 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecFlow: An Industrial Full Flow Recommendation Dataset
Oct 28, 2024



Industrial recommendation systems (RS) rely on the multi-stage pipeline to balance effectiveness and efficiency when delivering items from a vast corpus to users. Existing RS benchmark datasets primarily focus on the exposure space, where novel RS algorithms are trained and evaluated. However, when these algorithms transition to real world industrial RS, they face a critical challenge of handling unexposed items which are a significantly larger space than the exposed one. This discrepancy profoundly impacts their practical performance. Additionally, these algorithms often overlook the intricate interplay between multiple RS stages, resulting in suboptimal overall system performance. To address this issue, we introduce RecFlow, an industrial full flow recommendation dataset designed to bridge the gap between offline RS benchmarks and the real online environment. Unlike existing datasets, RecFlow includes samples not only from the exposure space but also unexposed items filtered at each stage of the RS funnel. Our dataset comprises 38M interactions from 42K users across nearly 9M items with additional 1.9B stage samples collected from 9.3M online requests over 37 days and spanning 6 stages. Leveraging the RecFlow dataset, we conduct courageous exploration experiments, showcasing its potential in designing new algorithms to enhance effectiveness by incorporating stage-specific samples. Some of these algorithms have already been deployed online, consistently yielding significant gains. We propose RecFlow as the first comprehensive benchmark dataset for the RS community, supporting research on designing algorithms at any stage, study of selection bias, debiased algorithms, multi-stage consistency and optimality, multi-task recommendation, and user behavior modeling. The RecFlow dataset, along with the corresponding source code, is available at https://github.com/RecFlow-ICLR/RecFlow.
DimeRec: A Unified Framework for Enhanced Sequential Recommendation via Generative Diffusion Models
Aug 22, 2024Sequential Recommendation (SR) plays a pivotal role in recommender systems by tailoring recommendations to user preferences based on their non-stationary historical interactions. Achieving high-quality performance in SR requires attention to both item representation and diversity. However, designing an SR method that simultaneously optimizes these merits remains a long-standing challenge. In this study, we address this issue by integrating recent generative Diffusion Models (DM) into SR. DM has demonstrated utility in representation learning and diverse image generation. Nevertheless, a straightforward combination of SR and DM leads to sub-optimal performance due to discrepancies in learning objectives (recommendation vs. noise reconstruction) and the respective learning spaces (non-stationary vs. stationary). To overcome this, we propose a novel framework called DimeRec (\textbf{Di}ffusion with \textbf{m}ulti-interest \textbf{e}nhanced \textbf{Rec}ommender). DimeRec synergistically combines a guidance extraction module (GEM) and a generative diffusion aggregation module (DAM). The GEM extracts crucial stationary guidance signals from the user's non-stationary interaction history, while the DAM employs a generative diffusion process conditioned on GEM's outputs to reconstruct and generate consistent recommendations. Our numerical experiments demonstrate that DimeRec significantly outperforms established baseline methods across three publicly available datasets. Furthermore, we have successfully deployed DimeRec on a large-scale short video recommendation platform, serving hundreds of millions of users. Live A/B testing confirms that our method improves both users' time spent and result diversification.
Full Stage Learning to Rank: A Unified Framework for Multi-Stage Systems
May 08, 2024



The Probability Ranking Principle (PRP) has been considered as the foundational standard in the design of information retrieval (IR) systems. The principle requires an IR module's returned list of results to be ranked with respect to the underlying user interests, so as to maximize the results' utility. Nevertheless, we point out that it is inappropriate to indiscriminately apply PRP through every stage of a contemporary IR system. Such systems contain multiple stages (e.g., retrieval, pre-ranking, ranking, and re-ranking stages, as examined in this paper). The \emph{selection bias} inherent in the model of each stage significantly influences the results that are ultimately presented to users. To address this issue, we propose an improved ranking principle for multi-stage systems, namely the Generalized Probability Ranking Principle (GPRP), to emphasize both the selection bias in each stage of the system pipeline as well as the underlying interest of users. We realize GPRP via a unified algorithmic framework named Full Stage Learning to Rank. Our core idea is to first estimate the selection bias in the subsequent stages and then learn a ranking model that best complies with the downstream modules' selection bias so as to deliver its top ranked results to the final ranked list in the system's output. We performed extensive experiment evaluations of our developed Full Stage Learning to Rank solution, using both simulations and online A/B tests in one of the leading short-video recommendation platforms. The algorithm is proved to be effective in both retrieval and ranking stages. Since deployed, the algorithm has brought consistent and significant performance gain to the platform.
End-to-end training of Multimodal Model and ranking Model
Apr 09, 2024



