 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChaining Simultaneous Thoughts for Numerical Reasoning
Nov 29, 2022Given that rich information is hidden behind ubiquitous numbers in text, numerical reasoning over text should be an essential skill of AI systems. To derive precise equations to solve numerical reasoning problems, previous work focused on modeling the structures of equations, and has proposed various structured decoders. Though structure modeling proves to be effective, these structured decoders construct a single equation in a pre-defined autoregressive order, potentially placing an unnecessary restriction on how a model should grasp the reasoning process. Intuitively, humans may have numerous pieces of thoughts popping up in no pre-defined order; thoughts are not limited to the problem at hand, and can even be concerned with other related problems. By comparing diverse thoughts and chaining relevant pieces, humans are less prone to errors. In this paper, we take this inspiration and propose CANTOR, a numerical reasoner that models reasoning steps using a directed acyclic graph where we produce diverse reasoning steps simultaneously without pre-defined decoding dependencies, and compare and chain relevant ones to reach a solution. Extensive experiments demonstrated the effectiveness of CANTOR under both fully-supervised and weakly-supervised settings.
AutoCAD: Automatically Generating Counterfactuals for Mitigating Shortcut Learning
Nov 29, 2022



Recent studies have shown the impressive efficacy of counterfactually augmented data (CAD) for reducing NLU models' reliance on spurious features and improving their generalizability. However, current methods still heavily rely on human efforts or task-specific designs to generate counterfactuals, thereby impeding CAD's applicability to a broad range of NLU tasks. In this paper, we present AutoCAD, a fully automatic and task-agnostic CAD generation framework. AutoCAD first leverages a classifier to unsupervisedly identify rationales as spans to be intervened, which disentangles spurious and causal features. Then, AutoCAD performs controllable generation enhanced by unlikelihood training to produce diverse counterfactuals. Extensive evaluations on multiple out-of-domain and challenge benchmarks demonstrate that AutoCAD consistently and significantly boosts the out-of-distribution performance of powerful pre-trained models across different NLU tasks, which is comparable or even better than previous state-of-the-art human-in-the-loop or task-specific CAD methods. The code is publicly available at https://github.com/thu-coai/AutoCAD.
Aligning Recommendation and Conversation via Dual Imitation
Nov 05, 2022



Human conversations of recommendation naturally involve the shift of interests which can align the recommendation actions and conversation process to make accurate recommendations with rich explanations. However, existing conversational recommendation systems (CRS) ignore the advantage of user interest shift in connecting recommendation and conversation, which leads to an ineffective loose coupling structure of CRS. To address this issue, by modeling the recommendation actions as recommendation paths in a knowledge graph (KG), we propose DICR (Dual Imitation for Conversational Recommendation), which designs a dual imitation to explicitly align the recommendation paths and user interest shift paths in a recommendation module and a conversation module, respectively. By exchanging alignment signals, DICR achieves bidirectional promotion between recommendation and conversation modules and generates high-quality responses with accurate recommendations and coherent explanations. Experiments demonstrate that DICR outperforms the state-of-the-art models on recommendation and conversation performance with automatic, human, and novel explainability metrics.
