 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All Candidates are Created Equal: A Heterogeneity-Aware Approach to Pre-ranking in Recommender Systems
Mar 04, 2026Most large-scale recommender systems follow a multi-stage cascade of retrieval, pre-ranking, ranking, and re-ranking. A key challenge at the pre-ranking stage arises from the heterogeneity of training instances sampled from coarse-grained retrieval results, fine-grained ranking signals, and exposure feedback. Our analysis reveals that prevailing pre-ranking methods, which indiscriminately mix heterogeneous samples, suffer from gradient conflicts: hard samples dominate training while easy ones remain underutilized, leading to suboptimal performance. We further show that the common practice of uniformly scaling model complexity across all samples is inefficient, as it overspends computation on easy cases and slows training without proportional gains. To address these limitations, this paper presents Heterogeneity-Aware Adaptive Pre-ranking (HAP), a unified framework that mitigates gradient conflicts through conflict-sensitive sampling coupled with tailored loss design, while adaptively allocating computational budgets across candidates. Specifically, HAP disentangles easy and hard samples, directing each subset along dedicated optimization paths. Building on this separation, it first applies lightweight models to all candidates for efficient coverage, and further engages stronger models on the hard ones, maintaining accuracy while reducing cost. This approach not only improves pre-ranking effectiveness but also provides a practical perspective on scaling strategies in industrial recommender systems. HAP has been deployed in the Toutiao production system for 9 months, yielding up to 0.4% improvement in user app usage duration and 0.05% in active days, without additional computational cost. We also release a large-scale industrial hybrid-sample dataset to enable the systematic study of source-driven candidate heterogeneity in pre-ranking.
CAN: Revisiting Feature Co-Action for Click-Through Rate Prediction
Nov 11, 2020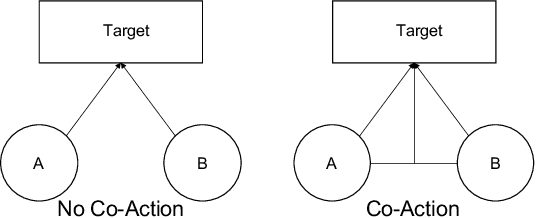
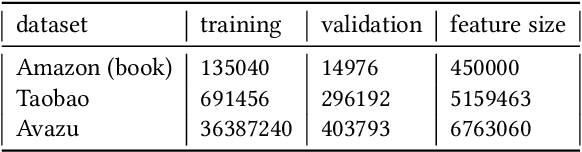
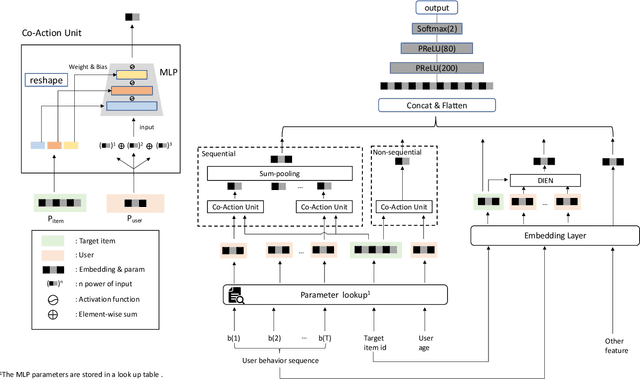
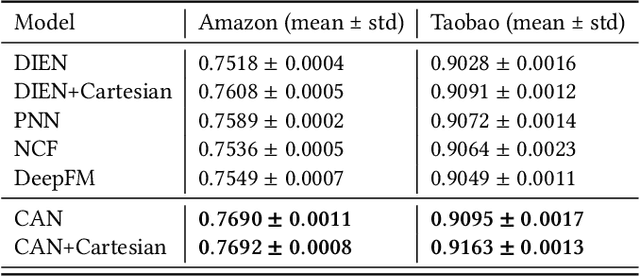
Inspired by the success of deep learning, recent industrial Click-Through Rate (CTR) prediction models have made the transition from traditional shallow approaches to deep approaches. Deep Neural Networks (DNNs) are known for its ability to learn non-linear interactions from raw feature automatically, however, the non-linear feature interaction is learned in an implicit manner. The non-linear interaction may be hard to capture and explicitly model the \textit{co-action} of raw feature is beneficial for CTR prediction. \textit{Co-action} refers to the collective effects of features toward final prediction. In this paper, we argue that current CTR models do not fully explore the potential of feature co-action. We conduct experiments and show that the effect of feature co-action is underestimated seriously. Motivated by our observation, we propose feature Co-Action Network (CAN) to explore the potential of feature co-action. The proposed model can efficiently and effectively capture the feature co-action, which improves the model performance while reduce the storage and computation consumption. Experiment results on public and industrial datasets show that CAN outperforms state-of-the-art CTR models by a large margin. Up to now, CAN has been deployed in the Alibaba display advertisement system, obtaining averaging 12\% improvement on CTR and 8\% on RPM.
