 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantile QT-Opt for Risk-Aware Vision-Based Robotic Grasping
Oct 01, 2019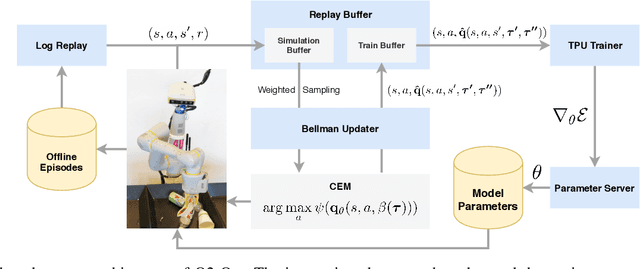
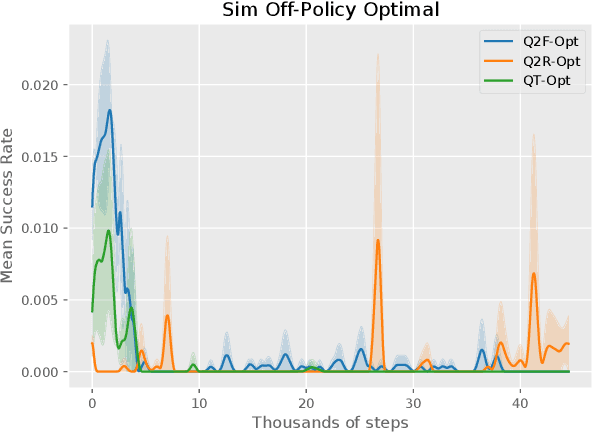
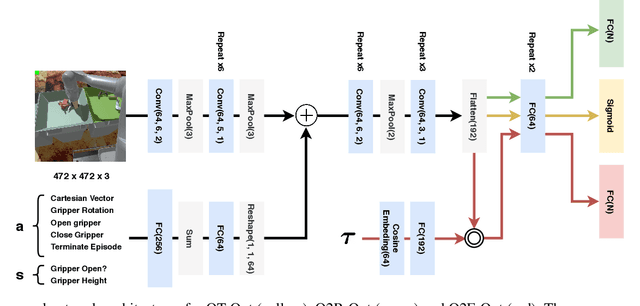
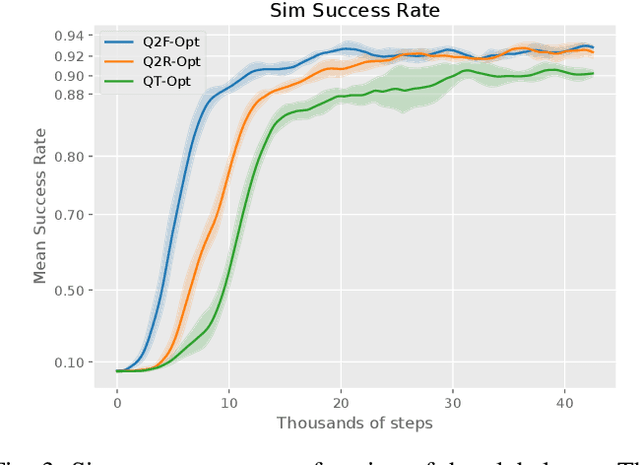
The distributional perspective on reinforcement learning (RL) has given rise to a series of successful Q-learning algorithms, resulting in state-of-the-art performance in arcade game environments. However, it has not yet been analyzed how these findings from a discrete setting translate to complex practical applications characterized by noisy, high dimensional and continuous state-action spaces. In this work, we propose Quantile QT-Opt (Q2-Opt), a distributional variant of the recently introduced distributed Q-learning algorithm for continuous domains, and examine its behaviour in a series of simulated and real vision-based robotic grasping tasks. The absence of an actor in Q2-Opt allows us to directly draw a parallel to the previous discrete experiments in the literature without the additional complexities induced by an actor-critic architecture. We demonstrate that Q2-Opt achieves a superior vision-based object grasping success rate, while also being more sample efficient. The distributional formulation also allows us to experiment with various risk-distortion metrics that give us an indication of how robots can concretely manage risk in practice using a Deep RL control policy. As an additional contribution, we perform experiments on offline datasets and compare them with the latest findings from discrete settings. Surprisingly, we find that there is a discrepancy between our results and the previous batch RL findings from the literature obtained on arcade game environments.
