 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-lingual Knowledge Graph Alignment via Graph Matching Neural Network
May 28, 2019
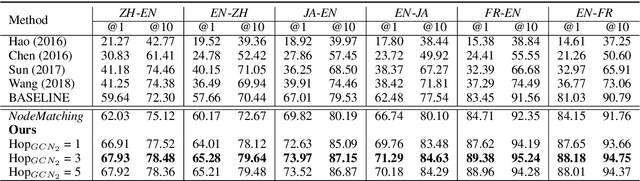
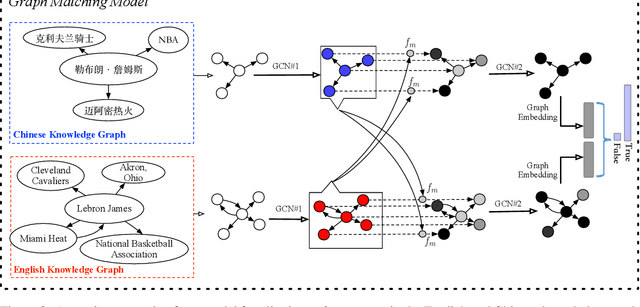
Previous cross-lingual knowledge graph (KG) alignment studies rely on entity embeddings derived only from monolingual KG structural information, which may fail at matching entities that have different facts in two KGs. In this paper, we introduce the topic entity graph, a local sub-graph of an entity, to represent entities with their contextual information in KG. From this view, the KB-alignment task can be formulated as a graph matching problem; and we further propose a graph-attention based solution, which first matches all entities in two topic entity graphs, and then jointly model the local matching information to derive a graph-level matching vector. Experiments show that our model outperforms previous state-of-the-art methods by a large margin.
Selection Bias Explorations and Debias Methods for Natural Language Sentence Matching Datasets
May 20, 2019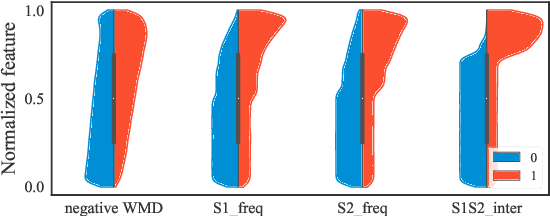
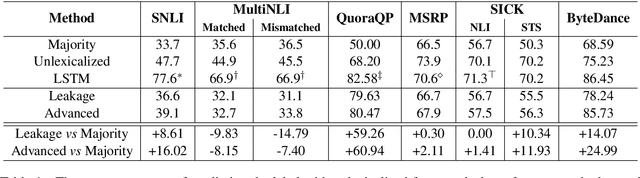
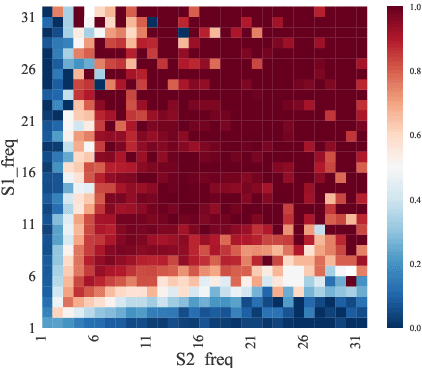
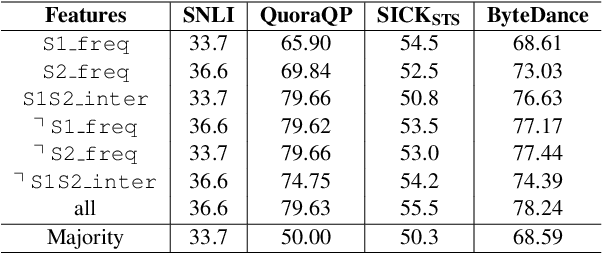
Natural Language Sentence Matching (NLSM) has gained substantial attention from both academics and the industry, and rich public datasets contribute a lot to this process. However, biased datasets can also hurt the generalization performance of trained models and give untrustworthy evaluation results. For many NLSM datasets, the providers select some pairs of sentences into the datasets, and this sampling procedure can easily bring unintended pattern, i.e., selection bias. One example is the QuoraQP dataset, where some content-independent naive features are unreasonably predictive. Such features are the reflection of the selection bias and termed as the leakage features. In this paper, we investigate the problem of selection bias on six NLSM datasets and find that four out of them are significantly biased. We further propose a training and evaluation framework to alleviate the bias. Experimental results on QuoraQP suggest that the proposed framework can improve the generalization ability of trained models, and give more trustworthy evaluation results for real-world adoptions.