Learning Instructions with Unlabeled Data for Zero-Shot Cross-Task Generalization
Oct 17, 2022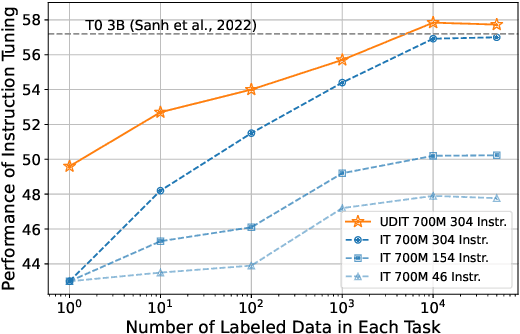
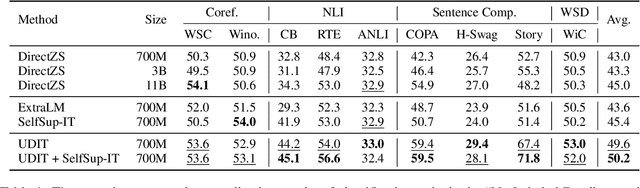
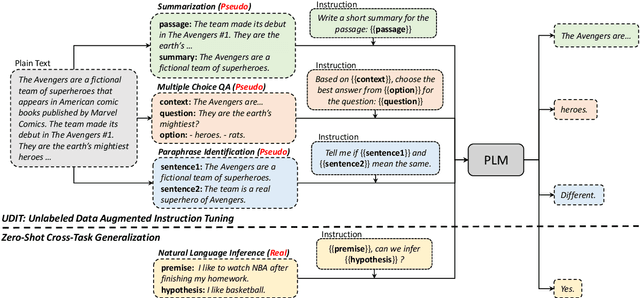
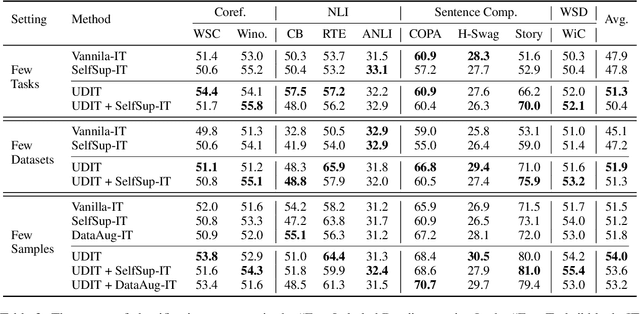
Training language models to learn from human instructions for zero-shot cross-task generalization has attracted much attention in NLP communities. Recently, instruction tuning (IT), which fine-tunes a pre-trained language model on a massive collection of tasks described via human-craft instructions, has been shown effective in instruction learning for unseen tasks. However, IT relies on a large amount of human-annotated samples, which restricts its generalization. Unlike labeled data, unlabeled data are often massive and cheap to obtain. In this work, we study how IT can be improved with unlabeled data. We first empirically explore the IT performance trends versus the number of labeled data, instructions, and training tasks. We find it critical to enlarge the number of training instructions, and the instructions can be underutilized due to the scarcity of labeled data. Then, we propose Unlabeled Data Augmented Instruction Tuning (UDIT) to take better advantage of the instructions during IT by constructing pseudo-labeled data from unlabeled plain texts. We conduct extensive experiments to show UDIT's effectiveness in various scenarios of tasks and datasets. We also comprehensively analyze the key factors of UDIT to investigate how to better improve IT with unlabeled data. The code is publicly available at https://github.com/thu-coai/UDIT.
CDConv: A Benchmark for Contradiction Detection in Chinese Conversations
Oct 16, 2022
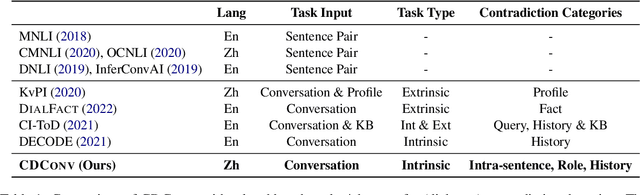

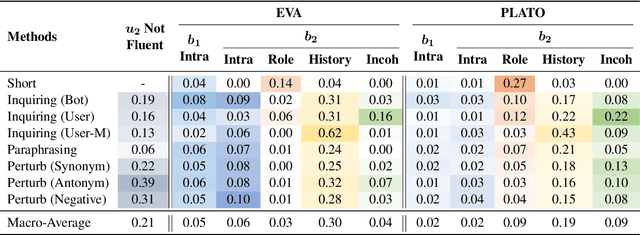
Dialogue contradiction is a critical issue in open-domain dialogue systems. The contextualization nature of conversations makes dialogue contradiction detection rather challenging. In this work, we propose a benchmark for Contradiction Detection in Chinese Conversations, namely CDConv. It contains 12K multi-turn conversations annotated with three typical contradiction categories: Intra-sentence Contradiction, Role Confusion, and History Contradiction. To efficiently construct the CDConv conversations, we devise a series of methods for automatic conversation generation, which simulate common user behaviors that trigger chatbots to make contradictions. We conduct careful manual quality screening of the constructed conversations and show that state-of-the-art Chinese chatbots can be easily goaded into making contradictions. Experiments on CDConv show that properly modeling contextual information is critical for dialogue contradiction detection, but there are still unresolved challenges that require future research.
