 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRScaffold: Boosting Dense-Scene Reasoning in Lightweight Vision Language Models
May 25, 2026Lightweight vision-language models perform competitively on standard benchmarks yet fail systematically in dense-scene reasoning, where multiple objects, attributes, and relations must be jointly grounded and resolved through multi-step inference. Such capability is critical for real-world applications where models must reliably interpret cluttered environments. Yet existing training signals provide no explicit grounding between reasoning steps and the underlying visual entities and relations, leaving lightweight models free to generate fluent but visually unanchored reasoning chains. To address this gap, we first introduce DRBench, a benchmark of 14,573 questions across 2,943 images, organized into five task categories spanning three progressive reasoning layers. Building on DRBench, we propose DRScaffold, a supervised fine-tuning framework that decomposes the supervision target into four causally ordered stages, enforcing grounded reasoning without architectural modification. Experiments on three lightweight VLMs demonstrate substantial gains on DRBench while preserving or improving performance on general-purpose benchmarks. Notably, Qwen2.5-VL-3B trained with DRScaffold surpasses the frozen Qwen2.5-VL-32B on DRBench, demonstrating that structured supervision can substitute for a significant portion of model scale in dense-scene reasoning. Our code and models are available at https://github.com/irene-shi/DRScaffold .
The First Challenge on Remote Sensing Infrared Image Super-Resolution at NTIRE 2026: Benchmark Results and Method Overview
Apr 23, 2026This paper presents the NTIRE 2026 Remote Sensing Infrared Image Super-Resolution (x4) Challenge, one of the associated challenges of NTIRE 2026. The challenge aims to recover high-resolution (HR) infrared images from low-resolution (LR) inputs generated through bicubic downsampling with a x4 scaling factor. The objective is to develop effective models or solutions that achieve state-of-the-art performance for infrared image SR in remote sensing scenarios. To reflect the characteristics of infrared data and practical application needs, the challenge adopts a single-track setting. A total of 115 participants registered for the competition, with 13 teams submitting valid entries. This report summarizes the challenge design, dataset, evaluation protocol, main results, and the representative methods of each team. The challenge serves as a benchmark to advance research in infrared image super-resolution and promote the development of effective solutions for real-world remote sensing applications.
The Fourth Challenge on Image Super-Resolution ($\times$4) at NTIRE 2026: Benchmark Results and Method Overview
Apr 16, 2026This paper presents the NTIRE 2026 image super-resolution ($\times$4) challenge, one of the associated competitions of the NTIRE 2026 Workshop at CVPR 2026. The challenge aims to reconstruct high-resolution (HR) images from low-resolution (LR) inputs generated through bicubic downsampling with a $\times$4 scaling factor. The objective is to develop effective super-resolution solutions and analyze recent advances in the field. To reflect the evolving objectives of image super-resolution, the challenge includes two tracks: (1) a restoration track, which emphasizes pixel-wise fidelity and ranks submissions based on PSNR; and (2) a perceptual track, which focuses on visual realism and evaluates results using a perceptual score. A total of 194 participants registered for the challenge, with 31 teams submitting valid entries. This report summarizes the challenge design, datasets, evaluation protocol, main results, and methods of participating teams. The challenge provides a unified benchmark and offers insights into current progress and future directions in image super-resolution.
Continuous-time Online Learning via Mean-Field Neural Networks: Regret Analysis in Diffusion Environments
Apr 13, 2026We study continuous-time online learning where data are generated by a diffusion process with unknown coefficients. The learner employs a two-layer neural network, continuously updating its parameters in a non-anticipative manner. The mean-field limit of the learning dynamics corresponds to a stochastic Wasserstein gradient flow adapted to the data filtration. We establish regret bounds for both the mean-field limit and finite-particle system. Our analysis leverages the logarithmic Sobolev inequality, Polyak-Lojasiewicz condition, Malliavin calculus, and uniform-in-time propagation of chaos. Under displacement convexity, we obtain a constant static regret bound. In the general non-convex setting, we derive explicit linear regret bounds characterizing the effects of data variation, entropic exploration, and quadratic regularization. Finally, our simulations demonstrate the outperformance of the online approach and the impact of network width and regularization parameters.
