 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Keyphrase Extraction by Jointly Modeling Local and Global Context
Sep 15, 2021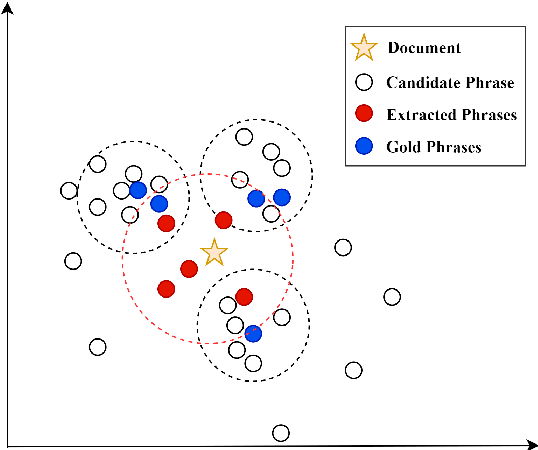
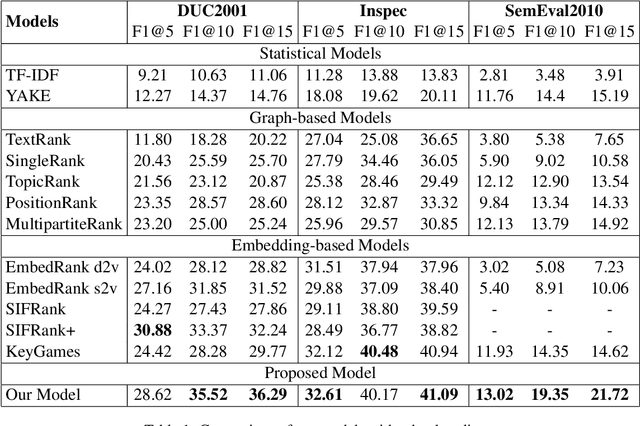
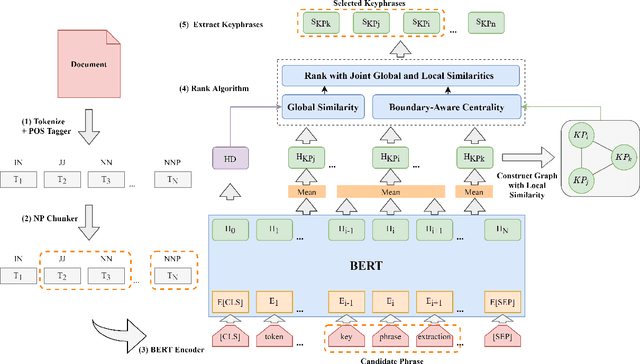

Embedding based methods are widely used for unsupervised keyphrase extraction (UKE) tasks. Generally, these methods simply calculate similarities between phrase embeddings and document embedding, which is insufficient to capture different context for a more effective UKE model. In this paper, we propose a novel method for UKE, where local and global contexts are jointly modeled. From a global view, we calculate the similarity between a certain phrase and the whole document in the vector space as transitional embedding based models do. In terms of the local view, we first build a graph structure based on the document where phrases are regarded as vertices and the edges are similarities between vertices. Then, we proposed a new centrality computation method to capture local salient information based on the graph structure. Finally, we further combine the modeling of global and local context for ranking. We evaluate our models on three public benchmarks (Inspec, DUC 2001, SemEval 2010) and compare with existing state-of-the-art models. The results show that our model outperforms most models while generalizing better on input documents with different domains and length. Additional ablation study shows that both the local and global information is crucial for unsupervised keyphrase extraction tasks.