Chatbots for Mental Health Support: Exploring the Impact of Emohaa on Reducing Mental Distress in China
Sep 21, 2022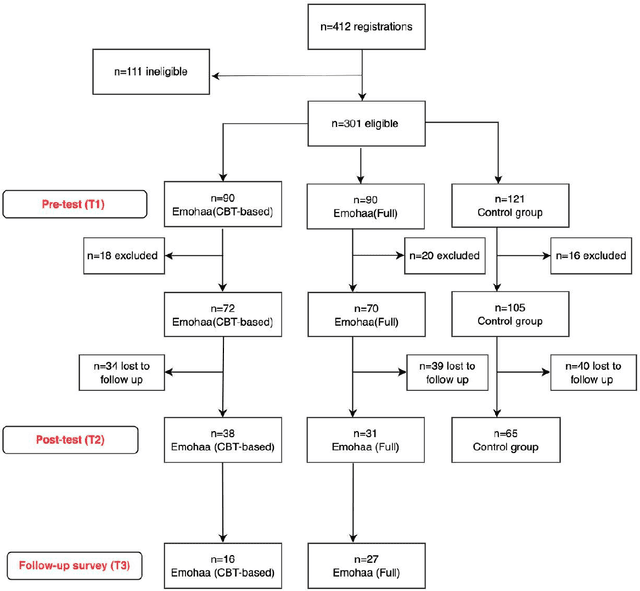

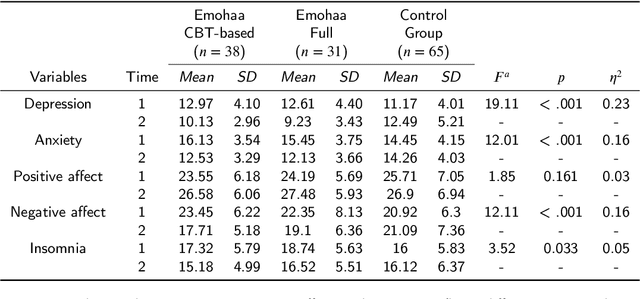
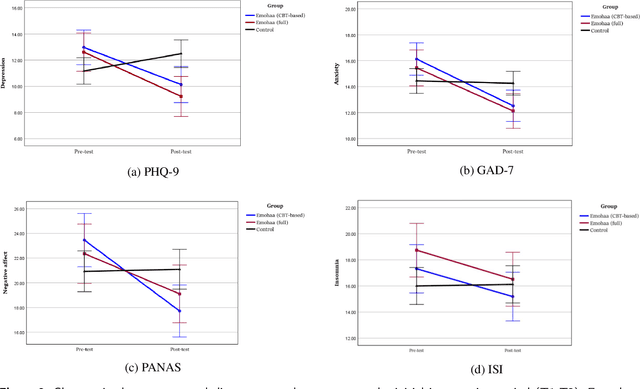
The growing demand for mental health support has highlighted the importance of conversational agents as human supporters worldwide and in China. These agents could increase availability and reduce the relative costs of mental health support. The provided support can be divided into two main types: cognitive and emotional support. Existing work on this topic mainly focuses on constructing agents that adopt Cognitive Behavioral Therapy (CBT) principles. Such agents operate based on pre-defined templates and exercises to provide cognitive support. However, research on emotional support using such agents is limited. In addition, most of the constructed agents operate in English, highlighting the importance of conducting such studies in China. In this study, we analyze the effectiveness of Emohaa in reducing symptoms of mental distress. Emohaa is a conversational agent that provides cognitive support through CBT-based exercises and guided conversations. It also emotionally supports users by enabling them to vent their desired emotional problems. The study included 134 participants, split into three groups: Emohaa (CBT-based), Emohaa (Full), and control. Experimental results demonstrated that compared to the control group, participants who used Emohaa experienced considerably more significant improvements in symptoms of mental distress. We also found that adding the emotional support agent had a complementary effect on such improvements, mainly depression and insomnia. Based on the obtained results and participants' satisfaction with the platform, we concluded that Emohaa is a practical and effective tool for reducing mental distress.