Watch, Try, Learn: Meta-Learning from Demonstrations and Reward
Jun 07, 2019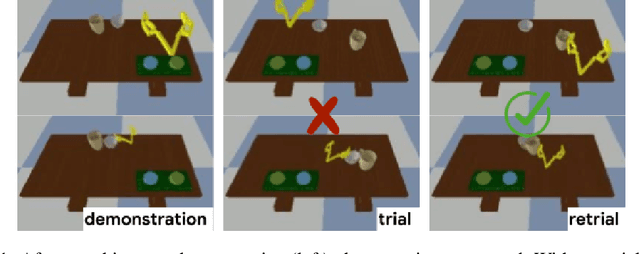
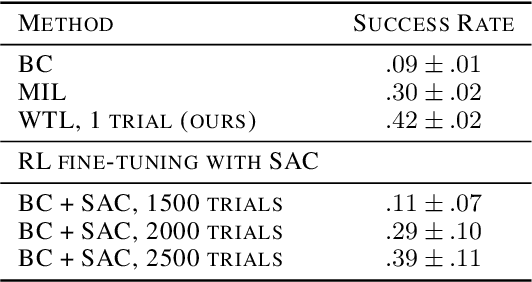
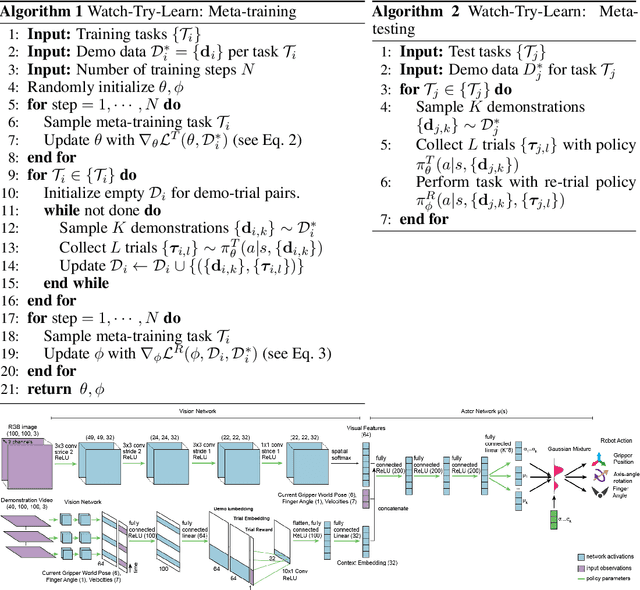
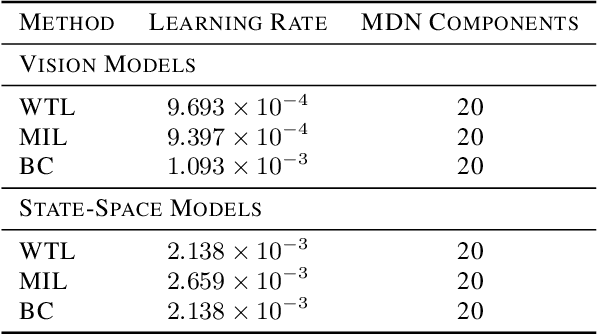
Imitation learning allows agents to learn complex behaviors from demonstrations. However, learning a complex vision-based task may require an impractical number of demonstrations. Meta-imitation learning is a promising approach towards enabling agents to learn a new task from one or a few demonstrations by leveraging experience from learning similar tasks. In the presence of task ambiguity or unobserved dynamics, demonstrations alone may not provide enough information; an agent must also try the task to successfully infer a policy. In this work, we propose a method that can learn to learn from both demonstrations and trial-and-error experience with sparse reward feedback. In comparison to meta-imitation, this approach enables the agent to effectively and efficiently improve itself autonomously beyond the demonstration data. In comparison to meta-reinforcement learning, we can scale to substantially broader distributions of tasks, as the demonstration reduces the burden of exploration. Our experiments show that our method significantly outperforms prior approaches on a set of challenging, vision-based control tasks.