Combining scEEG and PPG for reliable sleep staging using lightweight wearables
Feb 04, 2026Reliable sleep staging remains challenging for lightweight wearable devices such as single-channel electroencephalography (scEEG) or photoplethysmography (PPG). scEEG offers direct measurement of cortical activity and serves as the foundation for sleep staging, yet exhibits limited performance on light sleep stages. PPG provides a low-cost complement that captures autonomic signatures effective for detecting light sleep. However, prior PPG-based methods rely on full night recordings (8 - 10 hours) as input context, which is less practical to provide timely feedback for sleep intervention. In this work, we investigate scEEG-PPG fusion for 4-class sleep staging under short-window (30 s - 30 min) constraints. First, we evaluate the temporal context required for each modality, to better understand the relationship of sleep staging performance with respect to monitoring window. Second, we investigate three fusion strategies: score-level fusion, cross-attention fusion enabling feature-level interactions, and Mamba-enhanced fusion incorporating temporal context modeling. Third, we train and evaluate on the Multi-Ethnic Study of Atherosclerosis (MESA) dataset and perform cross-dataset validation on the Cleveland Family Study (CFS) and the Apnea, Bariatric surgery, and CPAP (ABC) datasets. The Mamba-enhanced fusion achieves the best performance on MESA (Cohen's Kappa $κ$ = 0.798, Acc = 86.9%), with particularly notable improvement in light sleep classification (F1-score: 85.63% vs. 77.76%, recall: 82.85% vs. 69.95% for scEEG alone), and generalizes well to CFS and ABC datasets with different populations. These findings suggest that scEEG-PPG fusion is a promising approach for lightweight wearable based sleep monitoring, offering a pathway toward more accessible sleep health assessment. Source code of this project can be found at: https://github.com/DavyWJW/scEEG-PPGFusion
Entropy-Based Dimension-Free Convergence and Loss-Adaptive Schedules for Diffusion Models
Jan 29, 2026Diffusion generative models synthesize samples by discretizing reverse-time dynamics driven by a learned score (or denoiser). Existing convergence analyses of diffusion models typically scale at least linearly with the ambient dimension, and sharper rates often depend on intrinsic-dimension assumptions or other geometric restrictions on the target distribution. We develop an alternative, information-theoretic approach to dimension-free convergence that avoids any geometric assumptions. Under mild assumptions on the target distribution, we bound KL divergence between the target and generated distributions by $O(H^2/K)$ (up to endpoint factors), where $H$ is the Shannon entropy and $K$ is the number of sampling steps. Moreover, using a reformulation of the KL divergence, we propose a Loss-Adaptive Schedule (LAS) for efficient discretization of reverse SDE which is lightweight and relies only on the training loss, requiring no post-training heavy computation. Empirically, LAS improves sampling quality over common heuristic schedules.
Dog-IQA: Standard-guided Zero-shot MLLM for Mix-grained Image Quality Assessment
Oct 03, 2024



Image quality assessment (IQA) serves as the golden standard for all models' performance in nearly all computer vision fields. However, it still suffers from poor out-of-distribution generalization ability and expensive training costs. To address these problems, we propose Dog-IQA, a standard-guided zero-shot mix-grained IQA method, which is training-free and utilizes the exceptional prior knowledge of multimodal large language models (MLLMs). To obtain accurate IQA scores, namely scores consistent with humans, we design an MLLM-based inference pipeline that imitates human experts. In detail, Dog-IQA applies two techniques. First, Dog-IQA objectively scores with specific standards that utilize MLLM's behavior pattern and minimize the influence of subjective factors. Second, Dog-IQA comprehensively takes local semantic objects and the whole image as input and aggregates their scores, leveraging local and global information. Our proposed Dog-IQA achieves state-of-the-art (SOTA) performance compared with training-free methods, and competitive performance compared with training-based methods in cross-dataset scenarios. Our code and models will be available at https://github.com/Kai-Liu001/Dog-IQA.
BayesFT: Bayesian Optimization for Fault Tolerant Neural Network Architecture
Sep 30, 2022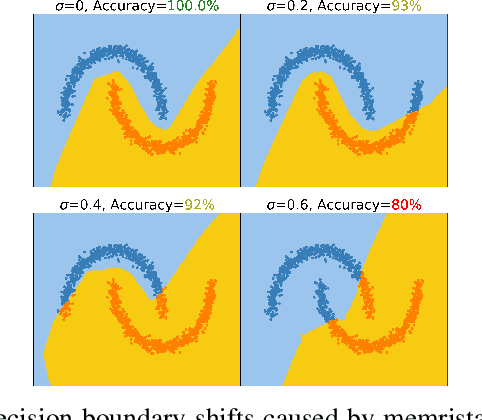
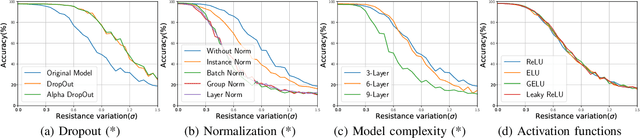
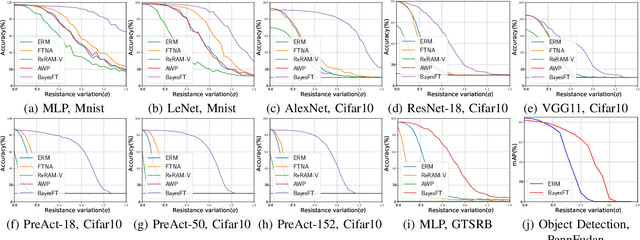

To deploy deep learning algorithms on resource-limited scenarios, an emerging device-resistive random access memory (ReRAM) has been regarded as promising via analog computing. However, the practicability of ReRAM is primarily limited due to the weight drifting of ReRAM neural networks due to multi-factor reasons, including manufacturing, thermal noises, and etc. In this paper, we propose a novel Bayesian optimization method for fault tolerant neural network architecture (BayesFT). For neural architecture search space design, instead of conducting neural architecture search on the whole feasible neural architecture search space, we first systematically explore the weight drifting tolerance of different neural network components, such as dropout, normalization, number of layers, and activation functions in which dropout is found to be able to improve the neural network robustness to weight drifting. Based on our analysis, we propose an efficient search space by only searching for dropout rates for each layer. Then, we use Bayesian optimization to search for the optimal neural architecture robust to weight drifting. Empirical experiments demonstrate that our algorithmic framework has outperformed the state-of-the-art methods by up to 10 times on various tasks, such as image classification and object detection.