 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Test-Time Model Adaptation without Forgetting
Apr 06, 2022
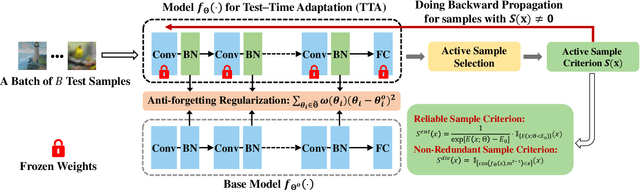
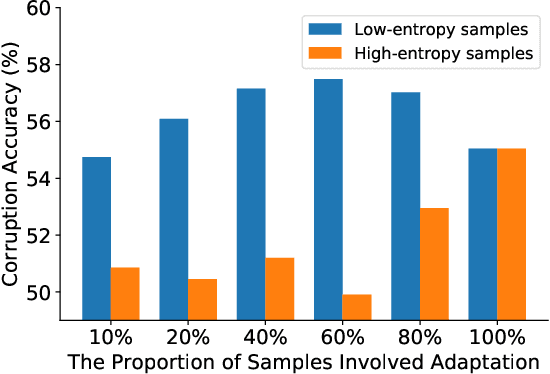
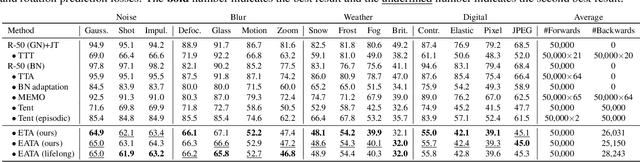
Test-time adaptation (TTA) seeks to tackle potential distribution shifts between training and testing data by adapting a given model w.r.t. any testing sample. This task is particularly important for deep models when the test environment changes frequently. Although some recent attempts have been made to handle this task, we still face two practical challenges: 1) existing methods have to perform backward computation for each test sample, resulting in unbearable prediction cost to many applications; 2) while existing TTA solutions can significantly improve the test performance on out-of-distribution data, they often suffer from severe performance degradation on in-distribution data after TTA (known as catastrophic forgetting). In this paper, we point out that not all the test samples contribute equally to model adaptation, and high-entropy ones may lead to noisy gradients that could disrupt the model. Motivated by this, we propose an active sample selection criterion to identify reliable and non-redundant samples, on which the model is updated to minimize the entropy loss for test-time adaptation. Furthermore, to alleviate the forgetting issue, we introduce a Fisher regularizer to constrain important model parameters from drastic changes, where the Fisher importance is estimated from test samples with generated pseudo labels. Extensive experiments on CIFAR-10-C, ImageNet-C, and ImageNet-R verify the effectiveness of our proposed method.
Boost Test-Time Performance with Closed-Loop Inference
Mar 26, 2022
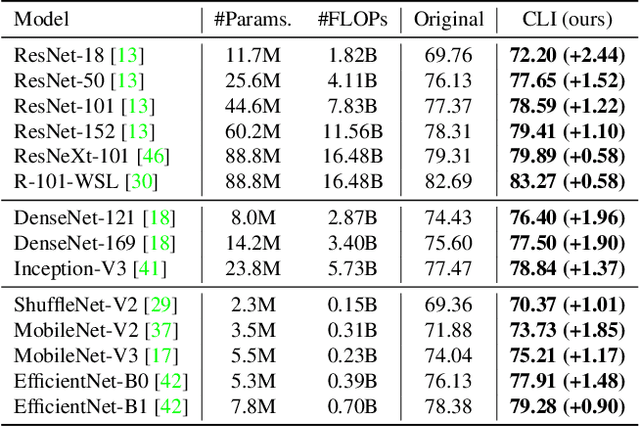
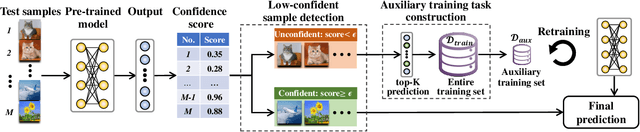
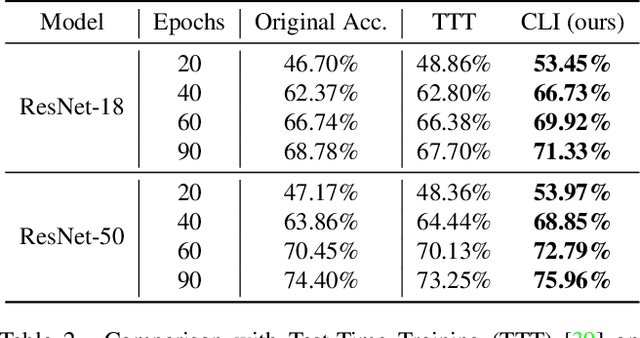
