 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccurate Prior-centric Monocular Positioning with Offline LiDAR Fusion
Jul 12, 2024Unmanned vehicles usually rely on Global Positioning System (GPS) and Light Detection and Ranging (LiDAR) sensors to achieve high-precision localization results for navigation purpose. However, this combination with their associated costs and infrastructure demands, poses challenges for widespread adoption in mass-market applications. In this paper, we aim to use only a monocular camera to achieve comparable onboard localization performance by tracking deep-learning visual features on a LiDAR-enhanced visual prior map. Experiments show that the proposed algorithm can provide centimeter-level global positioning results with scale, which is effortlessly integrated and favorable for low-cost robot system deployment in real-world applications.
GraCoRe: Benchmarking Graph Comprehension and Complex Reasoning in Large Language Models
Jul 03, 2024Evaluating the graph comprehension and reasoning abilities of Large Language Models (LLMs) is challenging and often incomplete. Existing benchmarks focus primarily on pure graph understanding, lacking a comprehensive evaluation across all graph types and detailed capability definitions. This paper presents GraCoRe, a benchmark for systematically assessing LLMs' graph comprehension and reasoning. GraCoRe uses a three-tier hierarchical taxonomy to categorize and test models on pure graph and heterogeneous graphs, subdividing capabilities into 10 distinct areas tested through 19 tasks. Our benchmark includes 11 datasets with 5,140 graphs of varying complexity. We evaluated three closed-source and seven open-source LLMs, conducting thorough analyses from both ability and task perspectives. Key findings reveal that semantic enrichment enhances reasoning performance, node ordering impacts task success, and the ability to process longer texts does not necessarily improve graph comprehension or reasoning. GraCoRe is open-sourced at https://github.com/ZIKEYUAN/GraCoRe
BeamAggR: Beam Aggregation Reasoning over Multi-source Knowledge for Multi-hop Question Answering
Jun 28, 2024



Large language models (LLMs) have demonstrated strong reasoning capabilities. Nevertheless, they still suffer from factual errors when tackling knowledge-intensive tasks. Retrieval-augmented reasoning represents a promising approach. However, significant challenges still persist, including inaccurate and insufficient retrieval for complex questions, as well as difficulty in integrating multi-source knowledge. To address this, we propose Beam Aggregation Reasoning, BeamAggR, a reasoning framework for knowledge-intensive multi-hop QA. BeamAggR explores and prioritizes promising answers at each hop of question. Concretely, we parse the complex questions into trees, which include atom and composite questions, followed by bottom-up reasoning. For atomic questions, the LLM conducts reasoning on multi-source knowledge to get answer candidates. For composite questions, the LLM combines beam candidates, explores multiple reasoning paths through probabilistic aggregation, and prioritizes the most promising trajectory. Extensive experiments on four open-domain multi-hop reasoning datasets show that our method significantly outperforms SOTA methods by 8.5%. Furthermore, our analysis reveals that BeamAggR elicits better knowledge collaboration and answer aggregation.
GUIDE: A Guideline-Guided Dataset for Instructional Video Comprehension
Jun 26, 2024



