 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction Image Representation: Learning Scalable Deep Grasping Policies with Zero Real World Data
May 13, 2020

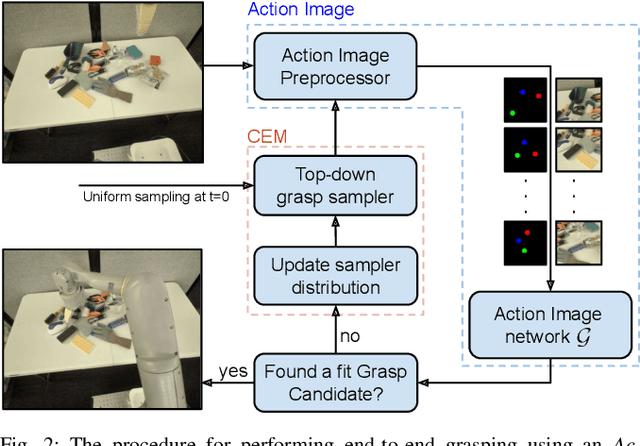
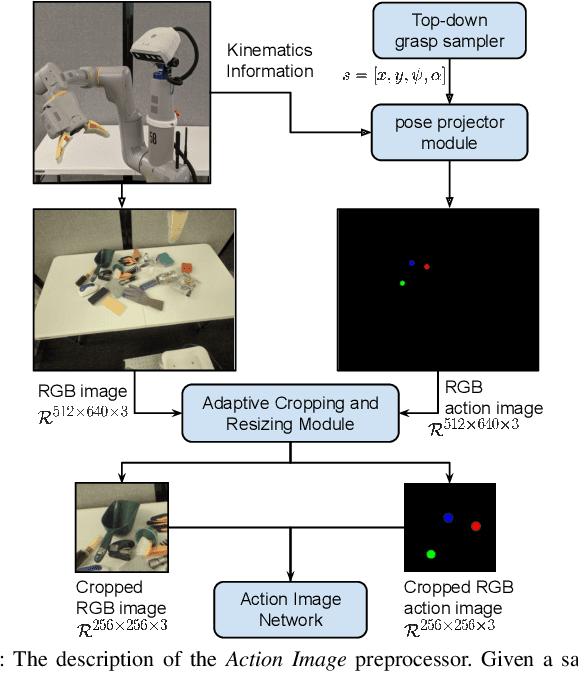
This paper introduces Action Image, a new grasp proposal representation that allows learning an end-to-end deep-grasping policy. Our model achieves $84\%$ grasp success on $172$ real world objects while being trained only in simulation on $48$ objects with just naive domain randomization. Similar to computer vision problems, such as object detection, Action Image builds on the idea that object features are invariant to translation in image space. Therefore, grasp quality is invariant when evaluating the object-gripper relationship; a successful grasp for an object depends on its local context, but is independent of the surrounding environment. Action Image represents a grasp proposal as an image and uses a deep convolutional network to infer grasp quality. We show that by using an Action Image representation, trained networks are able to extract local, salient features of grasping tasks that generalize across different objects and environments. We show that this representation works on a variety of inputs, including color images (RGB), depth images (D), and combined color-depth (RGB-D). Our experimental results demonstrate that networks utilizing an Action Image representation exhibit strong domain transfer between training on simulated data and inference on real-world sensor streams. Finally, our experiments show that a network trained with Action Image improves grasp success ($84\%$ vs. $53\%$) over a baseline model with the same structure, but using actions encoded as vectors.