Learning Probabilistic Multi-Modal Actor Models for Vision-Based Robotic Grasping
Apr 15, 2019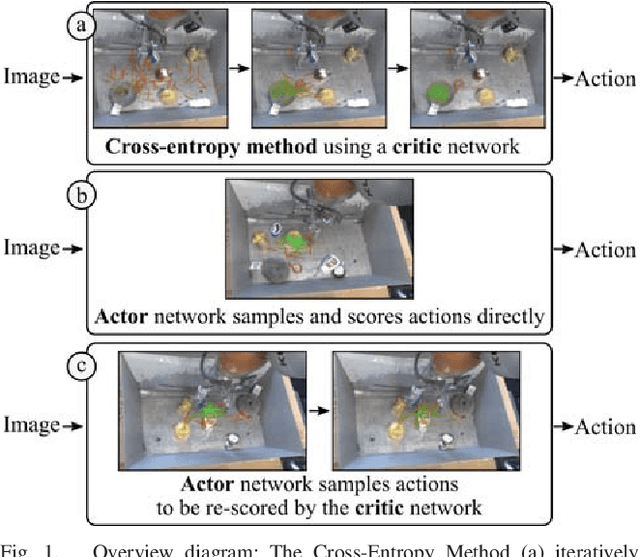
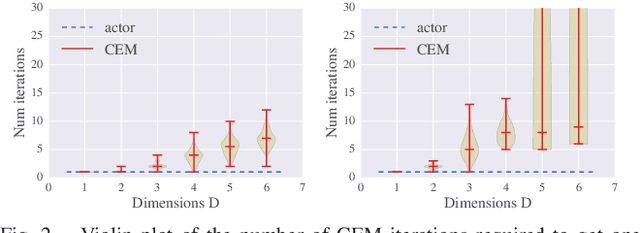
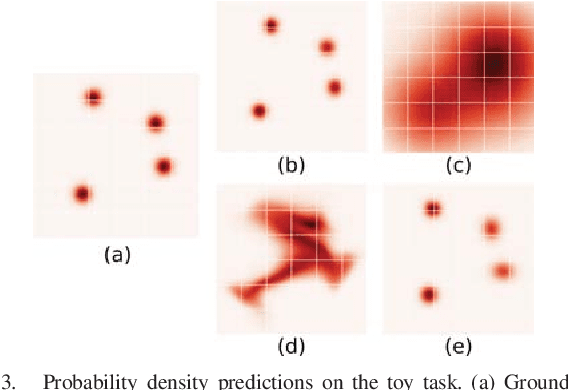

Many previous works approach vision-based robotic grasping by training a value network that evaluates grasp proposals. These approaches require an optimization process at run-time to infer the best action from the value network. As a result, the inference time grows exponentially as the dimension of action space increases. We propose an alternative method, by directly training a neural density model to approximate the conditional distribution of successful grasp poses from the input images. We construct a neural network that combines Gaussian mixture and normalizing flows, which is able to represent multi-modal, complex probability distributions. We demonstrate on both simulation and real robot that the proposed actor model achieves similar performance compared to the value network using the Cross-Entropy Method (CEM) for inference, on top-down grasping with a 4 dimensional action space. Our actor model reduces the inference time by 3 times compared to the state-of-the-art CEM method. We believe that actor models will play an important role when scaling up these approaches to higher dimensional action spaces.