Traditional recommender systems heavily rely on ID features, which often encounter challenges related to cold-start and generalization. Modeling pre-extracted content features can mitigate these issues, but is still a suboptimal solution due to the discrepancies between training tasks and model parameters. End-to-end training presents a promising solution for these problems, yet most of the existing works mainly focus on retrieval models, leaving the multimodal techniques under-utilized. In this paper, we propose an industrial multimodal recommendation framework named EM3: End-to-end training of Multimodal Model and ranking Model, which sufficiently utilizes multimodal information and allows personalized ranking tasks to directly train the core modules in the multimodal model to obtain more task-oriented content features, without overburdening resource consumption. First, we propose Fusion-Q-Former, which consists of transformers and a set of trainable queries, to fuse different modalities and generate fixed-length and robust multimodal embeddings. Second, in our sequential modeling for user content interest, we utilize Low-Rank Adaptation technique to alleviate the conflict between huge resource consumption and long sequence length. Third, we propose a novel Content-ID-Contrastive learning task to complement the advantages of content and ID by aligning them with each other, obtaining more task-oriented content embeddings and more generalized ID embeddings. In experiments, we implement EM3 on different ranking models in two scenario, achieving significant improvements in both offline evaluation and online A/B test, verifying the generalizability of our method. Ablation studies and visualization are also performed. Furthermore, we also conduct experiments on two public datasets to show that our proposed method outperforms the state-of-the-art methods.
SHARK: A Lightweight Model Compression Approach for Large-scale Recommender Systems
Aug 18, 2023



Increasing the size of embedding layers has shown to be effective in improving the performance of recommendation models, yet gradually causing their sizes to exceed terabytes in industrial recommender systems, and hence the increase of computing and storage costs. To save resources while maintaining model performances, we propose SHARK, the model compression practice we have summarized in the recommender system of industrial scenarios. SHARK consists of two main components. First, we use the novel first-order component of Taylor expansion as importance scores to prune the number of embedding tables (feature fields). Second, we introduce a new row-wise quantization method to apply different quantization strategies to each embedding. We conduct extensive experiments on both public and industrial datasets, demonstrating that each component of our proposed SHARK framework outperforms previous approaches. We conduct A/B tests in multiple models on Kuaishou, such as short video, e-commerce, and advertising recommendation models. The results of the online A/B test showed SHARK can effectively reduce the memory footprint of the embedded layer. For the short-video scenarios, the compressed model without any performance drop significantly saves 70% storage and thousands of machines, improves 30\% queries per second (QPS), and has been deployed to serve hundreds of millions of users and process tens of billions of requests every day.
PANE-GNN: Unifying Positive and Negative Edges in Graph Neural Networks for Recommendation
Jun 08, 2023