Conventional deep models predict a test sample with a single forward propagation, which, however, may not be sufficient for predicting hard-classified samples. On the contrary, we human beings may need to carefully check the sample many times before making a final decision. During the recheck process, one may refine/adjust the prediction by referring to related samples. Motivated by this, we propose to predict those hard-classified test samples in a looped manner to boost the model performance. However, this idea may pose a critical challenge: how to construct looped inference, so that the original erroneous predictions on these hard test samples can be corrected with little additional effort. To address this, we propose a general Closed-Loop Inference (CLI) method. Specifically, we first devise a filtering criterion to identify those hard-classified test samples that need additional inference loops. For each hard sample, we construct an additional auxiliary learning task based on its original top-$K$ predictions to calibrate the model, and then use the calibrated model to obtain the final prediction. Promising results on ImageNet (in-distribution test samples) and ImageNet-C (out-of-distribution test samples) demonstrate the effectiveness of CLI in improving the performance of any pre-trained model.
Graph Convolutional Module for Temporal Action Localization in Videos
Dec 01, 2021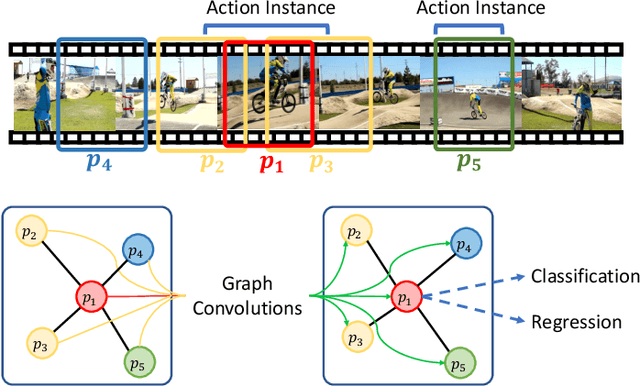
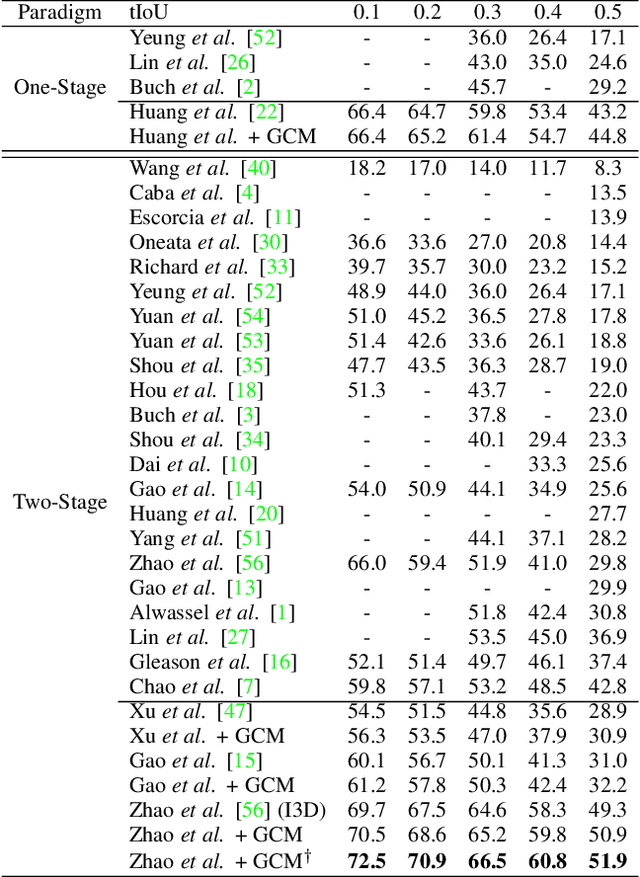
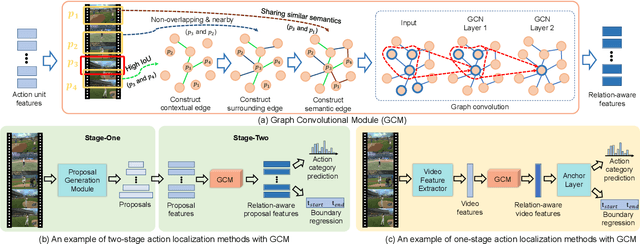
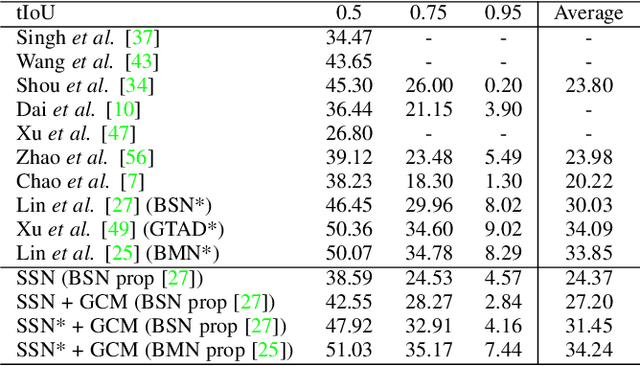
Temporal action localization has long been researched in computer vision. Existing state-of-the-art action localization methods divide each video into multiple action units (i.e., proposals in two-stage methods and segments in one-stage methods) and then perform action recognition/regression on each of them individually, without explicitly exploiting their relations during learning. In this paper, we claim that the relations between action units play an important role in action localization, and a more powerful action detector should not only capture the local content of each action unit but also allow a wider field of view on the context related to it. To this end, we propose a general graph convolutional module (GCM) that can be easily plugged into existing action localization methods, including two-stage and one-stage paradigms. To be specific, we first construct a graph, where