Sim-to-Real via Sim-to-Sim: Data-efficient Robotic Grasping via Randomized-to-Canonical Adaptation Networks
Mar 25, 2019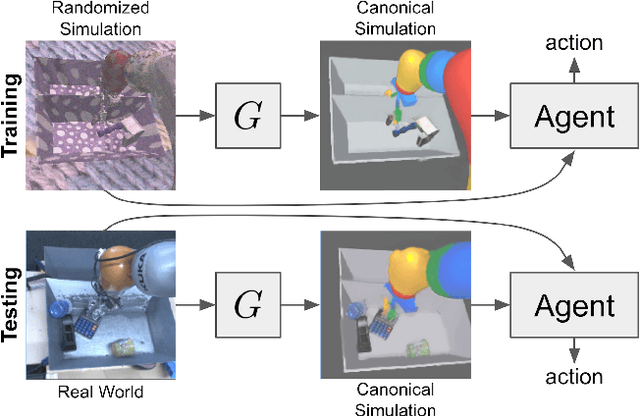
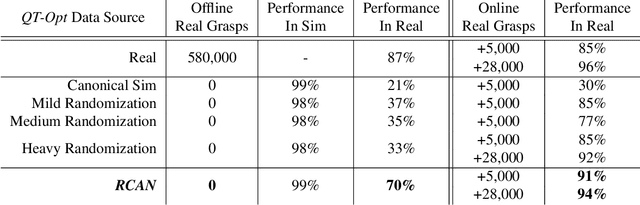


Real world data, especially in the domain of robotics, is notoriously costly to collect. One way to circumvent this can be to leverage the power of simulation to produce large amounts of labelled data. However, training models on simulated images does not readily transfer to real-world ones. Using domain adaptation methods to cross this "reality gap" requires a large amount of unlabelled real-world data, whilst domain randomization alone can waste modeling power. In this paper, we present Randomized-to-Canonical Adaptation Networks (RCANs), a novel approach to crossing the visual reality gap that uses no real-world data. Our method learns to translate randomized rendered images into their equivalent non-randomized, canonical versions. This in turn allows for real images to also be translated into canonical sim images. We demonstrate the effectiveness of this sim-to-real approach by training a vision-based closed-loop grasping reinforcement learning agent in simulation, and then transferring it to the real world to attain 70% zero-shot grasp success on unseen objects, a result that almost doubles the success of learning the same task directly on domain randomization alone. Additionally, by joint finetuning in the real-world with only 5,000 real-world grasps, our method achieves 91%, attaining comparable performance to a state-of-the-art system trained with 580,000 real-world grasps, resulting in a reduction of real-world data by more than 99%.
QT-Opt: Scalable Deep Reinforcement Learning for Vision-Based Robotic Manipulation
Nov 28, 2018


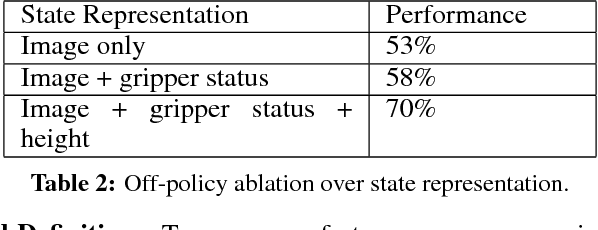
In this paper, we study the problem of learning vision-based dynamic manipulation skills using a scalable reinforcement learning approach. We study this problem in the context of grasping, a longstanding challenge in robotic manipulation. In contrast to static learning behaviors that choose a grasp point and then execute the desired grasp, our method enables closed-loop vision-based control, whereby the robot continuously updates its grasp strategy based on the most recent observations to optimize long-horizon grasp success. To that end, we introduce QT-Opt, a scalable self-supervised vision-based reinforcement learning framework that can leverage over 580k real-world grasp attempts to train a deep neural network Q-function with over 1.2M parameters to perform closed-loop, real-world grasping that generalizes to 96% grasp success on unseen objects. Aside from attaining a very high success rate, our method exhibits behaviors that are quite distinct from more standard grasping systems: using only RGB vision-based perception from an over-the-shoulder camera, our method automatically learns regrasping strategies, probes objects to find the most effective grasps, learns to reposition objects and perform other non-prehensile pre-grasp manipulations, and responds dynamically to disturbances and perturbations.