Scalable Multi-Task Imitation Learning with Autonomous Improvement
Feb 25, 2020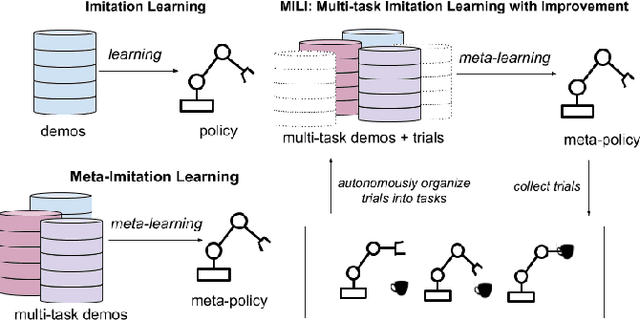
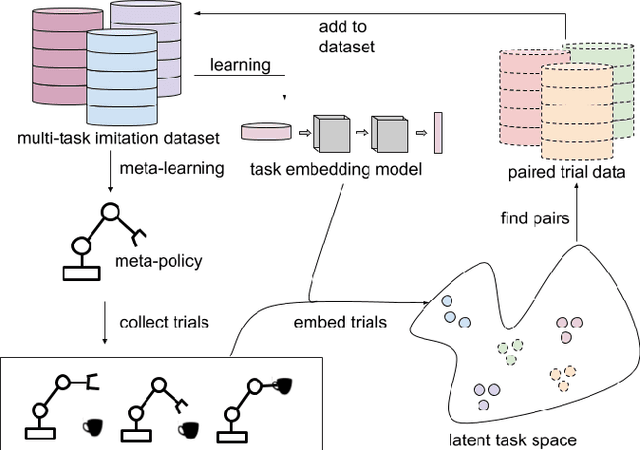
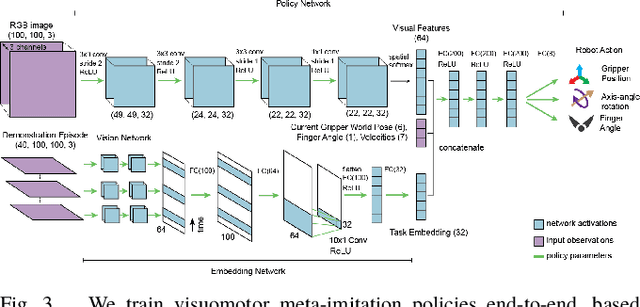

While robot learning has demonstrated promising results for enabling robots to automatically acquire new skills, a critical challenge in deploying learning-based systems is scale: acquiring enough data for the robot to effectively generalize broadly. Imitation learning, in particular, has remained a stable and powerful approach for robot learning, but critically relies on expert operators for data collection. In this work, we target this challenge, aiming to build an imitation learning system that can continuously improve through autonomous data collection, while simultaneously avoiding the explicit use of reinforcement learning, to maintain the stability, simplicity, and scalability of supervised imitation. To accomplish this, we cast the problem of imitation with autonomous improvement into a multi-task setting. We utilize the insight that, in a multi-task setting, a failed attempt at one task might represent a successful attempt at another task. This allows us to leverage the robot's own trials as demonstrations for tasks other than the one that the robot actually attempted. Using an initial dataset of multi-task demonstration data, the robot autonomously collects trials which are only sparsely labeled with a binary indication of whether the trial accomplished any useful task or not. We then embed the trials into a learned latent space of tasks, trained using only the initial demonstration dataset, to draw similarities between various trials, enabling the robot to achieve one-shot generalization to new tasks. In contrast to prior imitation learning approaches, our method can autonomously collect data with sparse supervision for continuous improvement, and in contrast to reinforcement learning algorithms, our method can effectively improve from sparse, task-agnostic reward signals.
Data-Efficient Learning for Sim-to-Real Robotic Grasping using Deep Point Cloud Prediction Networks
Jun 21, 2019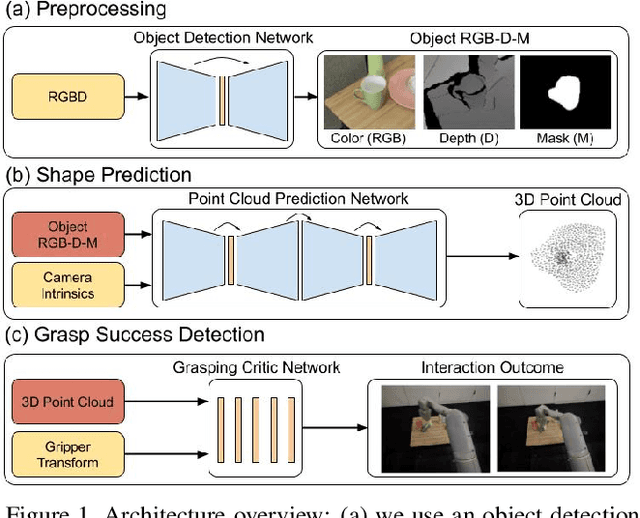
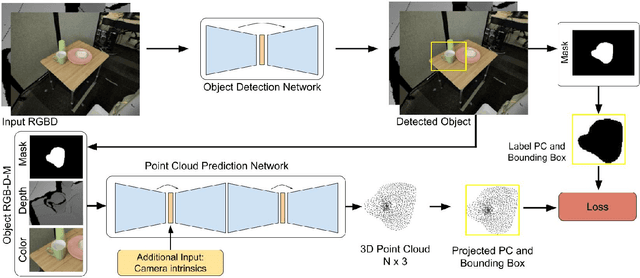
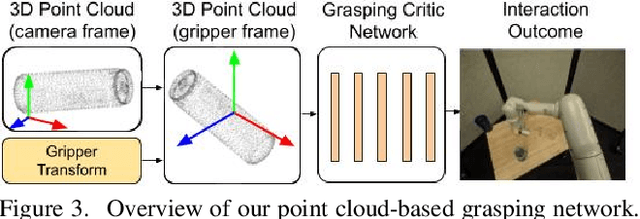
