 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTSPO: Breaking the Double Homogenization Dilemma in Multi-turn Search Policy Optimization
Jan 30, 2026Multi-turn tool-integrated reasoning enables Large Language Models (LLMs) to solve complex tasks through iterative information retrieval. However, current reinforcement learning (RL) frameworks for search-augmented reasoning predominantly rely on sparse outcome-level rewards, leading to a "Double Homogenization Dilemma." This manifests as (1) Process homogenization, where the thinking, reasoning, and tooling involved in generation are ignored. (2) Intra-group homogenization, coarse-grained outcome rewards often lead to inefficiencies in intra-group advantage estimation with methods like Group Relative Policy Optimization (GRPO) during sampling. To address this, we propose Turn-level Stage-aware Policy Optimization (TSPO). TSPO introduces the First-Occurrence Latent Reward (FOLR) mechanism, allocating partial rewards to the step where the ground-truth answer first appears, thereby preserving process-level signals and increasing reward variance within groups without requiring external reward models or any annotations. Extensive experiments demonstrate that TSPO significantly outperforms state-of-the-art baselines, achieving average performance gains of 24% and 13.6% on Qwen2.5-3B and 7B models, respectively.
Learning Diffusion Policy from Primitive Skills for Robot Manipulation
Jan 05, 2026Diffusion policies (DP) have recently shown great promise for generating actions in robotic manipulation. However, existing approaches often rely on global instructions to produce short-term control signals, which can result in misalignment in action generation. We conjecture that the primitive skills, referred to as fine-grained, short-horizon manipulations, such as ``move up'' and ``open the gripper'', provide a more intuitive and effective interface for robot learning. To bridge this gap, we propose SDP, a skill-conditioned DP that integrates interpretable skill learning with conditional action planning. SDP abstracts eight reusable primitive skills across tasks and employs a vision-language model to extract discrete representations from visual observations and language instructions. Based on them, a lightweight router network is designed to assign a desired primitive skill for each state, which helps construct a single-skill policy to generate skill-aligned actions. By decomposing complex tasks into a sequence of primitive skills and selecting a single-skill policy, SDP ensures skill-consistent behavior across diverse tasks. Extensive experiments on two challenging simulation benchmarks and real-world robot deployments demonstrate that SDP consistently outperforms SOTA methods, providing a new paradigm for skill-based robot learning with diffusion policies.
FedeCouple: Fine-Grained Balancing of Global-Generalization and Local-Adaptability in Federated Learning
Nov 12, 2025



In privacy-preserving mobile network transmission scenarios with heterogeneous client data, personalized federated learning methods that decouple feature extractors and classifiers have demonstrated notable advantages in enhancing learning capability. However, many existing approaches primarily focus on feature space consistency and classification personalization during local training, often neglecting the local adaptability of the extractor and the global generalization of the classifier. This oversight results in insufficient coordination and weak coupling between the components, ultimately degrading the overall model performance. To address this challenge, we propose FedeCouple, a federated learning method that balances global generalization and local adaptability at a fine-grained level. Our approach jointly learns global and local feature representations while employing dynamic knowledge distillation to enhance the generalization of personalized classifiers. We further introduce anchors to refine the feature space; their strict locality and non-transmission inherently preserve privacy and reduce communication overhead. Furthermore, we provide a theoretical analysis proving that FedeCouple converges for nonconvex objectives, with iterates approaching a stationary point as the number of communication rounds increases. Extensive experiments conducted on five image-classification datasets demonstrate that FedeCouple consistently outperforms nine baseline methods in effectiveness, stability, scalability, and security. Notably, in experiments evaluating effectiveness, FedeCouple surpasses the best baseline by a significant margin of 4.3%.