each action unit is represented as a node and their relations between two action units as an edge. Here, we use two types of relations, one for capturing the temporal connections between different action units, and the other one for characterizing their semantic relationship. Particularly for the temporal connections in two-stage methods, we further explore two different kinds of edges, one connecting the overlapping action units and the other one connecting surrounding but disjointed units. Upon the graph we built, we then apply graph convolutional networks (GCNs) to model the relations among different action units, which is able to learn more informative representations to enhance action localization. Experimental results show that our GCM consistently improves the performance of existing action localization methods, including two-stage methods (e.g., CBR and R-C3D) and one-stage methods (e.g., D-SSAD), verifying the generality and effectiveness of our GCM.
V2C: Visual Voice Cloning
Nov 25, 2021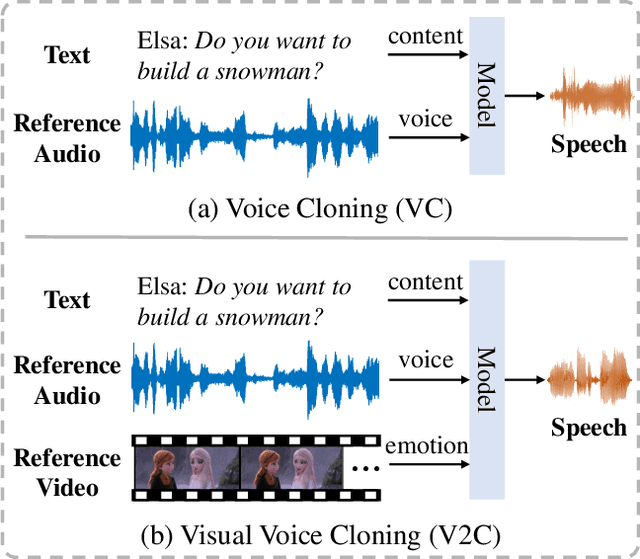
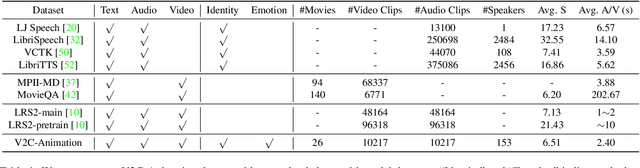

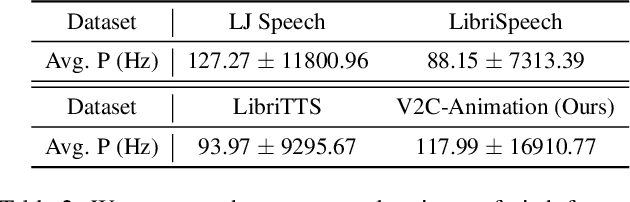
Existing Voice Cloning (VC) tasks aim to convert a paragraph text to a speech with desired voice specified by a reference audio. This has significantly boosted the development of artificial speech applications. However, there also exist many scenarios that cannot be well reflected by these VC tasks, such as movie dubbing, which requires the speech to be with emotions consistent with the movie plots. To fill this gap, in this work we propose a new task named Visual Voice Cloning (V2C), which seeks to convert a paragraph of text to a speech with both desired voice specified by a reference audio and desired emotion specified by a reference video. To facilitate research in this field, we construct a dataset, V2C-Animation, and propose a strong baseline based on existing state-of-the-art (SoTA) VC techniques. Our dataset contains 10,217 animated movie clips covering a large variety of genres (e.g., Comedy, Fantasy) and emotions (e.g., happy, sad). We further design a set of evaluation metrics, named MCD-DTW-SL, which help evaluate