Training a deep network policy for robot manipulation is notoriously costly and time consuming as it depends on collecting a significant amount of real world data. To work well in the real world, the policy needs to see many instances of the task, including various object arrangements in the scene as well as variations in object geometry, texture, material, and environmental illumination. In this paper, we propose a method that learns to perform table-top instance grasping of a wide variety of objects while using no real world grasping data, outperforming the baseline using 2.5D shape by 10%. Our method learns 3D point cloud of object, and use that to train a domain-invariant grasping policy. We formulate the learning process as a two-step procedure: 1) Learning a domain-invariant 3D shape representation of objects from about 76K episodes in simulation and about 530 episodes in the real world, where each episode lasts less than a minute and 2) Learning a critic grasping policy in simulation only based on the 3D shape representation from step 1. Our real world data collection in step 1 is both cheaper and faster compared to existing approaches as it only requires taking multiple snapshots of the scene using a RGBD camera. Finally, the learned 3D representation is not specific to grasping, and can potentially be used in other interaction tasks.
Online Object Representations with Contrastive Learning
Jun 10, 2019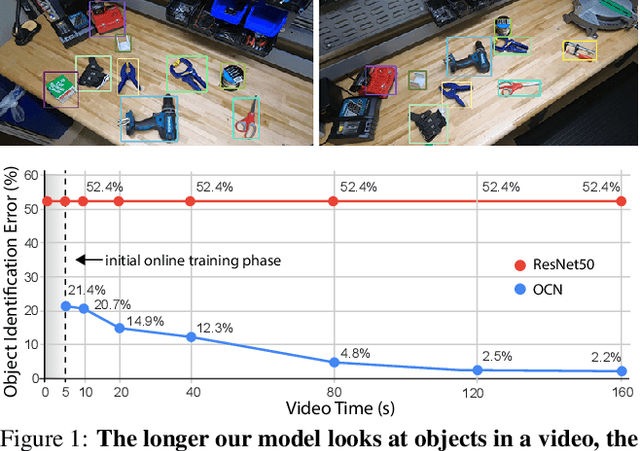
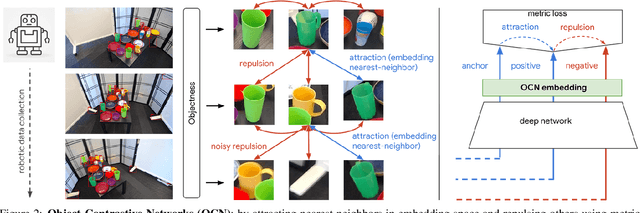

We propose a self-supervised approach for learning representations of objects from monocular videos and demonstrate it is particularly useful in situated settings such as robotics. The main contributions of this paper are: 1) a self-supervising objective trained with contrastive learning that can discover and disentangle object attributes from video without using any labels; 2) we leverage object self-supervision for online adaptation: the longer our online model looks at objects in a video, the lower the object identification error, while the offline baseline remains with a large fixed error; 3) to explore the possibilities of a system entirely free of human supervision, we let a robot collect its own data, train on this data with our self-supervise scheme, and then show the robot can point to objects similar to the one presented in front of it, demonstrating generalization of object attributes. An interesting and perhaps surprising finding of this approach is that given a limited set of objects, object correspondences will naturally emerge when using contrastive learning without requiring explicit positive pairs. Videos illustrating online object adaptation and robotic pointing are available at: https://online-objects.github.io/.