A Remarkably Efficient Paradigm to Multimodal Large Language Models for Sequential Recommendation
Nov 11, 2025

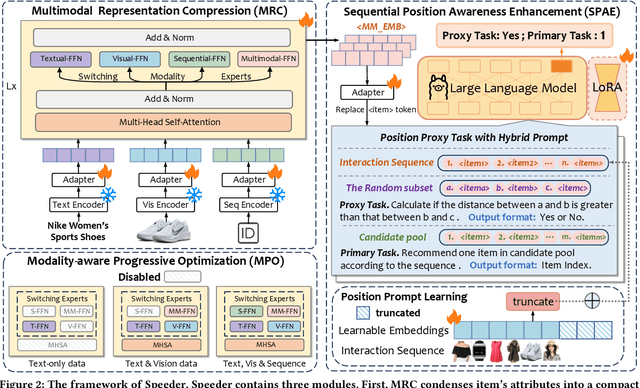
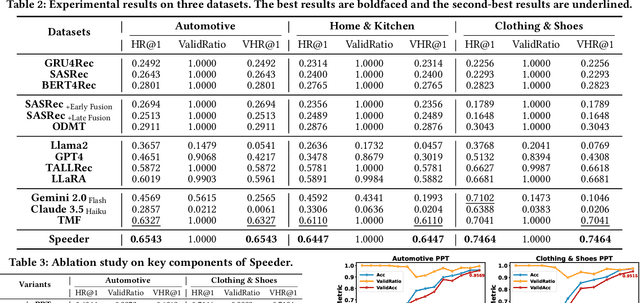
Sequential recommendations (SR) predict users' future interactions based on their historical behavior. The rise of Large Language Models (LLMs) has brought powerful generative and reasoning capabilities, significantly enhancing SR performance, while Multimodal LLMs (MLLMs) further extend this by introducing data like images and interactive relationships. However, critical issues remain, i.e., (a) Suboptimal item representations caused by lengthy and redundant descriptions, leading to inefficiencies in both training and inference; (b) Modality-related cognitive bias, as LLMs are predominantly pretrained on textual data, limiting their ability to effectively integrate and utilize non-textual modalities; (c) Weakening sequential perception in long interaction sequences, where attention mechanisms struggle to capture earlier interactions, hindering the modeling of long-range dependencies. To address these issues, we propose Speeder, an efficient MLLM-based paradigm for SR featuring three key innovations: 1) Multimodal Representation Compression (MRC), which condenses item attributes into concise yet informative tokens, reducing redundancy and computational cost; 2) Modality-aware Progressive Optimization (MPO), enabling gradual learning of multimodal representations; 3) Sequential Position Awareness Enhancement (SPAE), improving the LLM's capability to capture both relative and absolute sequential dependencies in long interaction sequences. Extensive experiments on real-world datasets demonstrate the effectiveness and efficiency of Speeder. Speeder increases training speed to 250% of the original while reducing inference time to 25% on the Amazon dataset.
Bench-RNR: Dataset for Benchmarking Repetitive and Non-repetitive Scanning LiDAR for Infrastructure-based Vehicle Localization
Sep 19, 2025



Vehicle localization using roadside LiDARs can provide centimeter-level accuracy for cloud-controlled vehicles while simultaneously serving multiple vehicles, enhanc-ing safety and efficiency. While most existing studies rely on repetitive scanning LiDARs, non-repetitive scanning LiDAR offers advantages such as eliminating blind zones and being more cost-effective. However, its application in roadside perception and localization remains limited. To address this, we present a dataset for infrastructure-based vehicle localization, with data collected from both repetitive and non-repetitive scanning LiDARs, in order to benchmark the performance of different LiDAR scanning patterns. The dataset contains 5,445 frames of point clouds across eight vehicle trajectory sequences, with diverse trajectory types. Our experiments establish base-lines for infrastructure-based vehicle localization and compare the performance of these methods using both non-repetitive and repetitive scanning LiDARs. This work offers valuable insights for selecting the most suitable LiDAR scanning pattern for infrastruc-ture-based vehicle localization. Our dataset is a signifi-cant contribution to the scientific community, supporting advancements in infrastructure-based perception and vehicle localization. The dataset and source code are publicly available at: https://github.com/sjtu-cyberc3/BenchRNR.
Choice Outweighs Effort: Facilitating Complementary Knowledge Fusion in Federated Learning via Re-calibration and Merit-discrimination
Aug 25, 2025



Cross-client data heterogeneity in federated learning induces biases that impede unbiased consensus condensation and the complementary fusion of generalization- and personalization-oriented knowledge. While existing approaches mitigate heterogeneity through model decoupling and representation center loss, they often rely on static and restricted metrics to evaluate local knowledge and adopt global alignment too rigidly, leading to consensus distortion and diminished model adaptability. To address these limitations, we propose FedMate, a method that implements bilateral optimization: On the server side, we construct a dynamic global prototype, with aggregation weights calibrated by holistic integration of sample size, current parameters, and future prediction; a category-wise classifier is then fine-tuned using this prototype to preserve global consistency. On the client side, we introduce complementary classification fusion to enable merit-based discrimination training and incorporate cost-aware feature transmission to balance model performance and communication efficiency. Experiments on five datasets of varying complexity demonstrate that FedMate outperforms state-of-the-art methods in harmonizing generalization and adaptation. Additionally, semantic segmentation experiments on autonomous driving datasets validate the method's real-world scalability.