Path Integral Guided Policy Search
Oct 11, 2018
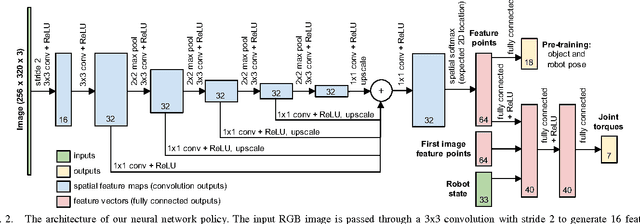

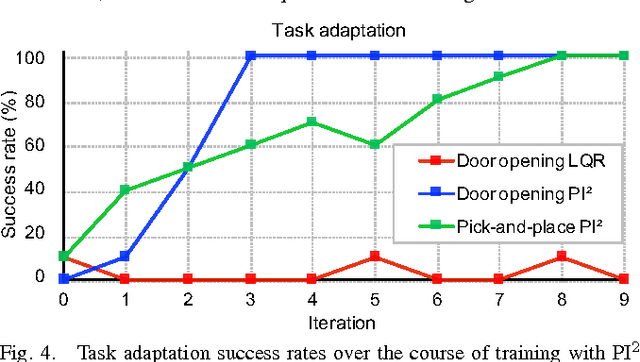
We present a policy search method for learning complex feedback control policies that map from high-dimensional sensory inputs to motor torques, for manipulation tasks with discontinuous contact dynamics. We build on a prior technique called guided policy search (GPS), which iteratively optimizes a set of local policies for specific instances of a task, and uses these to train a complex, high-dimensional global policy that generalizes across task instances. We extend GPS in the following ways: (1) we propose the use of a model-free local optimizer based on path integral stochastic optimal control (PI2), which enables us to learn local policies for tasks with highly discontinuous contact dynamics; and (2) we enable GPS to train on a new set of task instances in every iteration by using on-policy sampling: this increases the diversity of the instances that the policy is trained on, and is crucial for achieving good generalization. We show that these contributions enable us to learn deep neural network policies that can directly perform torque control from visual input. We validate the method on a challenging door opening task and a pick-and-place task, and we demonstrate that our approach substantially outperforms the prior LQR-based local policy optimizer on these tasks. Furthermore, we show that on-policy sampling significantly increases the generalization ability of these policies.
Multi-Task Domain Adaptation for Deep Learning of Instance Grasping from Simulation
Mar 04, 2018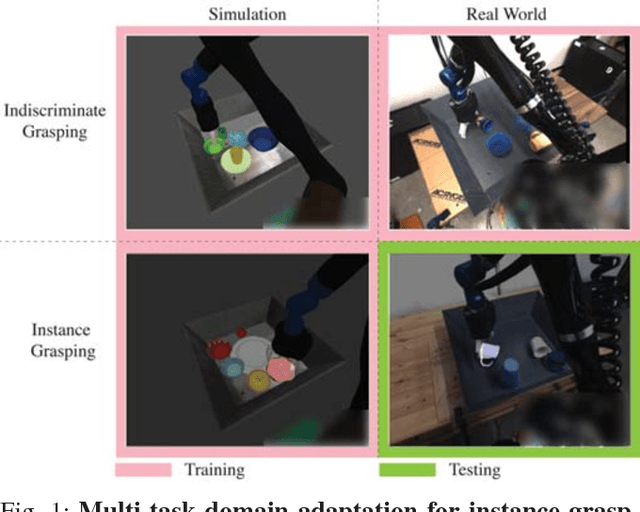

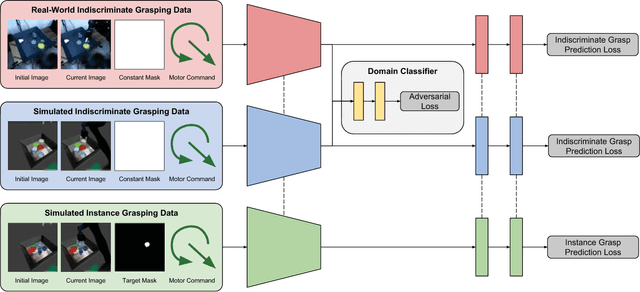
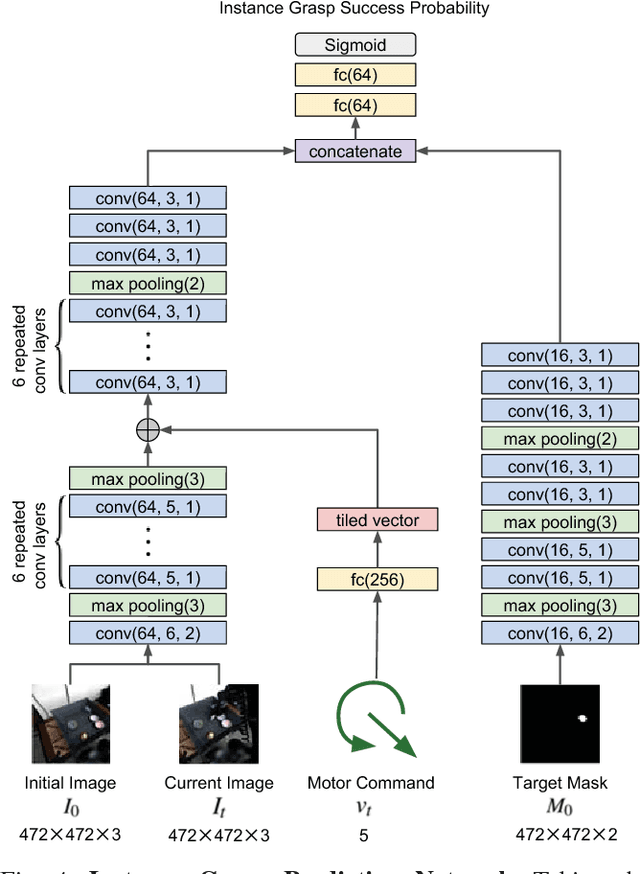