Watch, Try, Learn: Meta-Learning from Demonstrations and Reward
Jun 07, 2019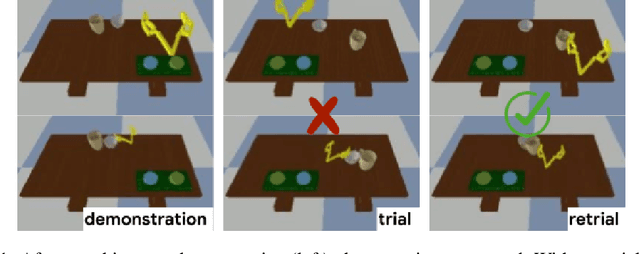
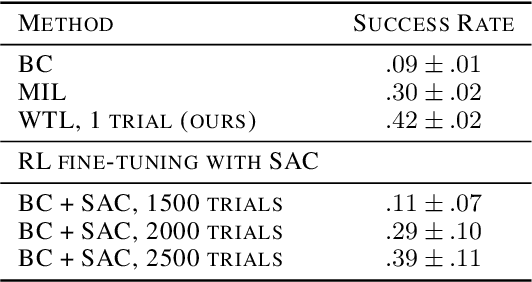
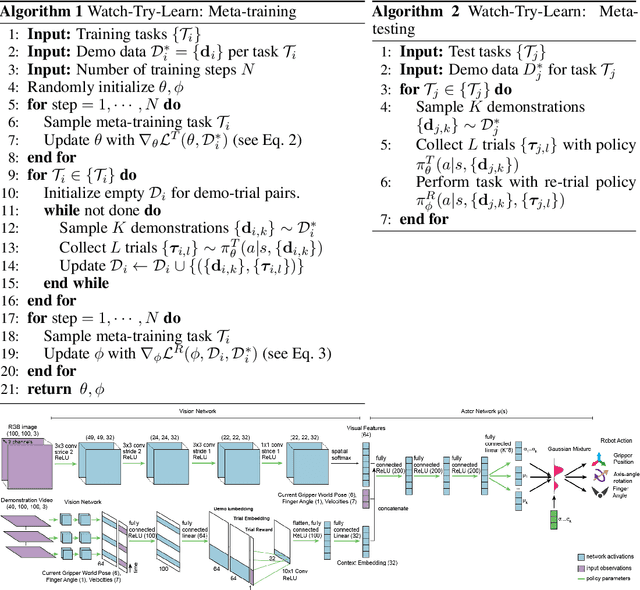
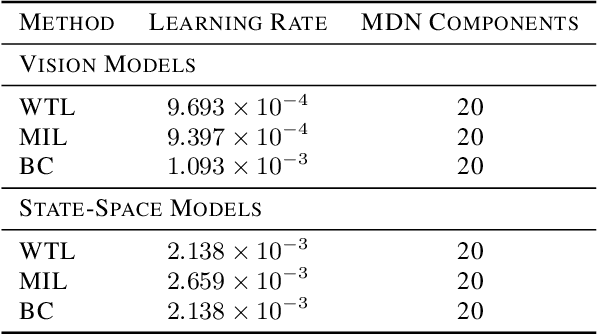
Imitation learning allows agents to learn complex behaviors from demonstrations. However, learning a complex vision-based task may require an impractical number of demonstrations. Meta-imitation learning is a promising approach towards enabling agents to learn a new task from one or a few demonstrations by leveraging experience from learning similar tasks. In the presence of task ambiguity or unobserved dynamics, demonstrations alone may not provide enough information; an agent must also try the task to successfully infer a policy. In this work, we propose a method that can learn to learn from both demonstrations and trial-and-error experience with sparse reward feedback. In comparison to meta-imitation, this approach enables the agent to effectively and efficiently improve itself autonomously beyond the demonstration data. In comparison to meta-reinforcement learning, we can scale to substantially broader distributions of tasks, as the demonstration reduces the burden of exploration. Our experiments show that our method significantly outperforms prior approaches on a set of challenging, vision-based control tasks.
