 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Latent Plans from Play
Paper and Code
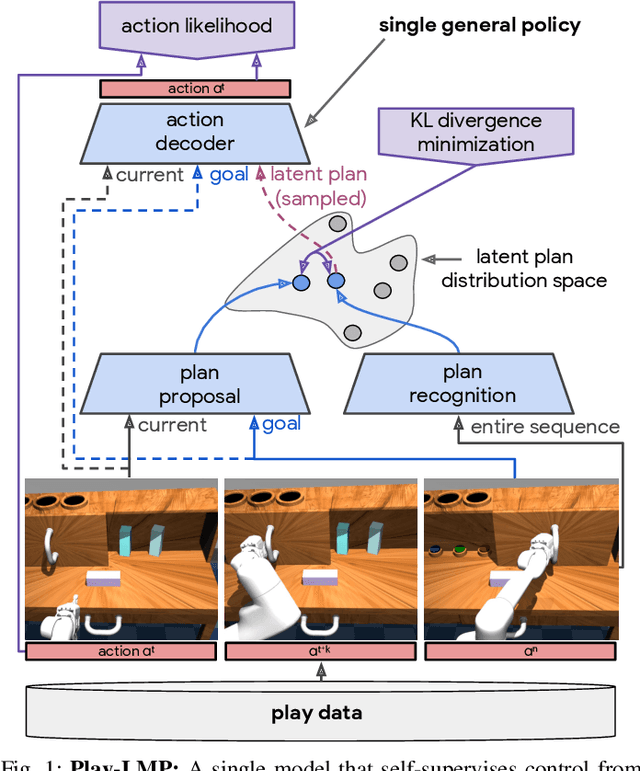
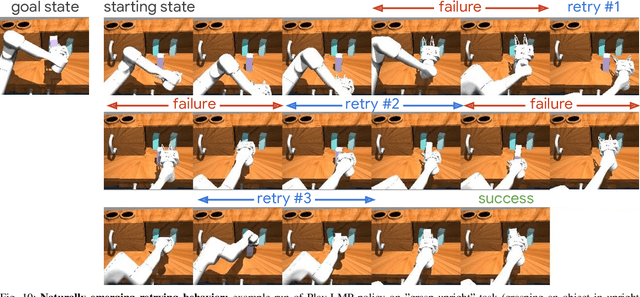
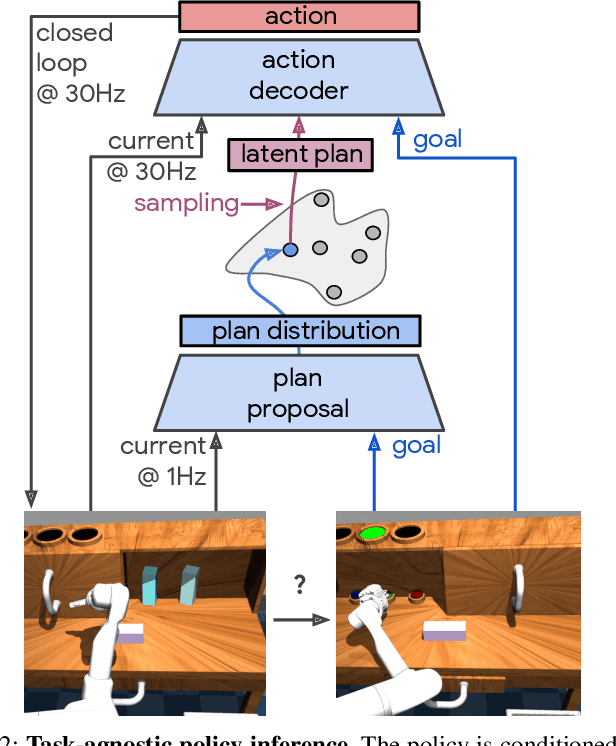

We propose learning from teleoperated play data (LfP) as a way to scale up multi-task robotic skill learning. Learning from play (LfP) offers three main advantages: 1) It is cheap. Large amounts of play data can be collected quickly as it does not require scene staging, task segmenting, or resetting to an initial state. 2) It is general. It contains both functional and non-functional behavior, relaxing the need for a predefined task distribution. 3) It is rich. Play involves repeated, varied behavior and naturally leads to high coverage of the possible interaction space. These properties distinguish play from expert demonstrations, which are rich, but expensive, and scripted unattended data collection, which is cheap, but insufficiently rich. Variety in play, however, presents a multimodality challenge to methods seeking to learn control on top. To this end, we introduce Play-LMP, a method designed to handle variability in the LfP setting by organizing it in an embedding space. Play-LMP jointly learns 1) reusable latent plan representations unsupervised from play data and 2) a single goal-conditioned policy capable of decoding inferred plans to achieve user-specified tasks. We show empirically that Play-LMP, despite not being trained on task-specific data, is capable of generalizing to 18 complex user-specified manipulation tasks with average success of 85.5%, outperforming individual models trained on expert demonstrations (success of 70.3%). Furthermore, we find that play-supervised models, unlike their expert-trained counterparts, 1) are more robust to perturbations and 2) exhibit retrying-till-success. Finally, despite never being trained with task labels, we find that our agent learns to organize its latent plan space around functional tasks. Videos of the performed experiments are available at learning-from-play.github.io