the similarity between ground-truth speeches and the synthesised ones. Extensive experimental results show that even SoTA VC methods cannot generate satisfying speeches for our V2C task. We hope the proposed new task together with the constructed dataset and evaluation metric will facilitate the research in the field of voice cloning and the broader vision-and-language community.
Instance Segmentation in 3D Scenes using Semantic Superpoint Tree Networks
Aug 17, 2021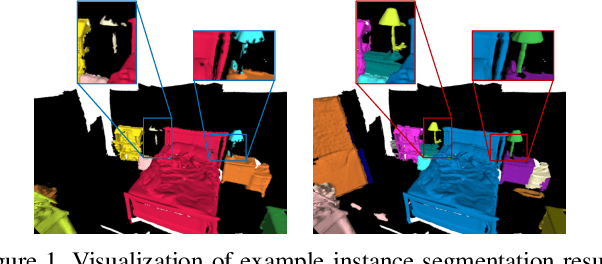

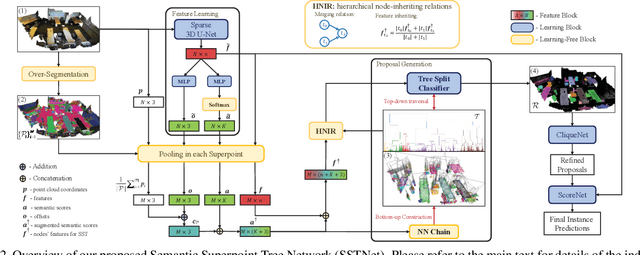
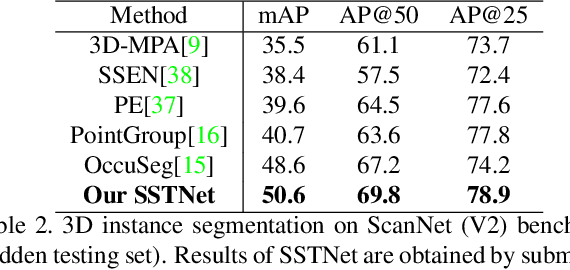
Instance segmentation in 3D scenes is fundamental in many applications of scene understanding. It is yet challenging due to the compound factors of data irregularity and uncertainty in the numbers of instances. State-of-the-art methods largely rely on a general pipeline that first learns point-wise features discriminative at semantic and instance levels, followed by a separate step of point grouping for proposing object instances. While promising, they have the shortcomings that (1) the second step is not supervised by the main objective of instance segmentation, and (2) their point-wise feature learning and grouping are less effective to deal with data irregularities, possibly resulting in fragmented segmentations. To address these issues, we propose in this work an end-to-end solution of Semantic Superpoint Tree Network (SSTNet) for proposing object instances from scene points. Key in SSTNet is an intermediate, semantic superpoint tree (SST), which is constructed based on the learned semantic features of superpoints, and which will be traversed and split at intermediate tree nodes for proposals of object instances. We also design in SSTNet a refinement module, termed CliqueNet, to prune superpoints that may be wrongly grouped into instance proposals. Experiments on the benchmarks of ScanNet and S3DIS show the efficacy of our proposed method. At the time of submission, SSTNet ranks top on the ScanNet (V2) leaderboard, with 2% higher of mAP than the second best method. The source code in PyTorch is available at https://github.com/Gorilla-Lab-SCUT/SSTNet.