Progressive Coordinate Transforms for Monocular 3D Object Detection
Aug 13, 2021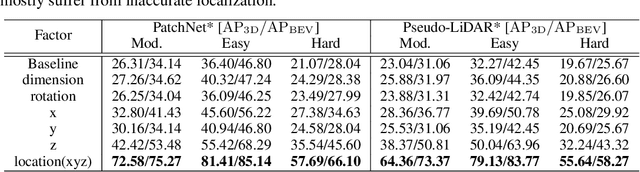

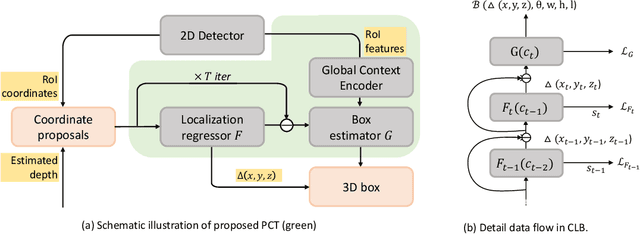
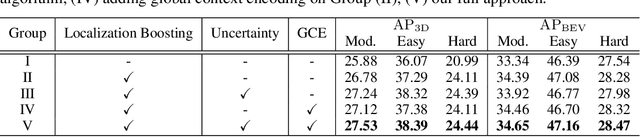
Recognizing and localizing objects in the 3D space is a crucial ability for an AI agent to perceive its surrounding environment. While significant progress has been achieved with expensive LiDAR point clouds, it poses a great challenge for 3D object detection given only a monocular image. While there exist different alternatives for tackling this problem, it is found that they are either equipped with heavy networks to fuse RGB and depth information or empirically ineffective to process millions of pseudo-LiDAR points. With in-depth examination, we realize that these limitations are rooted in inaccurate object localization. In this paper, we propose a novel and lightweight approach, dubbed {\em Progressive Coordinate Transforms} (PCT) to facilitate learning coordinate representations. Specifically, a localization boosting mechanism with confidence-aware loss is introduced to progressively refine the localization prediction. In addition, semantic image representation is also exploited to compensate for the usage of patch proposals. Despite being lightweight and simple, our strategy leads to superior improvements on the KITTI and Waymo Open Dataset monocular 3D detection benchmarks. At the same time, our proposed PCT shows great generalization to most coordinate-based 3D detection frameworks. The code is available at: https://github.com/amazon-research/progressive-coordinate-transforms .
Video Contrastive Learning with Global Context
Aug 05, 2021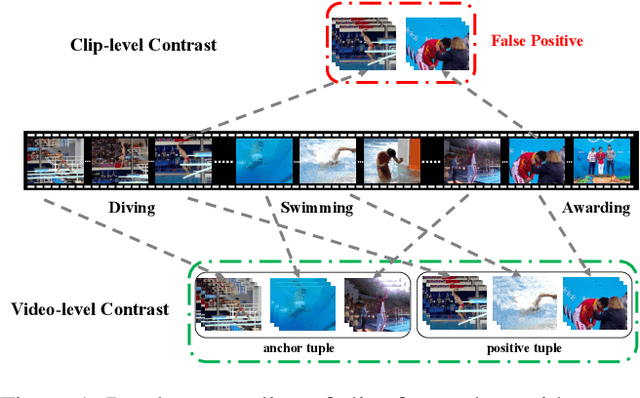

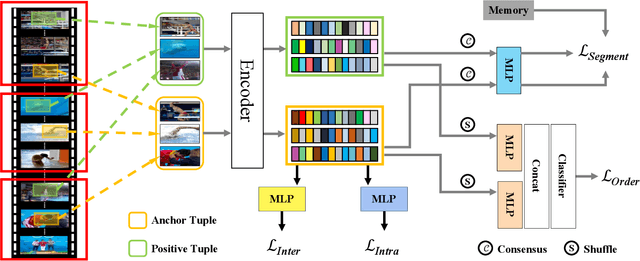
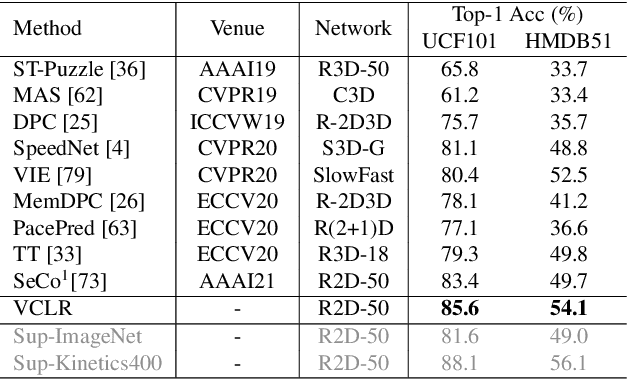
Contrastive learning has revolutionized self-supervised image representation learning field, and recently been adapted to video domain. One of the greatest advantages of contrastive learning is that it allows us to flexibly define powerful loss objectives as long as we can find a reasonable way to formulate positive and negative samples to contrast. However, existing approaches rely heavily on the short-range spatiotemporal salience to form clip-level contrastive signals, thus limit themselves from using global context. In this paper, we propose a new video-level contrastive learning method based on segments to formulate positive pairs. Our formulation is able to capture global context in a video, thus robust to temporal content change. We also incorporate a temporal order regularization term to enforce the inherent sequential structure of videos. Extensive experiments show that our video-level contrastive learning framework (VCLR) is able to outperform previous state-of-the-arts on five video datasets for downstream action classification, action localization and video retrieval. Code is available at https://github.com/amazon-research/video-contrastive-learning.