DAG-GNN: DAG Structure Learning with Graph Neural Networks
Apr 22, 2019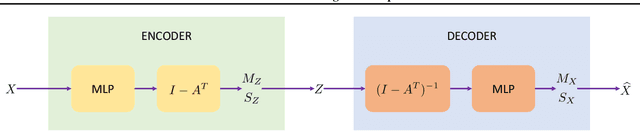
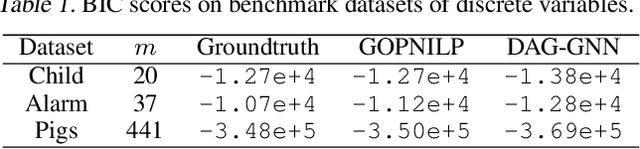
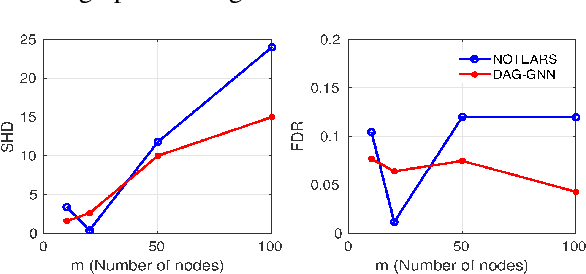
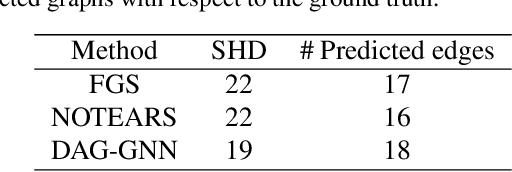
Learning a faithful directed acyclic graph (DAG) from samples of a joint distribution is a challenging combinatorial problem, owing to the intractable search space superexponential in the number of graph nodes. A recent breakthrough formulates the problem as a continuous optimization with a structural constraint that ensures acyclicity (Zheng et al., 2018). The authors apply the approach to the linear structural equation model (SEM) and the least-squares loss function that are statistically well justified but nevertheless limited. Motivated by the widespread success of deep learning that is capable of capturing complex nonlinear mappings, in this work we propose a deep generative model and apply a variant of the structural constraint to learn the DAG. At the heart of the generative model is a variational autoencoder parameterized by a novel graph neural network architecture, which we coin DAG-GNN. In addition to the richer capacity, an advantage of the proposed model is that it naturally handles discrete variables as well as vector-valued ones. We demonstrate that on synthetic data sets, the proposed method learns more accurate graphs for nonlinearly generated samples; and on benchmark data sets with discrete variables, the learned graphs are reasonably close to the global optima. The code is available at \url{https://github.com/fishmoon1234/DAG-GNN}.
A Hybrid Approach with Optimization and Metric-based Meta-Learner for Few-Shot Learning
Apr 04, 2019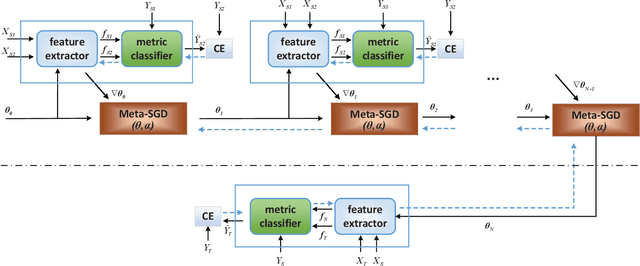
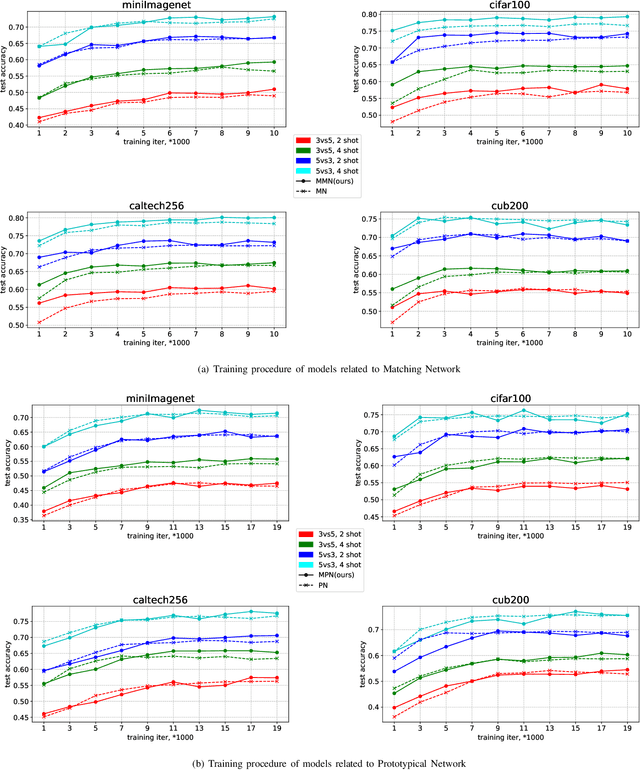
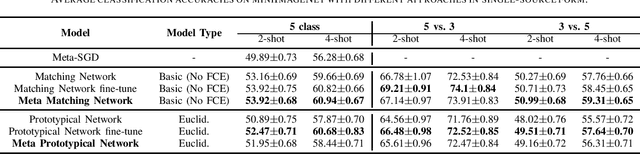
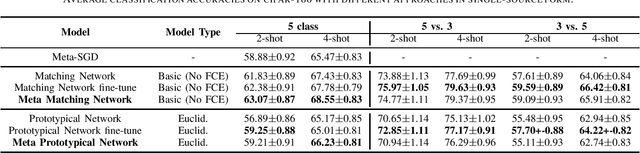