There are substantial instructional videos on the Internet, which provide us tutorials for completing various tasks. Existing instructional video datasets only focus on specific steps at the video level, lacking experiential guidelines at the task level, which can lead to beginners struggling to learn new tasks due to the lack of relevant experience. Moreover, the specific steps without guidelines are trivial and unsystematic, making it difficult to provide a clear tutorial. To address these problems, we present the GUIDE (Guideline-Guided) dataset, which contains 3.5K videos of 560 instructional tasks in 8 domains related to our daily life. Specifically, we annotate each instructional task with a guideline, representing a common pattern shared by all task-related videos. On this basis, we annotate systematic specific steps, including their associated guideline steps, specific step descriptions and timestamps. Our proposed benchmark consists of three sub-tasks to evaluate comprehension ability of models: (1) Step Captioning: models have to generate captions for specific steps from videos. (2) Guideline Summarization: models have to mine the common pattern in task-related videos and summarize a guideline from them. (3) Guideline-Guided Captioning: models have to generate captions for specific steps under the guide of guideline. We evaluate plenty of foundation models with GUIDE and perform in-depth analysis. Given the diversity and practicality of GUIDE, we believe that it can be used as a better benchmark for instructional video comprehension.
Continuous-Time Digital Twin with Analogue Memristive Neural Ordinary Differential Equation Solver
Jun 12, 2024Digital twins, the cornerstone of Industry 4.0, replicate real-world entities through computer models, revolutionising fields such as manufacturing management and industrial automation. Recent advances in machine learning provide data-driven methods for developing digital twins using discrete-time data and finite-depth models on digital computers. However, this approach fails to capture the underlying continuous dynamics and struggles with modelling complex system behaviour. Additionally, the architecture of digital computers, with separate storage and processing units, necessitates frequent data transfers and Analogue-Digital (A/D) conversion, thereby significantly increasing both time and energy costs. Here, we introduce a memristive neural ordinary differential equation (ODE) solver for digital twins, which is capable of capturing continuous-time dynamics and facilitates the modelling of complex systems using an infinite-depth model. By integrating storage and computation within analogue memristor arrays, we circumvent the von Neumann bottleneck, thus enhancing both speed and energy efficiency. We experimentally validate our approach by developing a digital twin of the HP memristor, which accurately extrapolates its nonlinear dynamics, achieving a 4.2-fold projected speedup and a 41.4-fold projected decrease in energy consumption compared to state-of-the-art digital hardware, while maintaining an acceptable error margin. Additionally, we demonstrate scalability through experimentally grounded simulations of Lorenz96 dynamics, exhibiting projected performance improvements of 12.6-fold in speed and 189.7-fold in energy efficiency relative to traditional digital approaches. By harnessing the capabilities of fully analogue computing, our breakthrough accelerates the development of digital twins, offering an efficient and rapid solution to meet the demands of Industry 4.0.
GLAD: Towards Better Reconstruction with Global and Local Adaptive Diffusion Models for Unsupervised Anomaly Detection
Jun 11, 2024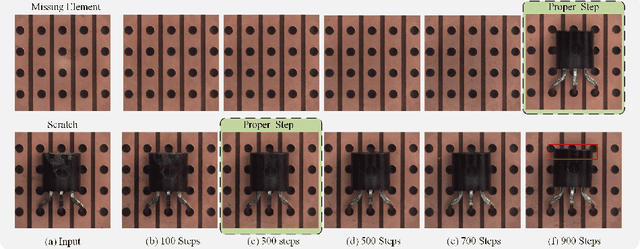
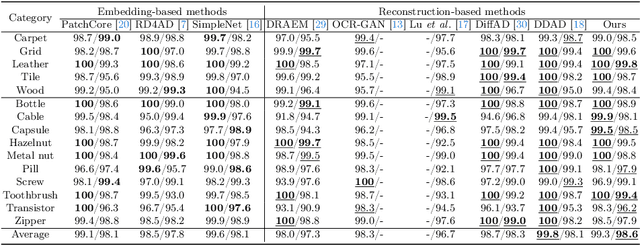

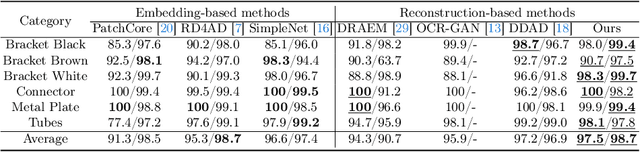
Diffusion models have shown superior performance on unsupervised anomaly detection tasks. Since trained with normal data only, diffusion models tend to reconstruct normal counterparts of test images with certain noises added. However, these methods treat all potential anomalies equally, which may cause two main problems. From the global perspective, the difficulty of reconstructing images with different anomalies is uneven. Therefore, instead of utilizing the same setting for all samples, we propose to predict a particular denoising step for each sample by evaluating the difference between image contents and the priors extracted from diffusion models. From the local perspective, reconstructing abnormal regions differs from normal areas even in the same image. Theoretically, the diffusion model predicts a noise for each step, typically following a standard Gaussian distribution. However, due to the difference between the anomaly and its potential normal counterpart, the predicted noise in abnormal regions will inevitably deviate from the standard Gaussian distribution. To this end, we propose introducing synthetic abnormal samples in training to encourage the diffusion models to break through the limitation of standard Gaussian distribution, and a spatial-adaptive feature fusion scheme is utilized during inference. With the above modifications, we propose a global and local adaptive diffusion model (abbreviated to GLAD) for unsupervised anomaly detection, which introduces appealing flexibility and achieves anomaly-free reconstruction while retaining as much normal information as possible. Extensive experiments are conducted on three commonly used anomaly detection datasets (MVTec-AD, MPDD, and VisA) and a printed circuit board dataset (PCB-Bank) we integrated, showing the effectiveness of the proposed method.
Planning Like Human: A Dual-process Framework for Dialogue Planning
Jun 08, 2024