A Unified Efficient Pyramid Transformer for Semantic Segmentation
Jul 29, 2021
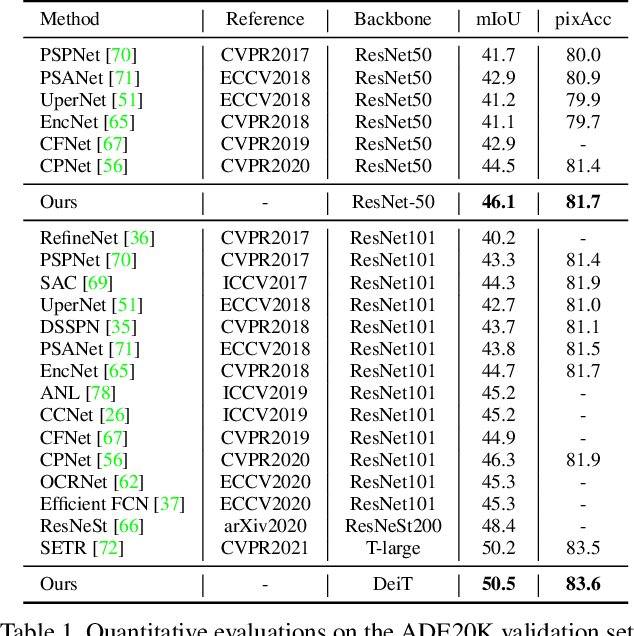
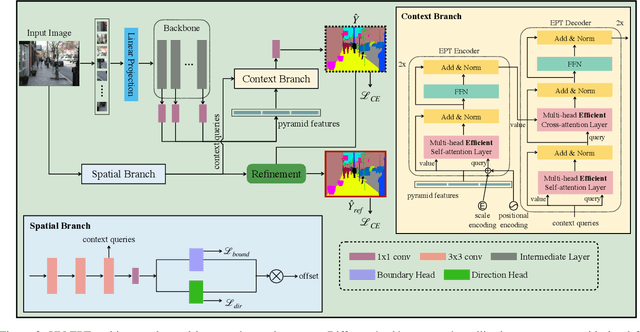
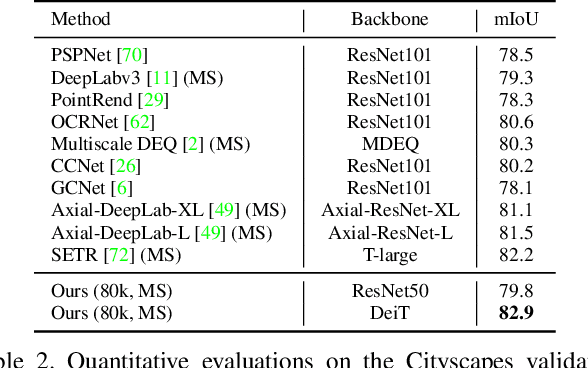
Semantic segmentation is a challenging problem due to difficulties in modeling context in complex scenes and class confusions along boundaries. Most literature either focuses on context modeling or boundary refinement, which is less generalizable in open-world scenarios. In this work, we advocate a unified framework(UN-EPT) to segment objects by considering both context information and boundary artifacts. We first adapt a sparse sampling strategy to incorporate the transformer-based attention mechanism for efficient context modeling. In addition, a separate spatial branch is introduced to capture image details for boundary refinement. The whole model can be trained in an end-to-end manner. We demonstrate promising performance on three popular benchmarks for semantic segmentation with low memory footprint. Code will be released soon.