A Benchmark for Understanding and Generating Dialogue between Characters in Stories
Sep 18, 2022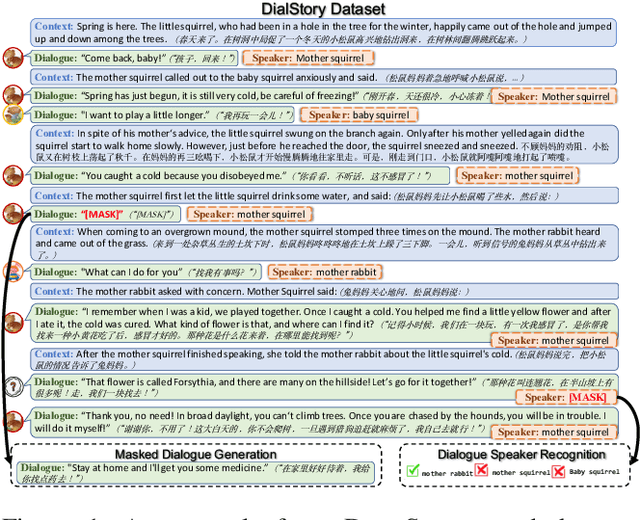
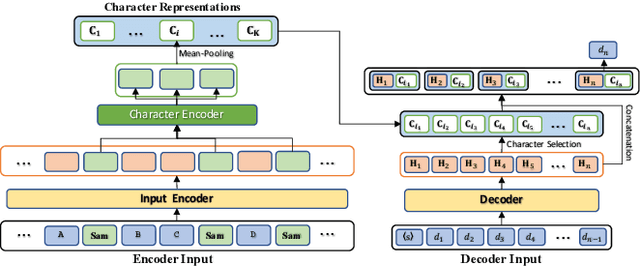
Many classical fairy tales, fiction, and screenplays leverage dialogue to advance story plots and establish characters. We present the first study to explore whether machines can understand and generate dialogue in stories, which requires capturing traits of different characters and the relationships between them. To this end, we propose two new tasks including Masked Dialogue Generation and Dialogue Speaker Recognition, i.e., generating missing dialogue turns and predicting speakers for specified dialogue turns, respectively. We build a new dataset DialStory, which consists of 105k Chinese stories with a large amount of dialogue weaved into the plots to support the evaluation. We show the difficulty of the proposed tasks by testing existing models with automatic and manual evaluation on DialStory. Furthermore, we propose to learn explicit character representations to improve performance on these tasks. Extensive experiments and case studies show that our approach can generate more coherent and informative dialogue, and achieve higher speaker recognition accuracy than strong baselines.