Elastic Architecture Search for Diverse Tasks with Different Resources
Aug 03, 2021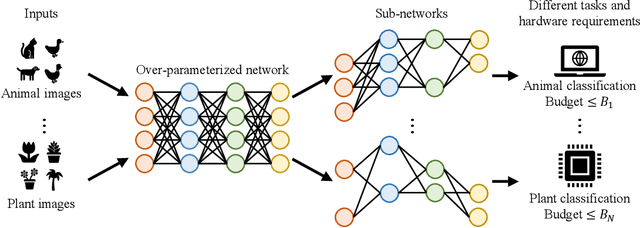
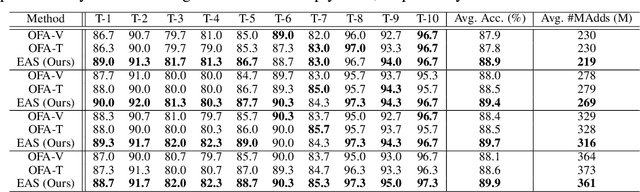
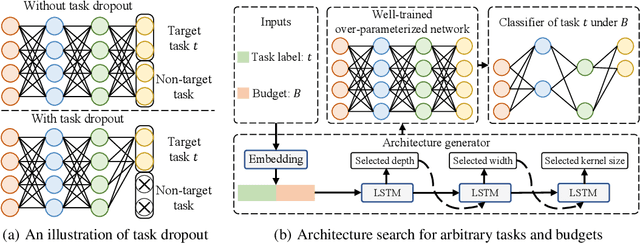
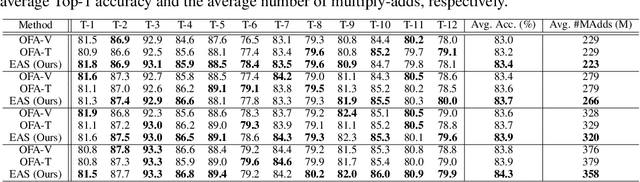
We study a new challenging problem of efficient deployment for diverse tasks with different resources, where the resource constraint and task of interest corresponding to a group of classes are dynamically specified at testing time. Previous NAS approaches seek to design architectures for all classes simultaneously, which may not be optimal for some individual tasks. A straightforward solution is to search an architecture from scratch for each deployment scenario, which however is computation-intensive and impractical. To address this, we present a novel and general framework, called Elastic Architecture Search (EAS), permitting instant specializations at runtime for diverse tasks with various resource constraints. To this end, we first propose to effectively train the over-parameterized network via a task dropout strategy to disentangle the tasks during training. In this way, the resulting model is robust to the subsequent task dropping at inference time. Based on the well-trained over-parameterized network, we then propose an efficient architecture generator to obtain optimal architectures within a single forward pass. Experiments on two image classification datasets show that EAS is able to find more compact networks with better performance while remarkably being orders of magnitude faster than state-of-the-art NAS methods. For example, our proposed EAS finds compact architectures within 0.1 second for 50 deployment scenarios.