Dive into Deep Learning
Jun 21, 2021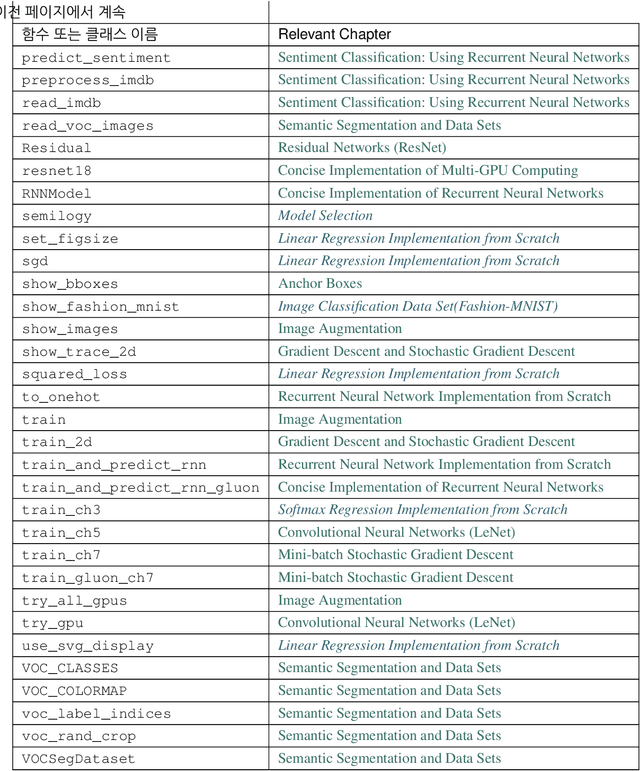
This open-source book represents our attempt to make deep learning approachable, teaching readers the concepts, the context, and the code. The entire book is drafted in Jupyter notebooks, seamlessly integrating exposition figures, math, and interactive examples with self-contained code. Our goal is to offer a resource that could (i) be freely available for everyone; (ii) offer sufficient technical depth to provide a starting point on the path to actually becoming an applied machine learning scientist; (iii) include runnable code, showing readers how to solve problems in practice; (iv) allow for rapid updates, both by us and also by the community at large; (v) be complemented by a forum for interactive discussion of technical details and to answer questions.
SelfNorm and CrossNorm for Out-of-Distribution Robustness
Feb 04, 2021
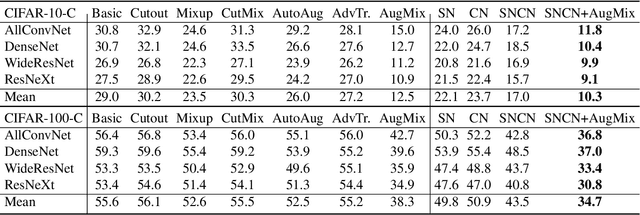
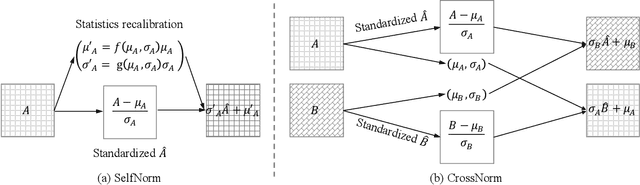
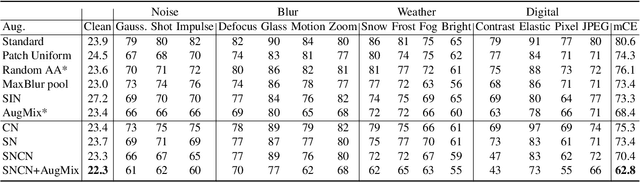
Normalization techniques are crucial in stabilizing and accelerating the training of deep neural networks. However, they are mainly designed for the independent and identically distributed (IID) data, not satisfying many real-world out-of-distribution (OOD) situations. Unlike most previous works, this paper presents two normalization methods, SelfNorm and CrossNorm, to promote OOD generalization. SelfNorm uses attention to recalibrate statistics (channel-wise mean and variance), while CrossNorm exchanges the statistics between feature maps. SelfNorm and CrossNorm can complement each other in OOD generalization, though exploring different directions in statistics usage. Extensive experiments on different domains (vision and language), tasks (classification and segmentation), and settings (supervised and semi-supervised) show their effectiveness.