Recommender systems play a crucial role in addressing the issue of information overload by delivering personalized recommendations to users. In recent years, there has been a growing interest in leveraging graph neural networks (GNNs) for recommender systems, capitalizing on advancements in graph representation learning. These GNN-based models primarily focus on analyzing users' positive feedback while overlooking the valuable insights provided by their negative feedback. In this paper, we propose PANE-GNN, an innovative recommendation model that unifies Positive And Negative Edges in Graph Neural Networks for recommendation. By incorporating user preferences and dispreferences, our approach enhances the capability of recommender systems to offer personalized suggestions. PANE-GNN first partitions the raw rating graph into two distinct bipartite graphs based on positive and negative feedback. Subsequently, we employ two separate embeddings, the interest embedding and the disinterest embedding, to capture users' likes and dislikes, respectively. To facilitate effective information propagation, we design distinct message-passing mechanisms for positive and negative feedback. Furthermore, we introduce a distortion to the negative graph, which exclusively consists of negative feedback edges, for contrastive training. This distortion plays a crucial role in effectively denoising the negative feedback. The experimental results provide compelling evidence that PANE-GNN surpasses the existing state-of-the-art benchmark methods across four real-world datasets. These datasets include three commonly used recommender system datasets and one open-source short video recommendation dataset.
CAN: Revisiting Feature Co-Action for Click-Through Rate Prediction
Nov 11, 2020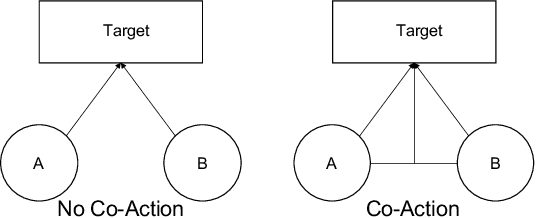
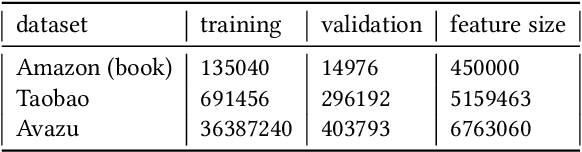
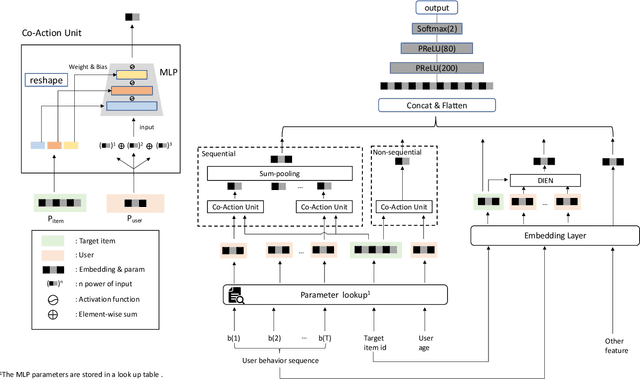
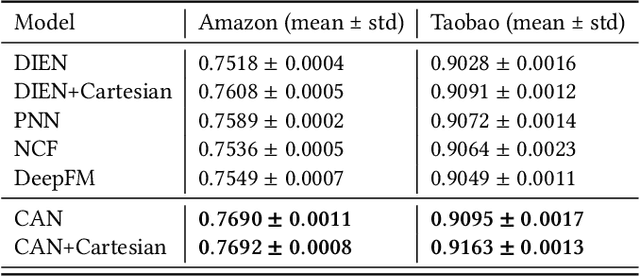
Inspired by the success of deep learning, recent industrial Click-Through Rate (CTR) prediction models have made the transition from traditional shallow approaches to deep approaches. Deep Neural Networks (DNNs) are known for its ability to learn non-linear interactions from raw feature automatically, however, the non-linear feature interaction is learned in an implicit manner. The non-linear interaction may be hard to capture and explicitly model the \textit{co-action} of raw feature is beneficial for CTR prediction. \textit{Co-action} refers to the collective effects of features toward final prediction. In this paper, we argue that current CTR models do not fully explore the potential of feature co-action. We conduct experiments and show that the effect of feature co-action is underestimated seriously. Motivated by our observation, we propose feature Co-Action Network (CAN) to explore the potential of feature co-action. The proposed model can efficiently and effectively capture the feature co-action, which improves the model performance while reduce the storage and computation consumption. Experiment results on public and industrial datasets show that CAN outperforms state-of-the-art CTR models by a large margin. Up to now, CAN has been deployed in the Alibaba display advertisement system, obtaining averaging 12\% improvement on CTR and 8\% on RPM.
Deep Interest Evolution Network for Click-Through Rate Prediction
Nov 06, 2018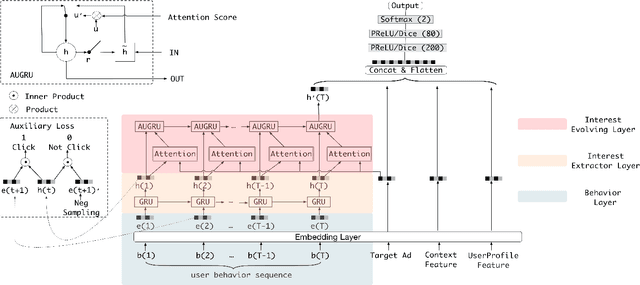

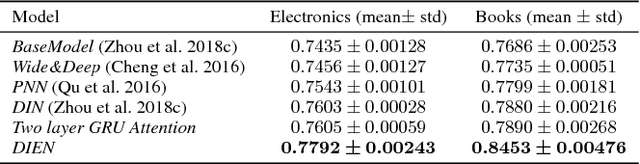
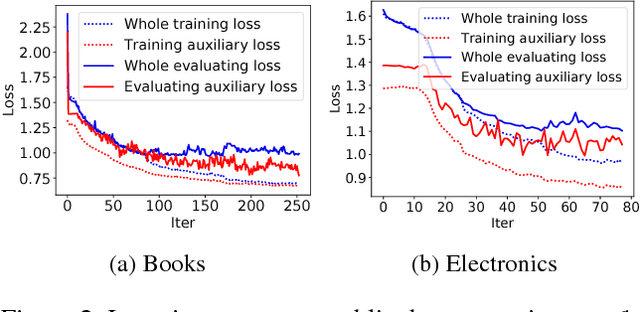
Click-through rate~(CTR) prediction, whose goal is to estimate the probability of the user clicks, has become one of the core tasks in advertising systems. For CTR prediction model, it is necessary to capture the latent user interest behind the user behavior data. Besides, considering the changing of the external environment and the internal cognition, user interest evolves over time dynamically. There are several CTR prediction methods for interest modeling, while most of them regard the representation of behavior as the interest directly, and lack specially modeling for latent interest behind the concrete behavior. Moreover, few work consider the changing trend of interest. In this paper, we propose a novel model, named Deep Interest Evolution Network~(DIEN), for CTR prediction. Specifically, we design interest extractor layer to capture temporal interests from history behavior sequence. At this layer, we introduce an auxiliary loss to supervise interest extracting at each step. As user interests are diverse, especially in the e-commerce system, we propose interest evolving layer to capture interest evolving process that is relative to the target item. At interest evolving layer, attention mechanism is embedded into the sequential structure novelly, and the effects of relative interests are strengthened during interest evolution. In the experiments on both public and industrial datasets, DIEN significantly outperforms the state-of-the-art solutions. Notably, DIEN has been deployed in the display advertisement system of Taobao, and obtained 20.7\% improvement on CTR.