StoryTrans: Non-Parallel Story Author-Style Transfer with Discourse Representations and Content Enhancing
Aug 29, 2022
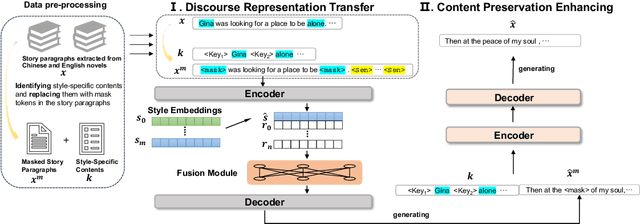
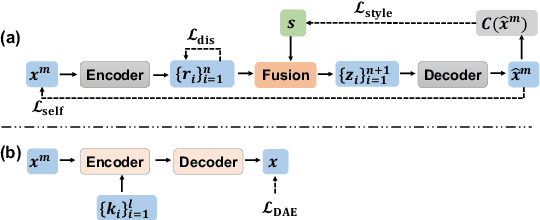
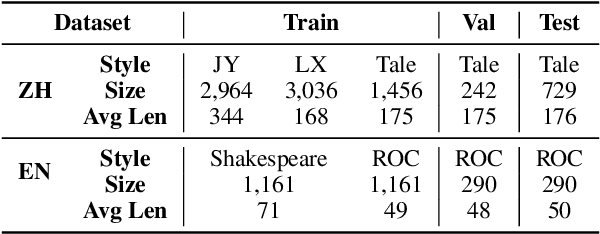
Non-parallel text style transfer is an important task in natural language generation. However, previous studies concentrate on the token or sentence level, such as sentence sentiment and formality transfer, but neglect long style transfer at the discourse level. Long texts usually involve more complicated author linguistic preferences such as discourse structures than sentences. In this paper, we formulate the task of non-parallel story author-style transfer, which requires transferring an input story into a specified author style while maintaining source semantics. To tackle this problem, we propose a generation model, named StoryTrans, which leverages discourse representations to capture source content information and transfer them to target styles with learnable style embeddings. We use an additional training objective to disentangle stylistic features from the learned discourse representation to prevent the model from degenerating to an auto-encoder. Moreover, to enhance content preservation, we design a mask-and-fill framework to explicitly fuse style-specific keywords of source texts into generation. Furthermore, we constructed new datasets for this task in Chinese and English, respectively. Extensive experiments show that our model outperforms strong baselines in overall performance of style transfer and content preservation.
CASE: Aligning Coarse-to-Fine Cognition and Affection for Empathetic Response Generation
Aug 18, 2022
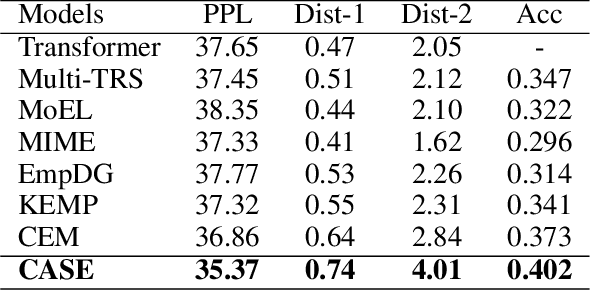
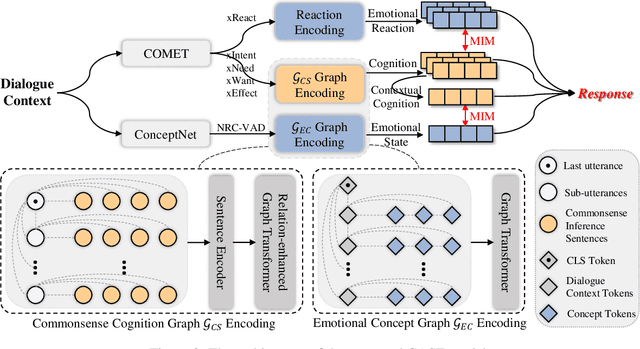
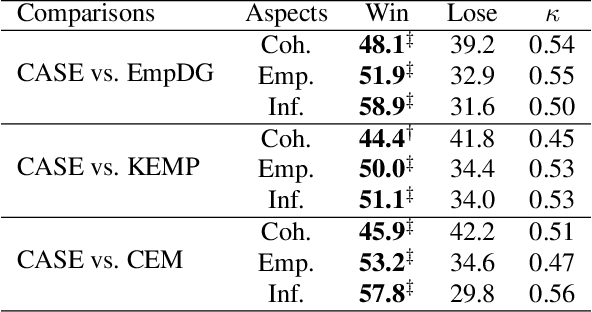
Empathy is a trait that naturally manifests in human conversation. Theoretically, the birth of empathetic responses results from conscious alignment and interaction between cognition and affection of empathy. However, existing works rely solely on a single affective aspect or model cognition and affection independently, limiting the empathetic capabilities of the generated responses. To this end, based on the commonsense cognition graph and emotional concept graph constructed involving commonsense and concept knowledge, we design a two-level strategy to align coarse-grained (between contextual cognition and contextual emotional state) and fine-grained (between each specific cognition and corresponding emotional reaction) Cognition and Affection for reSponding Empathetically (CASE). Extensive experiments demonstrate that CASE outperforms the state-of-the-art baselines on automatic and human evaluation. Our code will be released.