Learning Latent Plans from Play
Mar 05, 2019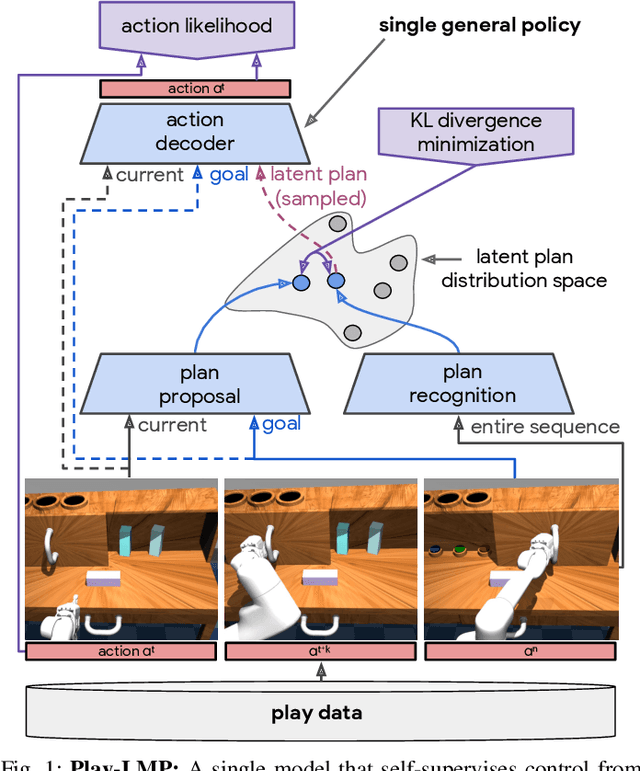
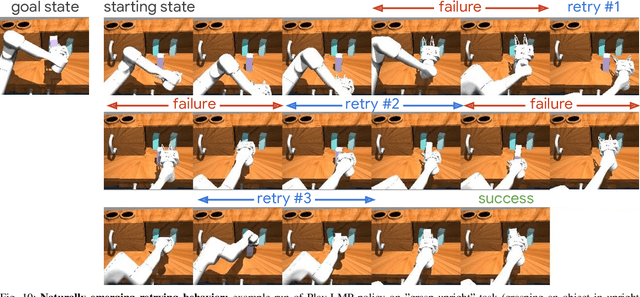
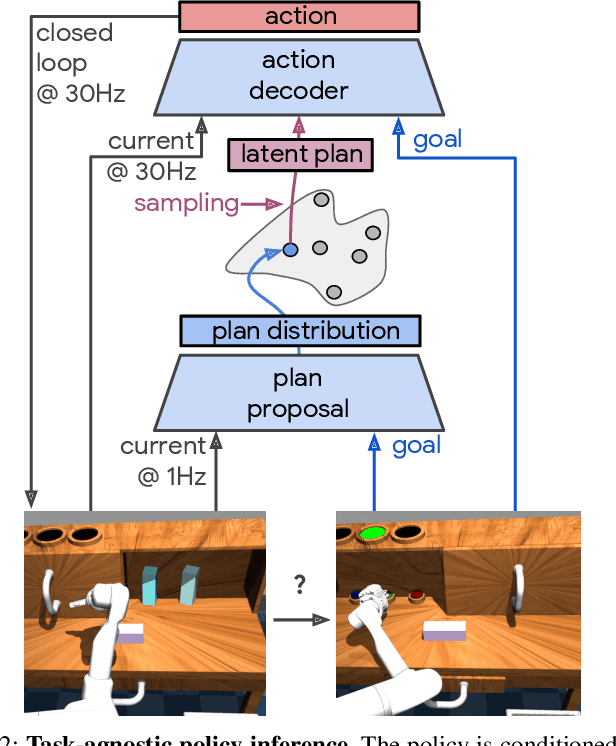

We propose learning from teleoperated play data (LfP) as a way to scale up multi-task robotic skill learning. Learning from play (LfP) offers three main advantages: 1) It is cheap. Large amounts of play data can be collected quickly as it does not require scene staging, task segmenting, or resetting to an initial state. 2) It is general. It contains both functional and non-functional behavior, relaxing the need for a predefined task distribution. 3) It is rich. Play involves repeated, varied behavior and naturally leads to high coverage of the possible interaction space. These properties distinguish play from expert demonstrations, which are rich, but expensive, and scripted unattended data collection, which is cheap, but insufficiently rich. Variety in play, however, presents a multimodality challenge to methods seeking to learn control on top. To this end, we introduce Play-LMP, a method designed to handle variability in the LfP setting by organizing it in an embedding space. Play-LMP jointly learns 1) reusable latent plan representations unsupervised from play data and 2) a single goal-conditioned policy capable of decoding inferred plans to achieve user-specified tasks. We show empirically that Play-LMP, despite not being trained on task-specific data, is capable of generalizing to 18 complex user-specified manipulation tasks with average success of 85.5%, outperforming individual models trained on expert demonstrations (success of 70.3%). Furthermore, we find that play-supervised models, unlike their expert-trained counterparts, 1) are more robust to perturbations and 2) exhibit retrying-till-success. Finally, despite never being trained with task labels, we find that our agent learns to organize its latent plan space around functional tasks. Videos of the performed experiments are available at learning-from-play.github.io