Learning-based approaches to robotic manipulation are limited by the scalability of data collection and accessibility of labels. In this paper, we present a multi-task domain adaptation framework for instance grasping in cluttered scenes by utilizing simulated robot experiments. Our neural network takes monocular RGB images and the instance segmentation mask of a specified target object as inputs, and predicts the probability of successfully grasping the specified object for each candidate motor command. The proposed transfer learning framework trains a model for instance grasping in simulation and uses a domain-adversarial loss to transfer the trained model to real robots using indiscriminate grasping data, which is available both in simulation and the real world. We evaluate our model in real-world robot experiments, comparing it with alternative model architectures as well as an indiscriminate grasping baseline.
Using Simulation and Domain Adaptation to Improve Efficiency of Deep Robotic Grasping
Sep 25, 2017


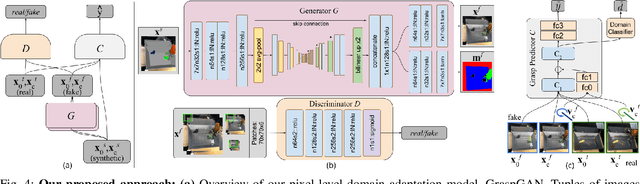
Instrumenting and collecting annotated visual grasping datasets to train modern machine learning algorithms can be extremely time-consuming and expensive. An appealing alternative is to use off-the-shelf simulators to render synthetic data for which ground-truth annotations are generated automatically. Unfortunately, models trained purely on simulated data often fail to generalize to the real world. We study how randomized simulated environments and domain adaptation methods can be extended to train a grasping system to grasp novel objects from raw monocular RGB images. We extensively evaluate our approaches with a total of more than 25,000 physical test grasps, studying a range of simulation conditions and domain adaptation methods, including a novel extension of pixel-level domain adaptation that we term the GraspGAN. We show that, by using synthetic data and domain adaptation, we are able to reduce the number of real-world samples needed to achieve a given level of performance by up to 50 times, using only randomly generated simulated objects. We also show that by using only unlabeled real-world data and our GraspGAN methodology, we obtain real-world grasping performance without any real-world labels that is similar to that achieved with 939,777 labeled real-world samples.