Few-shot learning aims to learn classifiers for new classes with only a few training examples per class. Most existing few-shot learning approaches belong to either metric-based meta-learning or optimization-based meta-learning category, both of which have achieved successes in the simplified "$k$-shot $N$-way" image classification settings. Specifically, the optimization-based approaches train a meta-learner to predict the parameters of the task-specific classifiers. The task-specific classifiers are required to be homogeneous-structured to ease the parameter prediction, so the meta-learning approaches could only handle few-shot learning problems where the tasks share a uniform number of classes. The metric-based approaches learn one task-invariant metric for all the tasks. Even though the metric-learning approaches allow different numbers of classes, they require the tasks all coming from a similar domain such that there exists a uniform metric that could work across tasks. In this work, we propose a hybrid meta-learning model called Meta-Metric-Learner which combines the merits of both optimization- and metric-based approaches. Our meta-metric-learning approach consists of two components, a task-specific metric-based learner as a base model, and a meta-learner that learns and specifies the base model. Thus our model is able to handle flexible numbers of classes as well as generate more generalized metrics for classification across tasks. We test our approach in the standard "$k$-shot $N$-way" few-shot learning setting following previous works and a new realistic few-shot setting with flexible class numbers in both single-source form and multi-source forms. Experiments show that our approach can obtain superior performance in all settings.
Sentence Embedding Alignment for Lifelong Relation Extraction
Mar 26, 2019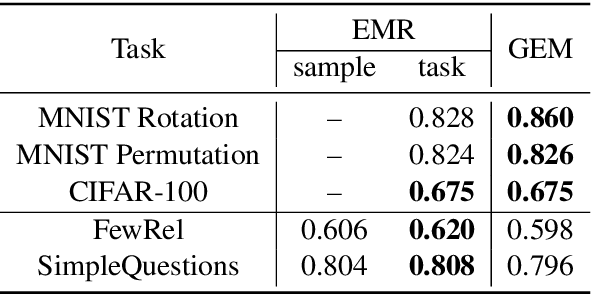
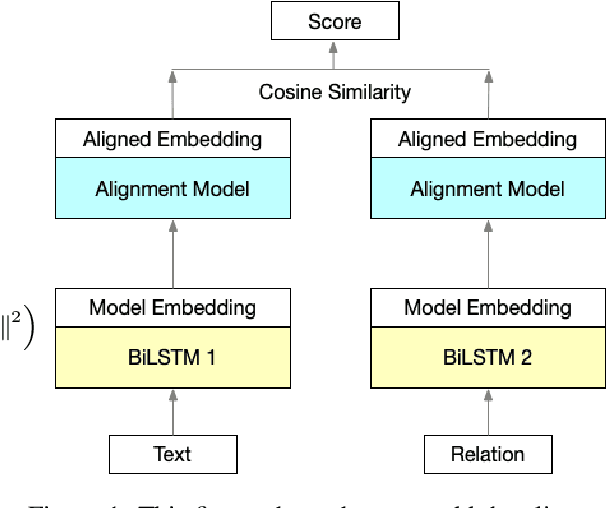
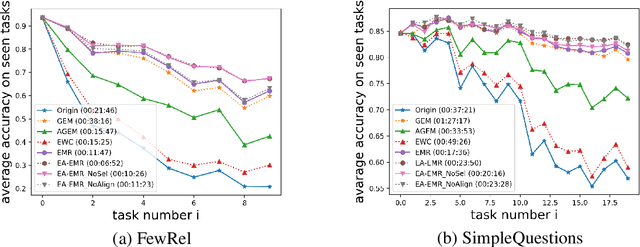