In proactive dialogue, the challenge lies not just in generating responses but in steering conversations toward predetermined goals, a task where Large Language Models (LLMs) typically struggle due to their reactive nature. Traditional approaches to enhance dialogue planning in LLMs, ranging from elaborate prompt engineering to the integration of policy networks, either face efficiency issues or deliver suboptimal performance. Inspired by the dualprocess theory in psychology, which identifies two distinct modes of thinking - intuitive (fast) and analytical (slow), we propose the Dual-Process Dialogue Planning (DPDP) framework. DPDP embodies this theory through two complementary planning systems: an instinctive policy model for familiar contexts and a deliberative Monte Carlo Tree Search (MCTS) mechanism for complex, novel scenarios. This dual strategy is further coupled with a novel two-stage training regimen: offline Reinforcement Learning for robust initial policy model formation followed by MCTS-enhanced on-the-fly learning, which ensures a dynamic balance between efficiency and strategic depth. Our empirical evaluations across diverse dialogue tasks affirm DPDP's superiority in achieving both high-quality dialogues and operational efficiency, outpacing existing methods.
RiskMap: A Unified Driving Context Representation for Autonomous Motion Planning in Urban Driving Environment
Jun 06, 2024Planning is complicated by the combination of perception and map information, particularly when driving in heavy traffic. Developing an extendable and efficient representation that visualizes sensor noise and provides constraints to real-time planning tasks is desirable. We aim to develop an extendable map representation offering prior to cost in planning tasks to simplify the planning process of dealing with complex driving scenarios and visualize sensor noise. In this paper, we illustrate a unified context representation empowered by a modern deep learning motion prediction model, representing statistical cognition of motion prediction for human beings. A sampling-based planner is adopted to train and compare the difference in risk map generation methods. The training tools and model structures are investigated illustrating their efficiency in this task.
Effective Interplay between Sparsity and Quantization: From Theory to Practice
May 31, 2024



The increasing size of deep neural networks necessitates effective model compression to improve computational efficiency and reduce their memory footprint. Sparsity and quantization are two prominent compression methods that have individually demonstrated significant reduction in computational and memory footprints while preserving model accuracy. While effective, the interplay between these two methods remains an open question. In this paper, we investigate the interaction between these two methods and assess whether their combination impacts final model accuracy. We mathematically prove that applying sparsity before quantization is the optimal sequence for these operations, minimizing error in computation. Our empirical studies across a wide range of models, including OPT and Llama model families (125M-8B) and ViT corroborate these theoretical findings. In addition, through rigorous analysis, we demonstrate that sparsity and quantization are not orthogonal; their interaction can significantly harm model accuracy, with quantization error playing a dominant role in this degradation. Our findings extend to the efficient deployment of large models in resource-limited compute platforms and reduce serving cost, offering insights into best practices for applying these compression methods to maximize efficacy without compromising accuracy.
Two Optimizers Are Better Than One: LLM Catalyst for Enhancing Gradient-Based Optimization
May 31, 2024



Learning a skill generally relies on both practical experience by doer and insightful high-level guidance by instructor. Will this strategy also work well for solving complex non-convex optimization problems? Here, a common gradient-based optimizer acts like a disciplined doer, making locally optimal update at each step. Recent methods utilize large language models (LLMs) to optimize solutions for concrete problems by inferring from natural language instructions, akin to a high-level instructor. In this paper, we show that these two optimizers are complementary to each other, suggesting a collaborative optimization approach. The gradient-based optimizer and LLM-based optimizer are combined in an interleaved manner. We instruct LLMs using task descriptions and timely optimization trajectories recorded during gradient-based optimization. Inferred results from LLMs are used as restarting points for the next stage of gradient optimization. By leveraging both the locally rigorous gradient-based optimizer and the high-level deductive LLM-based optimizer, our combined optimization method consistently yields improvements over competitive baseline prompt tuning methods. Our results demonstrate the synergistic effect of conventional gradient-based optimization and the inference ability of LLMs. The code is released at https://github.com/guozix/LLM-catalyst.