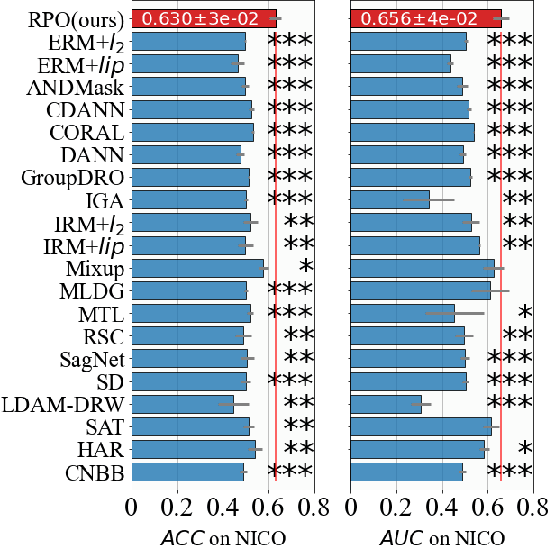
Due to the poor generalization performance of traditional empirical risk minimization (ERM) in the case of distributional shift, Out-of-Distribution (OoD) generalization algorithms receive increasing attention. However, OoD generalization algorithms overlook the great variance in the quality of training data, which significantly compromises the accuracy of these methods. In this paper, we theoretically reveal the relationship between training data quality and algorithm performance and analyze the optimal regularization scheme for Lipschitz regularized invariant risk minimization. A novel algorithm is proposed based on the theoretical results to alleviate the influence of low-quality data at both the sample level and the domain level. The experiments on both the regression and classification benchmarks validate the effectiveness of our method with statistical significance.