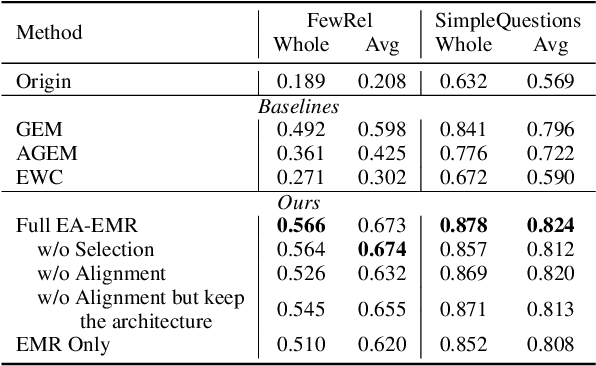
Conventional approaches to relation extraction usually require a fixed set of pre-defined relations. Such requirement is hard to meet in many real applications, especially when new data and relations are emerging incessantly and it is computationally expensive to store all data and re-train the whole model every time new data and relations come in. We formulate such a challenging problem as lifelong relation extraction and investigate memory-efficient incremental learning methods without catastrophically forgetting knowledge learned from previous tasks. We first investigate a modified version of the stochastic gradient methods with a replay memory, which surprisingly outperforms recent state-of-the-art lifelong learning methods. We further propose to improve this approach to alleviate the forgetting problem by anchoring the sentence embedding space. Specifically, we utilize an explicit alignment model to mitigate the sentence embedding distortion of the learned model when training on new data and new relations. Experiment results on multiple benchmarks show that our proposed method significantly outperforms the state-of-the-art lifelong learning approaches.
Hybrid Reinforcement Learning with Expert State Sequences
Mar 11, 2019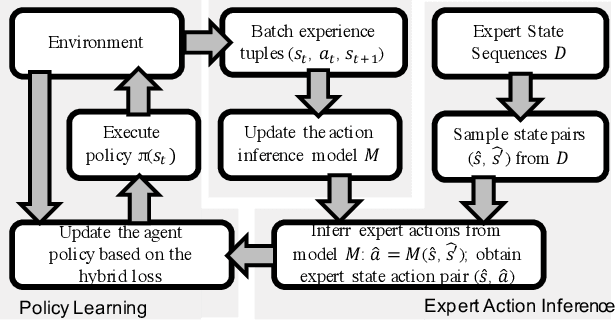
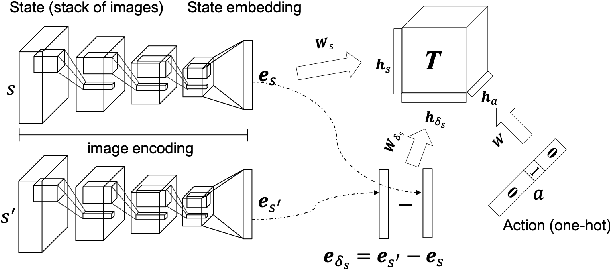
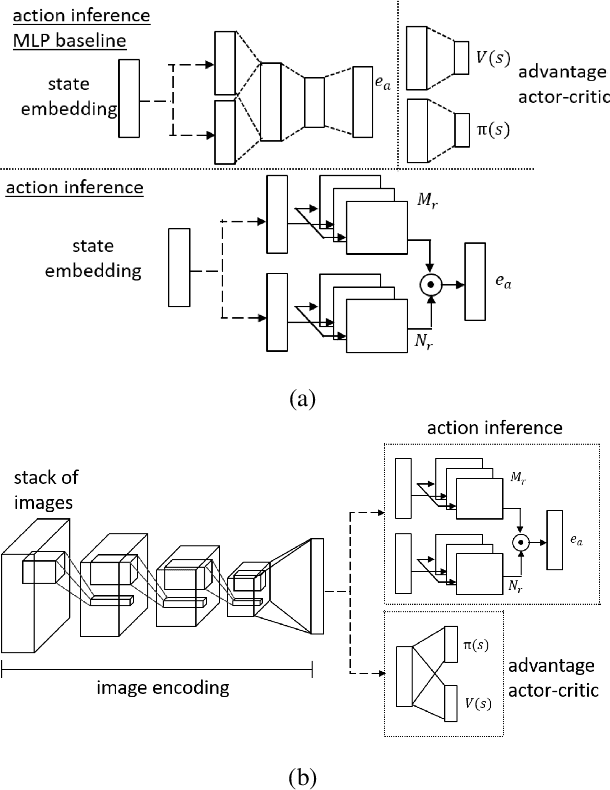
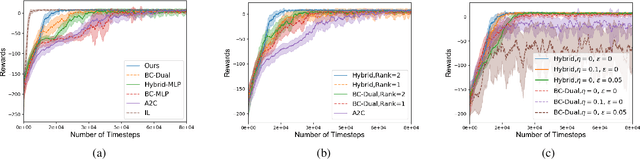
Existing imitation learning approaches often require that the complete demonstration data, including sequences of actions and states, are available. In this paper, we consider a more realistic and difficult scenario where a reinforcement learning agent only has access to the state sequences of an expert, while the expert actions are unobserved. We propose a novel tensor-based model to infer the unobserved actions of the expert state sequences. The