A Comprehensive Study of Deep Video Action Recognition
Dec 11, 2020
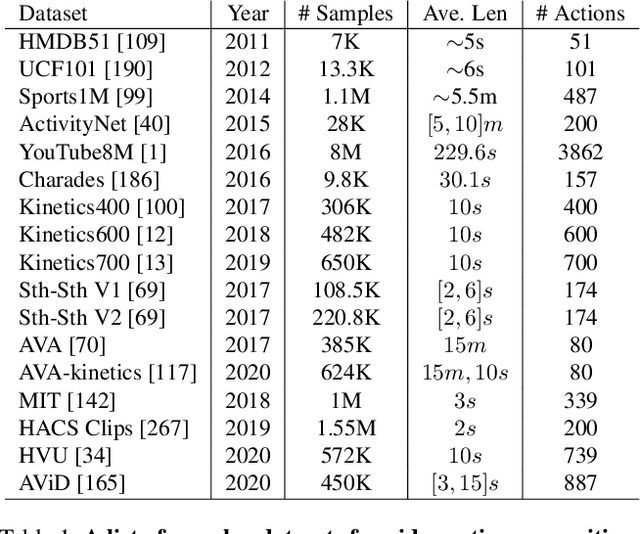
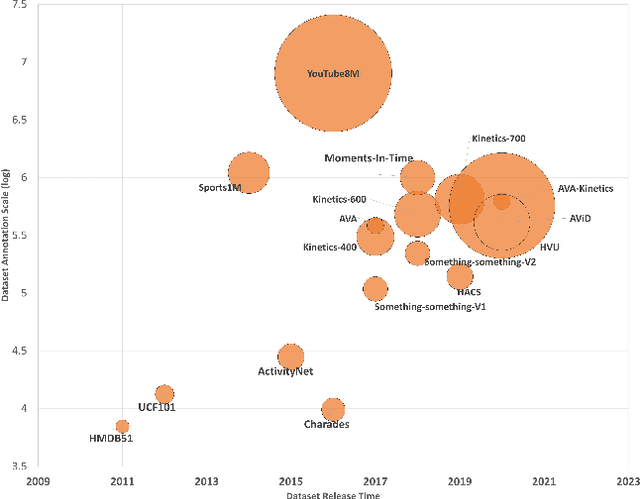
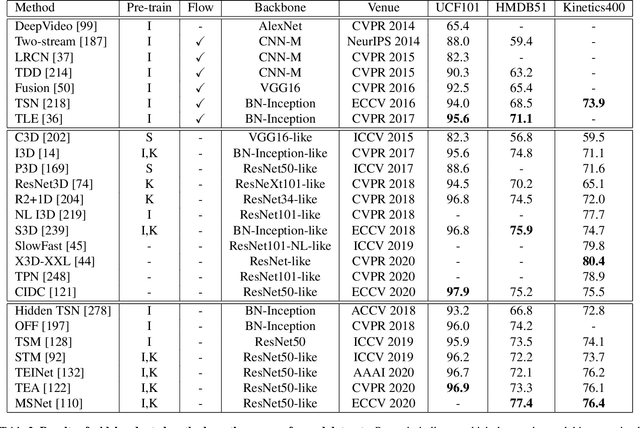
Video action recognition is one of the representative tasks for video understanding. Over the last decade, we have witnessed great advancements in video action recognition thanks to the emergence of deep learning. But we also encountered new challenges, including modeling long-range temporal information in videos, high computation costs, and incomparable results due to datasets and evaluation protocol variances. In this paper, we provide a comprehensive survey of over 200 existing papers on deep learning for video action recognition. We first introduce the 17 video action recognition datasets that influenced the design of models. Then we present video action recognition models in chronological order: starting with early attempts at adapting deep learning, then to the two-stream networks, followed by the adoption of 3D convolutional kernels, and finally to the recent compute-efficient models. In addition, we benchmark popular methods on several representative datasets and release code for reproducibility. In the end, we discuss open problems and shed light on opportunities for video action recognition to facilitate new research ideas.