Content-Aware Convolutional Neural Networks
Jul 23, 2021

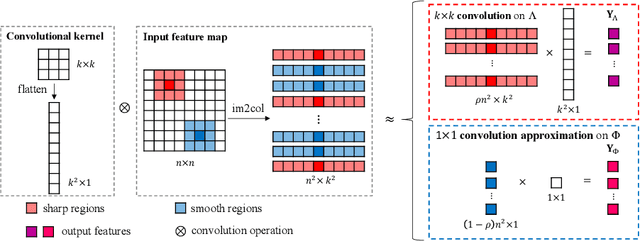
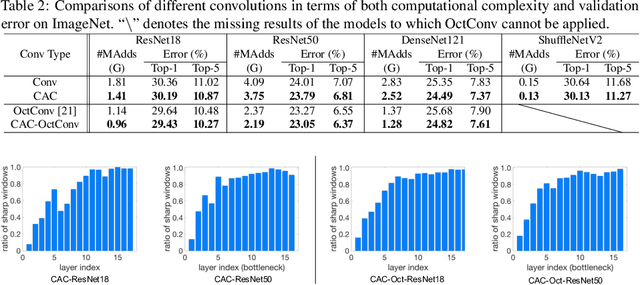
Convolutional Neural Networks (CNNs) have achieved great success due to the powerful feature learning ability of convolution layers. Specifically, the standard convolution traverses the input images/features using a sliding window scheme to extract features. However, not all the windows contribute equally to the prediction results of CNNs. In practice, the convolutional operation on some of the windows (e.g., smooth windows that contain very similar pixels) can be very redundant and may introduce noises into the computation. Such redundancy may not only deteriorate the performance but also incur the unnecessary computational cost. Thus, it is important to reduce the computational redundancy of convolution to improve the performance. To this end, we propose a Content-aware Convolution (CAC) that automatically detects the smooth windows and applies a 1x1 convolutional kernel to replace the original large kernel. In this sense, we are able to effectively avoid the redundant computation on similar pixels. By replacing the standard convolution in CNNs with our CAC, the resultant models yield significantly better performance and lower computational cost than the baseline models with the standard convolution. More critically, we are able to dynamically allocate suitable computation resources according to the data smoothness of different images, making it possible for content-aware computation. Extensive experiments on various computer vision tasks demonstrate the superiority of our method over existing methods.
AdaXpert: Adapting Neural Architecture for Growing Data
Jul 01, 2021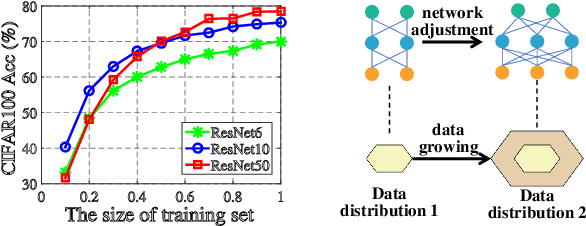
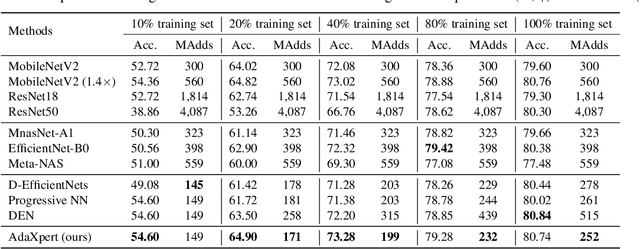
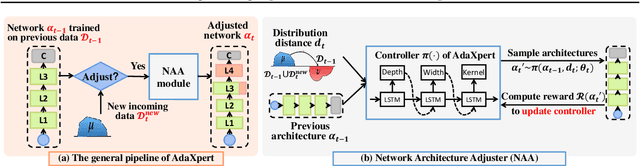
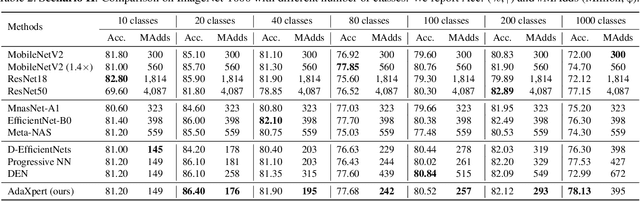
In real-world applications, data often come in a growing manner, where the data volume and the number of classes may increase dynamically. This will bring a critical challenge for learning: given the increasing data volume or the number of classes, one has to instantaneously adjust the neural model capacity to obtain promising performance. Existing methods either ignore the growing nature of data or seek to independently search an optimal architecture for a given dataset, and thus are incapable of promptly adjusting the architectures for the changed data. To address this, we present a neural architecture adaptation method, namely Adaptation eXpert (AdaXpert), to efficiently adjust previous architectures on the growing data. Specifically, we introduce an architecture adjuster to generate a suitable architecture for each data snapshot, based on the previous architecture and the different extent between current and previous data distributions. Furthermore, we propose an adaptation condition to determine the necessity of adjustment, thereby avoiding unnecessary and time-consuming adjustments. Extensive experiments on two growth scenarios (increasing data volume and number of classes) demonstrate the effectiveness of the proposed method.