policy of the agent is then optimized via a hybrid objective combining reinforcement learning and imitation learning. We evaluated our hybrid approach on an illustrative domain and Atari games. The empirical results show that (1) the agents are able to leverage state expert sequences to learn faster than pure reinforcement learning baselines, (2) our tensor-based action inference model is advantageous compared to standard deep neural networks in inferring expert actions, and (3) the hybrid policy optimization objective is robust against noise in expert state sequences.
Imposing Label-Relational Inductive Bias for Extremely Fine-Grained Entity Typing
Mar 06, 2019
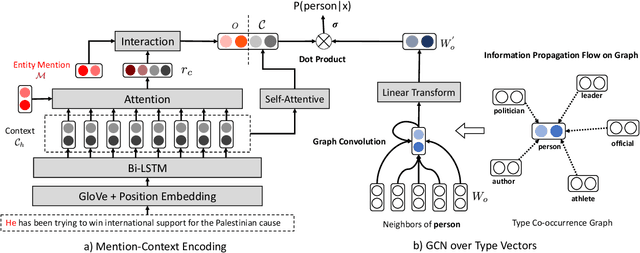
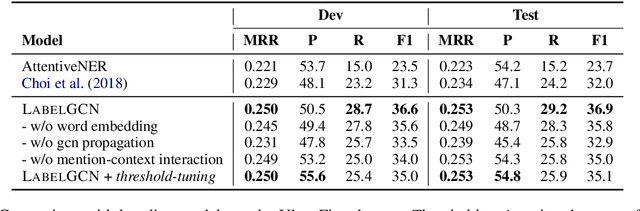
Existing entity typing systems usually exploit the type hierarchy provided by knowledge base (KB) schema to model label correlations and thus improve the overall performance. Such techniques, however, are not directly applicable to more open and practical scenarios where the type set is not restricted by KB schema and includes a vast number of free-form types. To model the underly-ing label correlations without access to manually annotated label structures, we introduce a novel label-relational inductive bias, represented by a graph propagation layer that effectively encodes both global label co-occurrence statistics and word-level similarities.On a large dataset with over 10,000 free-form types, the graph-enhanced model equipped with an attention-based matching module is able to achieve a much higher recall score while maintaining a high-level precision. Specifically, it achieves a 15.3% relative F1 improvement and also less inconsistency in the outputs. We further show that a simple modification of our proposed graph layer can also improve the performance on a conventional and widely-tested dataset that only includes KB-schema types.