Collective Robot Reinforcement Learning with Distributed Asynchronous Guided Policy Search
Oct 03, 2016
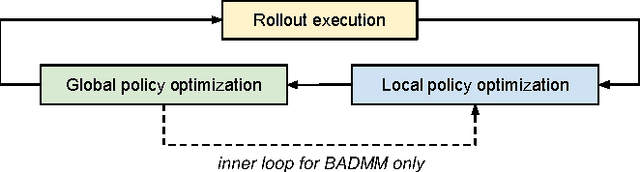
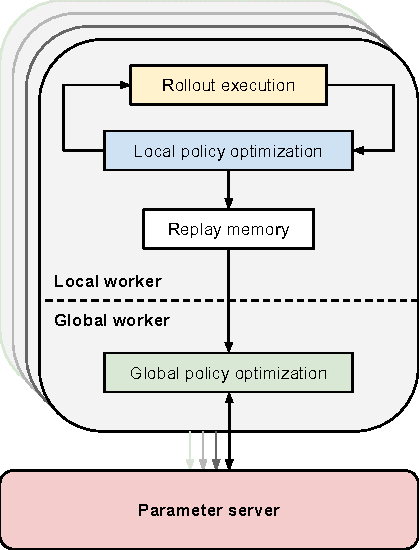
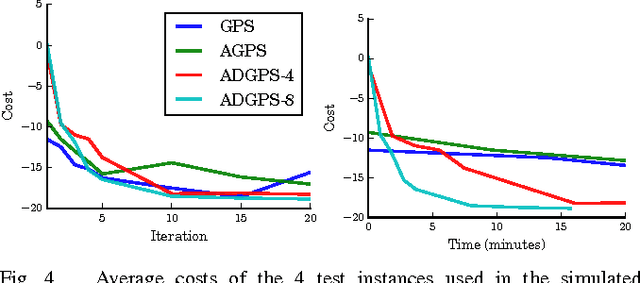
In principle, reinforcement learning and policy search methods can enable robots to learn highly complex and general skills that may allow them to function amid the complexity and diversity of the real world. However, training a policy that generalizes well across a wide range of real-world conditions requires far greater quantity and diversity of experience than is practical to collect with a single robot. Fortunately, it is possible for multiple robots to share their experience with one another, and thereby, learn a policy collectively. In this work, we explore distributed and asynchronous policy learning as a means to achieve generalization and improved training times on challenging, real-world manipulation tasks. We propose a distributed and asynchronous version of Guided Policy Search and use it to demonstrate collective policy learning on a vision-based door opening task using four robots. We show that it achieves better generalization, utilization, and training times than the single robot alternative.
Probabilistic Object Tracking using a Range Camera
May 01, 2015
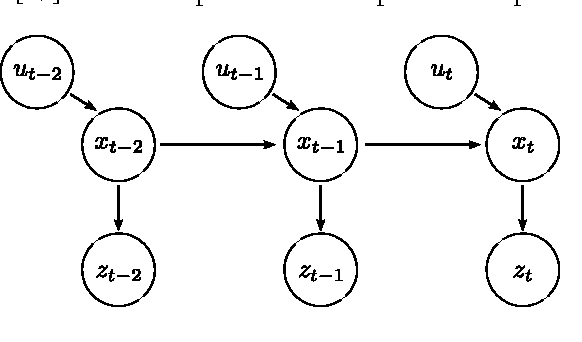
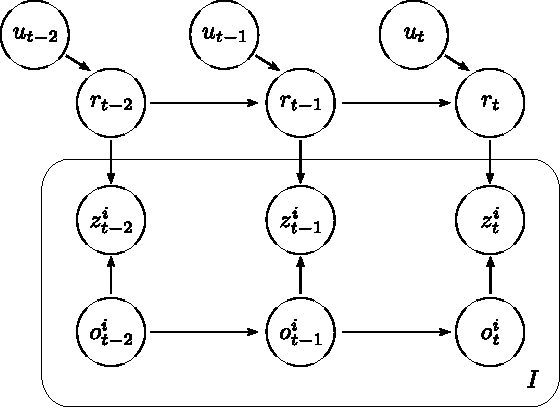
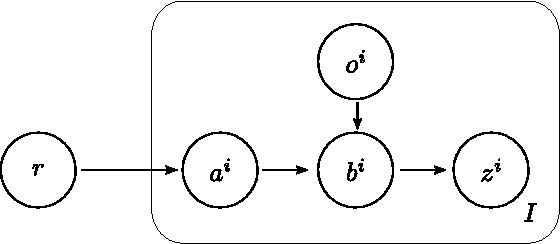
We address the problem of tracking the 6-DoF pose of an object while it is being manipulated by a human or a robot. We use a dynamic Bayesian network to perform inference and compute a posterior distribution over the current object pose. Depending on whether a robot or a human manipulates the object, we employ a process model with or without knowledge of control inputs. Observations are obtained from a range camera. As opposed to previous object tracking methods, we explicitly model self-occlusions and occlusions from the environment, e.g, the human or robotic hand. This leads to a strongly non-linear observation model and additional dependencies in the Bayesian network. We employ a Rao-Blackwellised particle filter to compute an estimate of the object pose at every time step. In a set of experiments, we demonstrate the ability of our method to accurately and robustly track the object pose in real-time while it is being manipulated by a human or a robot.