Learning 6-DOF Grasping Interaction via Deep Geometry-aware 3D Representations
Jun 15, 2018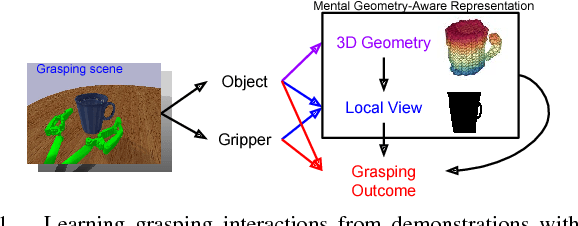
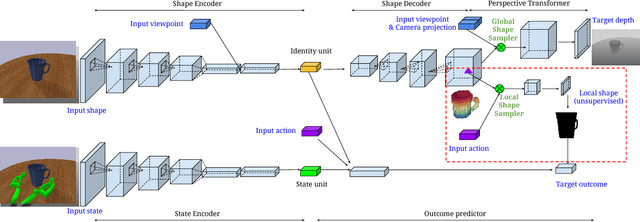
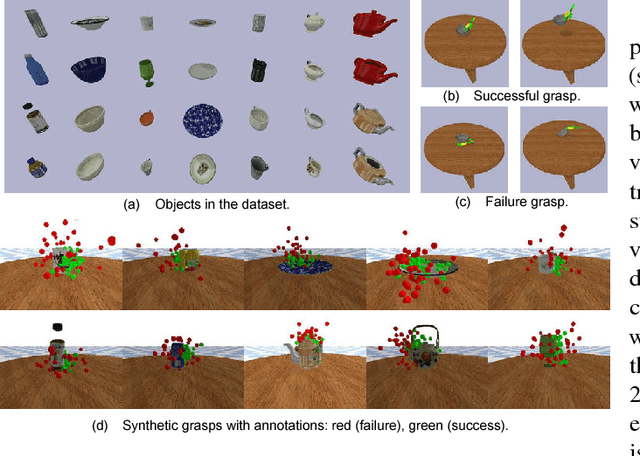
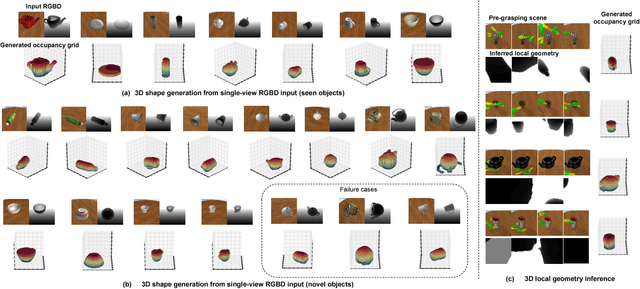
This paper focuses on the problem of learning 6-DOF grasping with a parallel jaw gripper in simulation. We propose the notion of a geometry-aware representation in grasping based on the assumption that knowledge of 3D geometry is at the heart of interaction. Our key idea is constraining and regularizing grasping interaction learning through 3D geometry prediction. Specifically, we formulate the learning of deep geometry-aware grasping model in two steps: First, we learn to build mental geometry-aware representation by reconstructing the scene (i.e., 3D occupancy grid) from RGBD input via generative 3D shape modeling. Second, we learn to predict grasping outcome with its internal geometry-aware representation. The learned outcome prediction model is used to sequentially propose grasping solutions via analysis-by-synthesis optimization. Our contributions are fourfold: (1) To best of our knowledge, we are presenting for the first time a method to learn a 6-DOF grasping net from RGBD input; (2) We build a grasping dataset from demonstrations in virtual reality with rich sensory and interaction annotations. This dataset includes 101 everyday objects spread across 7 categories, additionally, we propose a data augmentation strategy for effective learning; (3) We demonstrate that the learned geometry-aware representation leads to about 10 percent relative performance improvement over the baseline CNN on grasping objects from our dataset. (4) We further demonstrate that the model generalizes to novel viewpoints and object instances.