Extracting Multiple-Relations in One-Pass with Pre-Trained Transformers
Feb 04, 2019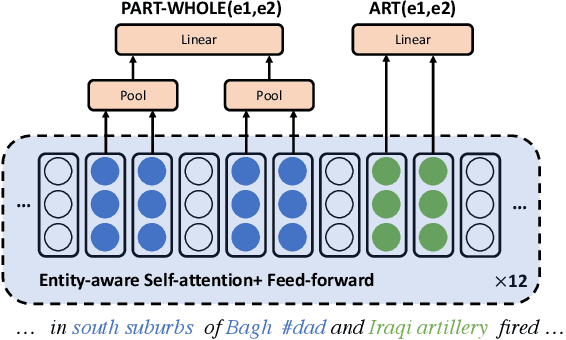
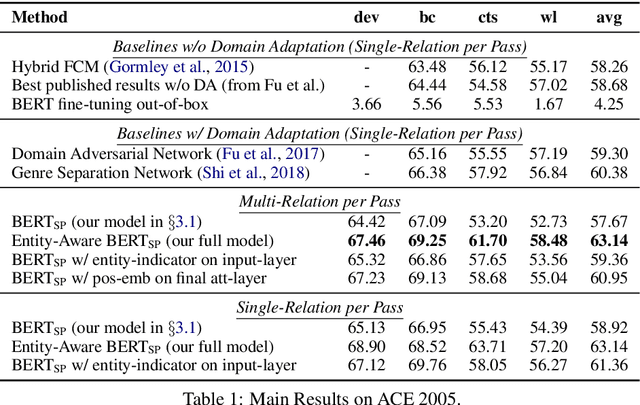

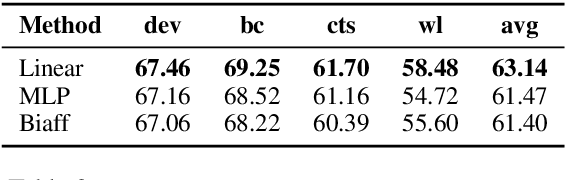
Most approaches to extraction multiple relations from a paragraph require multiple passes over the paragraph. In practice, multiple passes are computationally expensive and this makes difficult to scale to longer paragraphs and larger text corpora. In this work, we focus on the task of multiple relation extraction by encoding the paragraph only once (one-pass). We build our solution on the pre-trained self-attentive (Transformer) models, where we first add a structured prediction layer to handle extraction between multiple entity pairs, then enhance the paragraph embedding to capture multiple relational information associated with each entity with an entity-aware attention technique. We show that our approach is not only scalable but can also perform state-of-the-art on the standard benchmark ACE 2005.
Few-shot Learning with Meta Metric Learners
Jan 26, 2019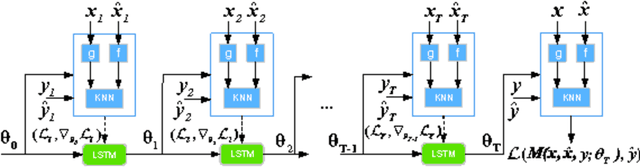
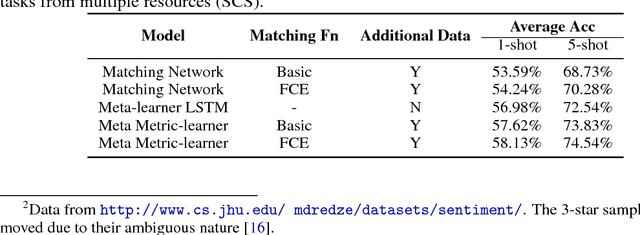

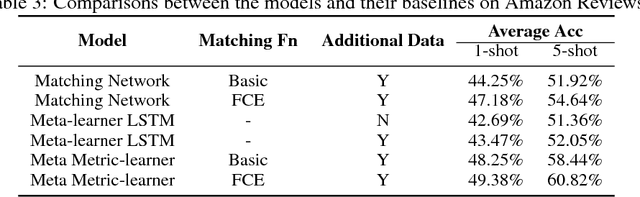
Few-shot Learning aims to learn classifiers for new classes with only a few training examples per class. Existing meta-learning or metric-learning based few-shot learning approaches are limited in handling diverse domains with various number of labels. The meta-learning approaches train a meta learner to predict weights of homogeneous-structured task-specific networks, requiring a uniform number of classes across tasks. The metric-learning approaches learn one task-invariant metric for all the tasks, and they fail if the tasks diverge. We propose to deal with these limitations with meta metric learning. Our meta metric learning approach consists of task-specific learners, that exploit metric learning to handle flexible labels, and a meta learner, that discovers good parameters and gradient decent to specify the metrics in task-specific learners. Thus the proposed model is able to handle unbalanced classes as well as to generate task-specific metrics. We test our approach in the `$k$-shot $N$-way' few-shot learning setting used in previous work and new realistic few-shot setting with diverse multi-domain tasks and flexible label numbers. Experiments show that our approach attains superior performances in both settings.