FeatGraph: A Flexible and Efficient Backend for Graph Neural Network Systems
Sep 29, 2020
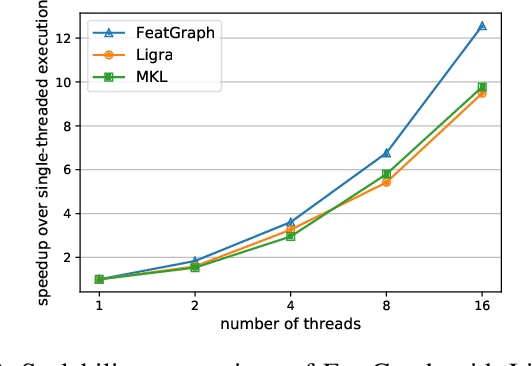
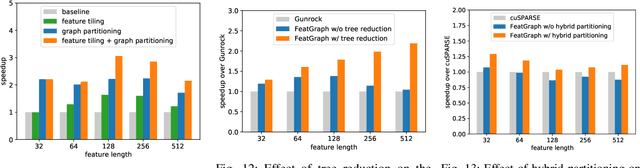
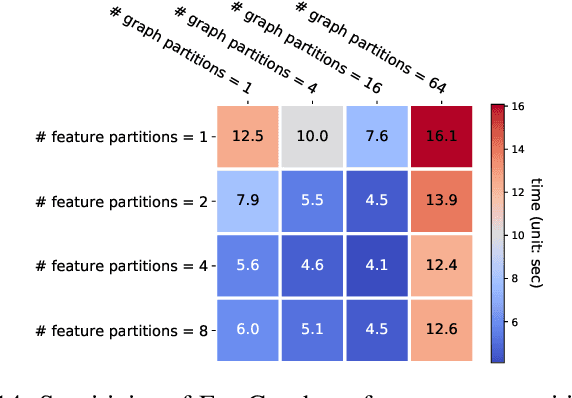
Graph neural networks (GNNs) are gaining increasing popularity as a promising approach to machine learning on graphs. Unlike traditional graph workloads where each vertex/edge is associated with a scalar, GNNs attach a feature tensor to each vertex/edge. This additional feature dimension, along with consequently more complex vertex- and edge-wise computations, has enormous implications on locality and parallelism, which existing graph processing systems fail to exploit. This paper proposes FeatGraph to accelerate GNN workloads by co-optimizing graph traversal and feature dimension computation. FeatGraph provides a flexible programming interface to express diverse GNN models by composing coarse-grained sparse templates with fine-grained user-defined functions (UDFs) on each vertex/edge. FeatGraph incorporates optimizations for graph traversal into the sparse templates and allows users to specify optimizations for UDFs with a feature dimension schedule (FDS). FeatGraph speeds up end-to-end GNN training and inference by up to 32x on CPU and 7x on GPU.