Deep Interest Evolution Network for Click-Through Rate Prediction
Nov 06, 2018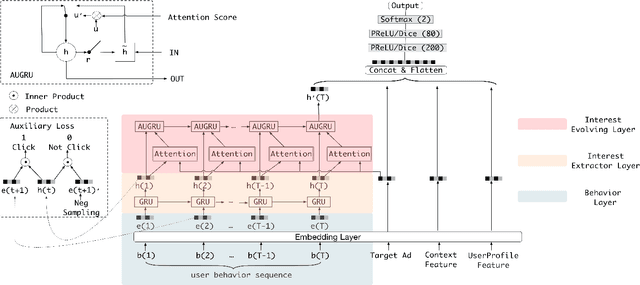

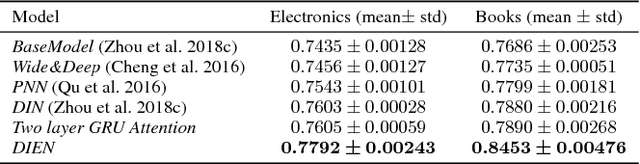
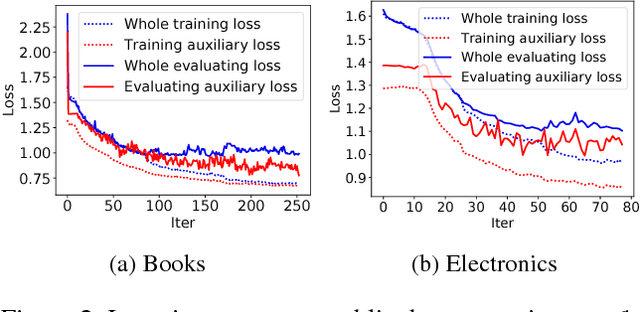
Click-through rate~(CTR) prediction, whose goal is to estimate the probability of the user clicks, has become one of the core tasks in advertising systems. For CTR prediction model, it is necessary to capture the latent user interest behind the user behavior data. Besides, considering the changing of the external environment and the internal cognition, user interest evolves over time dynamically. There are several CTR prediction methods for interest modeling, while most of them regard the representation of behavior as the interest directly, and lack specially modeling for latent interest behind the concrete behavior. Moreover, few work consider the changing trend of interest. In this paper, we propose a novel model, named Deep Interest Evolution Network~(DIEN), for CTR prediction. Specifically, we design interest extractor layer to capture temporal interests from history behavior sequence. At this layer, we introduce an auxiliary loss to supervise interest extracting at each step. As user interests are diverse, especially in the e-commerce system, we propose interest evolving layer to capture interest evolving process that is relative to the target item. At interest evolving layer, attention mechanism is embedded into the sequential structure novelly, and the effects of relative interests are strengthened during interest evolution. In the experiments on both public and industrial datasets, DIEN significantly outperforms the state-of-the-art solutions. Notably, DIEN has been deployed in the display advertisement system of Taobao, and obtained 20.7\% improvement on CTR.