Improving Natural Language Inference Using External Knowledge in the Science Questions Domain
Sep 15, 2018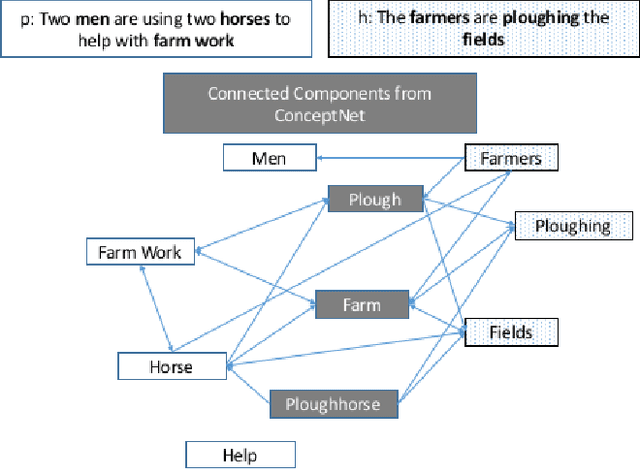
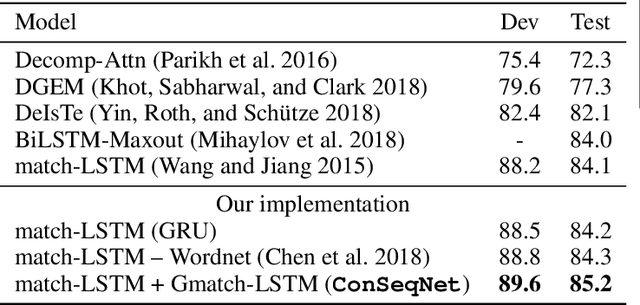
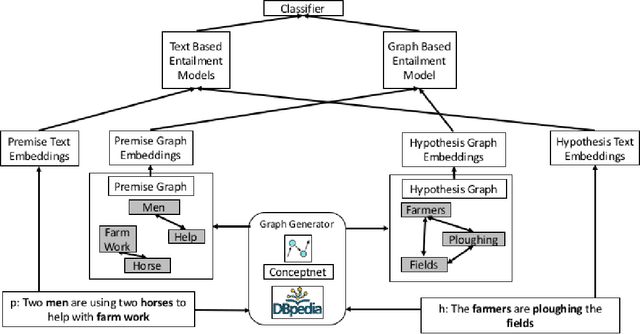
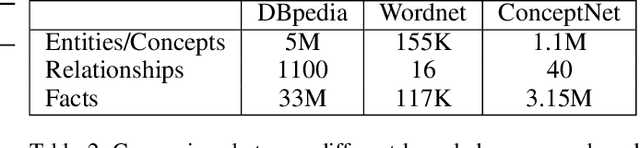
Natural Language Inference (NLI) is fundamental to many Natural Language Processing (NLP) applications including semantic search and question answering. The NLI problem has gained significant attention thanks to the release of large scale, challenging datasets. Present approaches to the problem largely focus on learning-based methods that use only textual information in order to classify whether a given premise entails, contradicts, or is neutral with respect to a given hypothesis. Surprisingly, the use of methods based on structured knowledge -- a central topic in artificial intelligence -- has not received much attention vis-a-vis the NLI problem. While there are many open knowledge bases that contain various types of reasoning information, their use for NLI has not been well explored. To address this, we present a combination of techniques that harness knowledge graphs to improve performance on the NLI problem in the science questions domain. We present the results of applying our techniques on text, graph, and text-to-graph based models, and discuss implications for the use of external knowledge in solving the NLI problem. Our model achieves the new state-of-the-art performance on the NLI problem over the SciTail science questions dataset.