Perception-aware Multi-sensor Fusion for 3D LiDAR Semantic Segmentation
Jun 21, 2021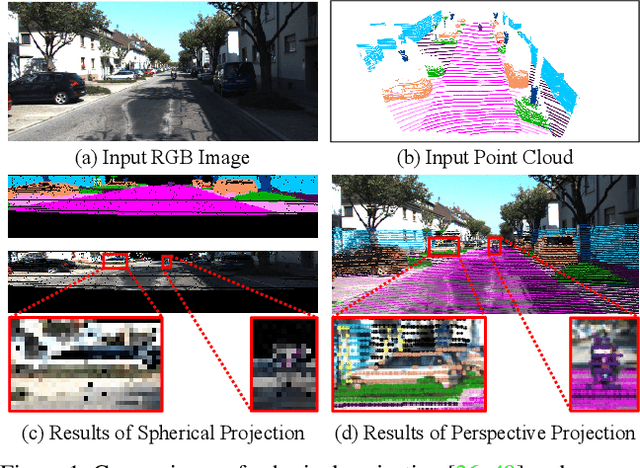
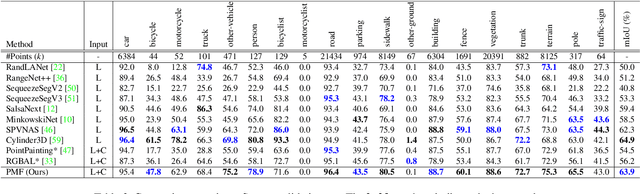
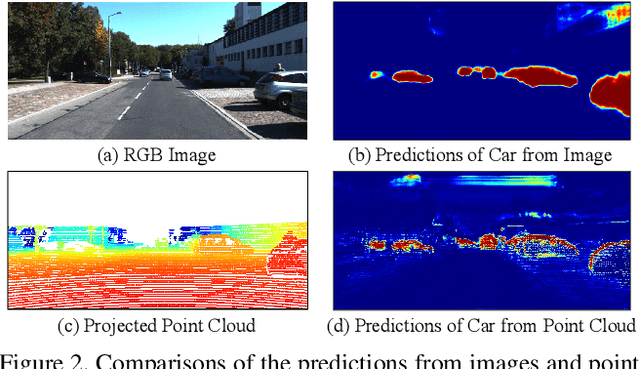
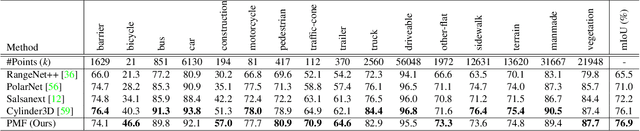
3D LiDAR (light detection and ranging) based semantic segmentation is important in scene understanding for many applications, such as auto-driving and robotics. For example, for autonomous cars equipped with RGB cameras and LiDAR, it is crucial to fuse complementary information from different sensors for robust and accurate segmentation. Existing fusion-based methods, however, may not achieve promising performance due to the vast difference between two modalities. In this work, we investigate a collaborative fusion scheme called perception-aware multi-sensor fusion (PMF) to exploit perceptual information from two modalities, namely, appearance information from RGB images and spatio-depth information from point clouds. To this end, we first project point clouds to the camera coordinates to provide spatio-depth information for RGB images. Then, we propose a two-stream network to extract features from the two modalities, separately, and fuse the features by effective residual-based fusion modules. Moreover, we propose additional perception-aware losses to measure the great perceptual difference between the two modalities. Extensive experiments on two benchmark data sets show the superiority of our method. For example, on nuScenes, our PMF outperforms the state-of-the-art method by 0.8% in mIoU.