CasP: Improving Semi-Dense Feature Matching Pipeline Leveraging Cascaded Correspondence Priors for Guidance
Jul 23, 2025Semi-dense feature matching methods have shown strong performance in challenging scenarios. However, the existing pipeline relies on a global search across the entire feature map to establish coarse matches, limiting further improvements in accuracy and efficiency. Motivated by this limitation, we propose a novel pipeline, CasP, which leverages cascaded correspondence priors for guidance. Specifically, the matching stage is decomposed into two progressive phases, bridged by a region-based selective cross-attention mechanism designed to enhance feature discriminability. In the second phase, one-to-one matches are determined by restricting the search range to the one-to-many prior areas identified in the first phase. Additionally, this pipeline benefits from incorporating high-level features, which helps reduce the computational costs of low-level feature extraction. The acceleration gains of CasP increase with higher resolution, and our lite model achieves a speedup of $\sim2.2\times$ at a resolution of 1152 compared to the most efficient method, ELoFTR. Furthermore, extensive experiments demonstrate its superiority in geometric estimation, particularly with impressive cross-domain generalization. These advantages highlight its potential for latency-sensitive and high-robustness applications, such as SLAM and UAV systems. Code is available at https://github.com/pq-chen/CasP.
From Experts to a Generalist: Toward General Whole-Body Control for Humanoid Robots
Jun 15, 2025Achieving general agile whole-body control on humanoid robots remains a major challenge due to diverse motion demands and data conflicts. While existing frameworks excel in training single motion-specific policies, they struggle to generalize across highly varied behaviors due to conflicting control requirements and mismatched data distributions. In this work, we propose BumbleBee (BB), an expert-generalist learning framework that combines motion clustering and sim-to-real adaptation to overcome these challenges. BB first leverages an autoencoder-based clustering method to group behaviorally similar motions using motion features and motion descriptions. Expert policies are then trained within each cluster and refined with real-world data through iterative delta action modeling to bridge the sim-to-real gap. Finally, these experts are distilled into a unified generalist controller that preserves agility and robustness across all motion types. Experiments on two simulations and a real humanoid robot demonstrate that BB achieves state-of-the-art general whole-body control, setting a new benchmark for agile, robust, and generalizable humanoid performance in the real world.
Active-O3: Empowering Multimodal Large Language Models with Active Perception via GRPO
May 27, 2025Active vision, also known as active perception, refers to the process of actively selecting where and how to look in order to gather task-relevant information. It is a critical component of efficient perception and decision-making in humans and advanced embodied agents. Recently, the use of Multimodal Large Language Models (MLLMs) as central planning and decision-making modules in robotic systems has gained extensive attention. However, despite the importance of active perception in embodied intelligence, there is little to no exploration of how MLLMs can be equipped with or learn active perception capabilities. In this paper, we first provide a systematic definition of MLLM-based active perception tasks. We point out that the recently proposed GPT-o3 model's zoom-in search strategy can be regarded as a special case of active perception; however, it still suffers from low search efficiency and inaccurate region selection. To address these issues, we propose ACTIVE-O3, a purely reinforcement learning based training framework built on top of GRPO, designed to equip MLLMs with active perception capabilities. We further establish a comprehensive benchmark suite to evaluate ACTIVE-O3 across both general open-world tasks, such as small-object and dense object grounding, and domain-specific scenarios, including small object detection in remote sensing and autonomous driving, as well as fine-grained interactive segmentation. In addition, ACTIVE-O3 also demonstrates strong zero-shot reasoning abilities on the V* Benchmark, without relying on any explicit reasoning data. We hope that our work can provide a simple codebase and evaluation protocol to facilitate future research on active perception in MLLMs.
Weather-Magician: Reconstruction and Rendering Framework for 4D Weather Synthesis In Real Time
May 26, 2025For tasks such as urban digital twins, VR/AR/game scene design, or creating synthetic films, the traditional industrial approach often involves manually modeling scenes and using various rendering engines to complete the rendering process. This approach typically requires high labor costs and hardware demands, and can result in poor quality when replicating complex real-world scenes. A more efficient approach is to use data from captured real-world scenes, then apply reconstruction and rendering algorithms to quickly recreate the authentic scene. However, current algorithms are unable to effectively reconstruct and render real-world weather effects. To address this, we propose a framework based on gaussian splatting, that can reconstruct real scenes and render them under synthesized 4D weather effects. Our work can simulate various common weather effects by applying Gaussians modeling and rendering techniques. It supports continuous dynamic weather changes and can easily control the details of the effects. Additionally, our work has low hardware requirements and achieves real-time rendering performance. The result demos can be accessed on our project homepage: weathermagician.github.io