Learning Contracting Vector Fields For Stable Imitation Learning
Apr 13, 2018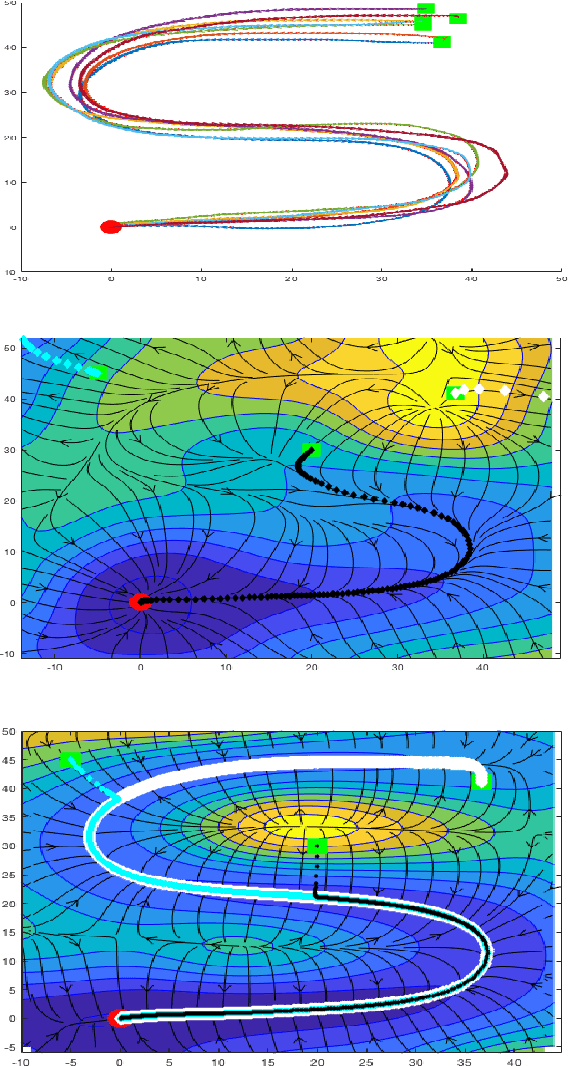

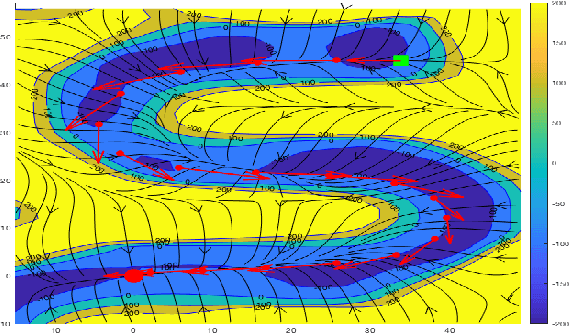
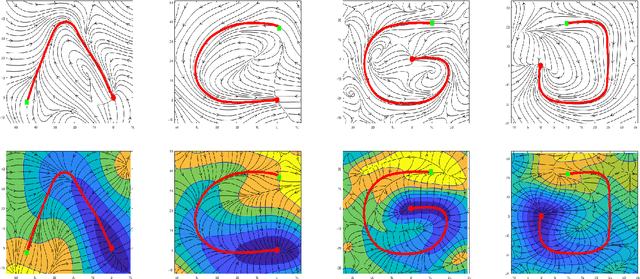
We propose a new non-parametric framework for learning incrementally stable dynamical systems x' = f(x) from a set of sampled trajectories. We construct a rich family of smooth vector fields induced by certain classes of matrix-valued kernels, whose equilibria are placed exactly at a desired set of locations and whose local contraction and curvature properties at various points can be explicitly controlled using convex optimization. With curl-free kernels, our framework may also be viewed as a mechanism to learn potential fields and gradient flows. We develop large-scale techniques using randomized kernel approximations in this context. We demonstrate our approach, called contracting vector fields (CVF), on imitation learning tasks involving complex point-to-point human handwriting motions.