Source-free Domain Adaptation via Avatar Prototype Generation and Adaptation
Jun 18, 2021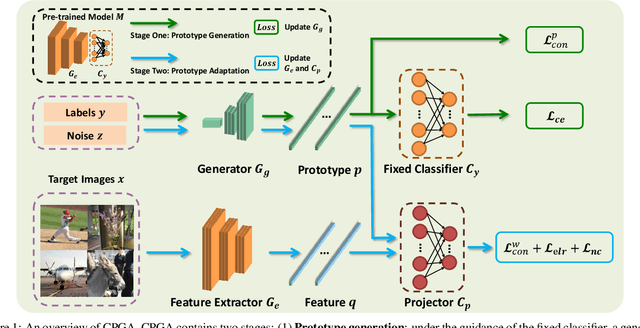
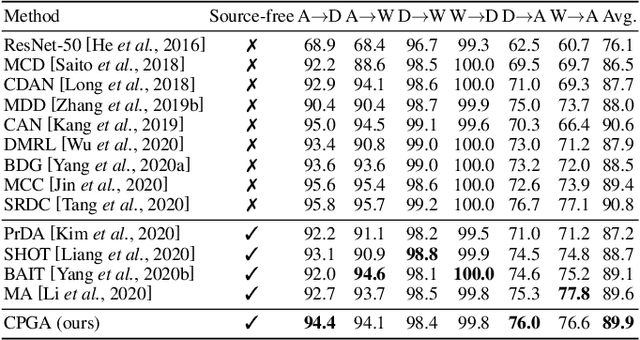
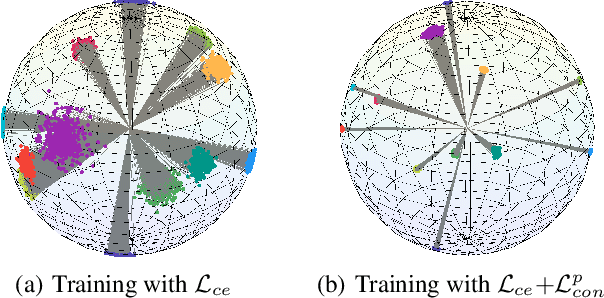
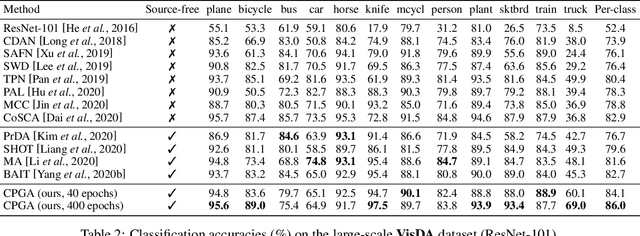
We study a practical domain adaptation task, called source-free unsupervised domain adaptation (UDA) problem, in which we cannot access source domain data due to data privacy issues but only a pre-trained source model and unlabeled target data are available. This task, however, is very difficult due to one key challenge: the lack of source data and target domain labels makes model adaptation very challenging. To address this, we propose to mine the hidden knowledge in the source model and exploit it to generate source avatar prototypes (i.e., representative features for each source class) as well as target pseudo labels for domain alignment. To this end, we propose a Contrastive Prototype Generation and Adaptation (CPGA) method. Specifically, CPGA consists of two stages: (1) prototype generation: by exploring the classification boundary information of the source model, we train a prototype generator to generate avatar prototypes via contrastive learning. (2) prototype adaptation: based on the generated source prototypes and target pseudo labels, we develop a new robust contrastive prototype adaptation strategy to align each pseudo-labeled target data to the corresponding source prototypes. Extensive experiments on three UDA benchmark datasets demonstrate the effectiveness and superiority of the proposed method.