CSER: Communication-efficient SGD with Error Reset
Jul 29, 2020
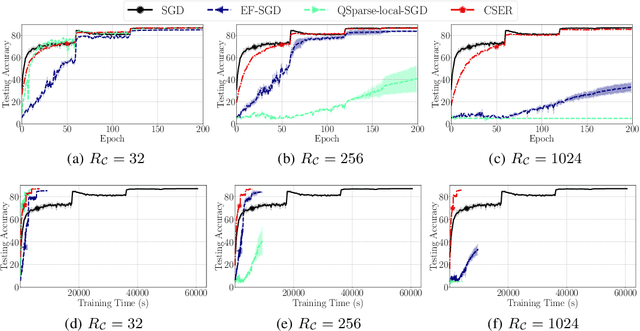

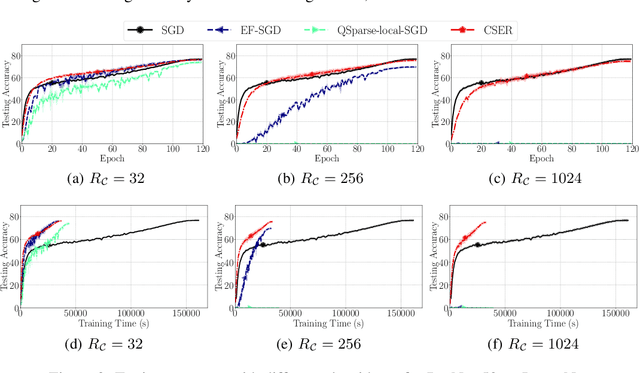
The scalability of Distributed Stochastic Gradient Descent (SGD) is today limited by communication bottlenecks. We propose a novel SGD variant: Communication-efficient SGD with Error Reset, or CSER. The key idea in CSER is first a new technique called "error reset" that adapts arbitrary compressors for SGD, producing bifurcated local models with periodic reset of resulting local residual errors. Second we introduce partial synchronization for both the gradients and the models, leveraging advantages from them. We prove the convergence of CSER for smooth non-convex problems. Empirical results show that when combined with highly aggressive compressors, the CSER algorithms: i) cause no loss of accuracy, and ii) accelerate the training by nearly $10\times$ for CIFAR-100, and by $4.5\times$ for ImageNet.
Accelerated Large Batch Optimization of BERT Pretraining in 54 minutes
Jun 24, 2020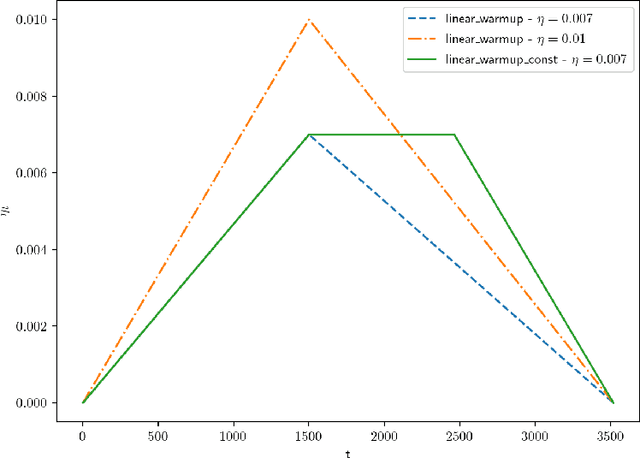


BERT has recently attracted a lot of attention in natural language understanding (NLU) and achieved state-of-the-art results in various NLU tasks. However, its success requires large deep neural networks and huge amount of data, which result in long training time and impede development progress. Using stochastic gradient methods with large mini-batch has been advocated as an efficient tool to reduce the training time. Along this line of research, LAMB is a prominent example that reduces the training time of BERT from 3 days to 76 minutes on a TPUv3 Pod. In this paper, we propose an accelerated gradient method called LANS to improve the efficiency of using large mini-batches for training. As the learning rate is theoretically upper bounded by the inverse of the Lipschitz constant of the function, one cannot always reduce the number of optimization iterations by selecting a larger learning rate. In order to use larger mini-batch size without accuracy loss, we develop a new learning rate scheduler that overcomes the difficulty of using large learning rate. Using the proposed LANS method and the learning rate scheme, we scaled up the mini-batch sizes to 96K and 33K in phases 1 and 2 of BERT pretraining, respectively. It takes 54 minutes on 192 AWS EC2 P3dn.24xlarge instances to achieve a target F1 score of 90.5 or higher on SQuAD v1.1, achieving the fastest BERT training time in the cloud.