Manual-Guided Dialogue for Flexible Conversational Agents
Aug 16, 2022
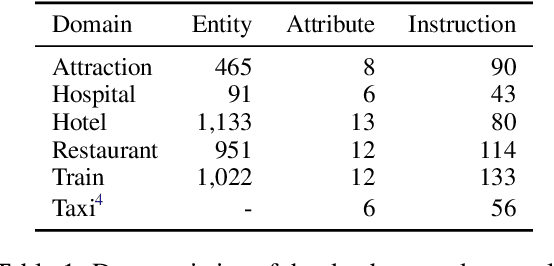
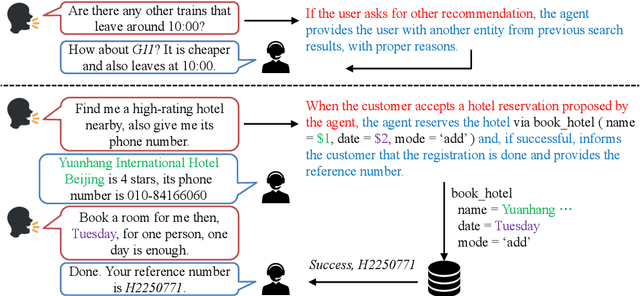
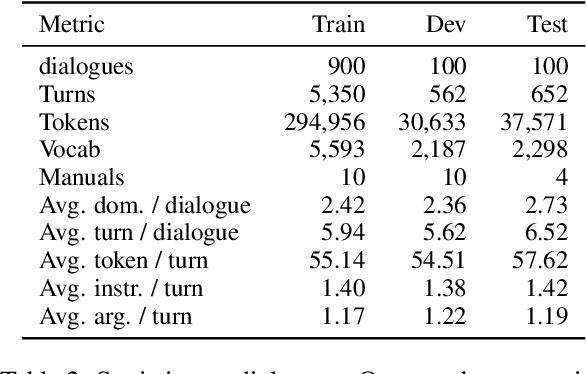
How to build and use dialogue data efficiently, and how to deploy models in different domains at scale can be two critical issues in building a task-oriented dialogue system. In this paper, we propose a novel manual-guided dialogue scheme to alleviate these problems, where the agent learns the tasks from both dialogue and manuals. The manual is an unstructured textual document that guides the agent in interacting with users and the database during the conversation. Our proposed scheme reduces the dependence of dialogue models on fine-grained domain ontology, and makes them more flexible to adapt to various domains. We then contribute a fully-annotated multi-domain dataset MagDial to support our scheme. It introduces three dialogue modeling subtasks: instruction matching, argument filling, and response generation. Modeling these subtasks is consistent with the human agent's behavior patterns. Experiments demonstrate that the manual-guided dialogue scheme improves data efficiency and domain scalability in building dialogue systems. The dataset and benchmark will be publicly available for promoting future research.