 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition: Academic Conferences are Potentially Facing Denominator Gaming Caused by Fully Automated Scientific Agents
May 11, 2026The implicit policy of maintaining relatively stable acceptance rates at top AI conferences, despite exponentially growing submissions, introduces a critical structural vulnerability. This position paper characterizes a new systemic threat we term Agentic Denominator Gaming, in which a malicious actor deploys AI agents to generate and submit a large volume of superficially plausible but low-quality papers. Crucially, their objective is not the acceptance of low-quality papers, but rather to inflate the submission denominator and overwhelm reviewing capacity. Under a relatively stable acceptance rate, this dilution can systematically increase the publication probability of a small, targeted set of legitimate papers. We analyze the practical feasibility of this threat and its broader consequences, including intensified reviewer burnout, degraded review quality, and the emergence of industrialized automated agent mills. Finally, we propose and evaluate a range of mitigation strategies, and argue that durable protection will require system-level policy and incentive reforms, rather than relying primarily on technical detection alone.
SkillMAS: Skill Co-Evolution with LLM-based Multi-Agent System
May 10, 2026Large language model (LLM) agent systems are increasingly expected to improve after deployment, but existing work often decouples two adaptation targets: skill evolution and multi-agent system (MAS) restructuring. This separation can create organization bottlenecks, context pressure, and mis-specialization. We present SkillMAS, a non-parametric framework for adaptive specialization in multi-agent systems that couples skill evolution with MAS restructuring. SkillMAS uses Utility Learning to assign credit from verified execution traces, bounded skill evolution to refine reusable procedures without unfiltered library growth, and evidence-gated MAS restructuring when retained failures and Executor Utility indicate a structural mismatch. Across embodied manipulation, command-line execution, and retail workflows, SkillMAS is competitive under the reported harnesses while clarifying how post-deployment specialization is attributed, updated, and applied.
Dynamic Residual Encoding with Slide-Level Contrastive Learning for End-to-End Whole Slide Image Representation
Nov 07, 2025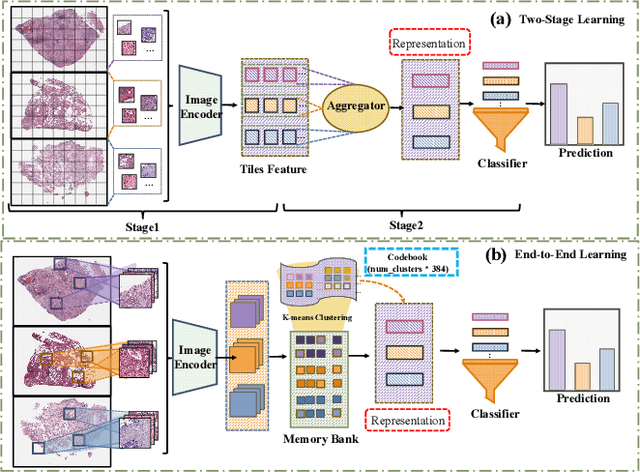

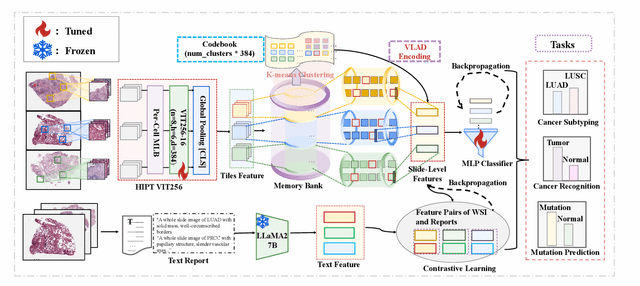
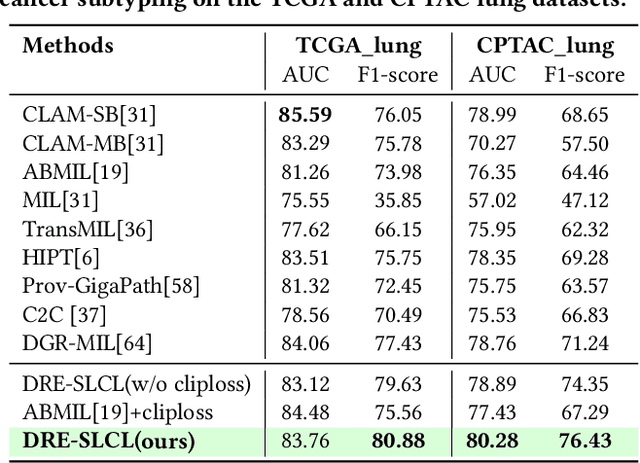
Whole Slide Image (WSI) representation is critical for cancer subtyping, cancer recognition and mutation prediction.Training an end-to-end WSI representation model poses significant challenges, as a standard gigapixel slide can contain tens of thousands of image tiles, making it difficult to compute gradients of all tiles in a single mini-batch due to current GPU limitations. To address this challenge, we propose a method of dynamic residual encoding with slide-level contrastive learning (DRE-SLCL) for end-to-end WSI representation. Our approach utilizes a memory bank to store the features of tiles across all WSIs in the dataset. During training, a mini-batch usually contains multiple WSIs. For each WSI in the batch, a subset of tiles is randomly sampled and their features are computed using a tile encoder. Then, additional tile features from the same WSI are selected from the memory bank. The representation of each individual WSI is generated using a residual encoding technique that incorporates both the sampled features and those retrieved from the memory bank. Finally, the slide-level contrastive loss is computed based on the representations and histopathology reports ofthe WSIs within the mini-batch. Experiments conducted over cancer subtyping, cancer recognition, and mutation prediction tasks proved the effectiveness of the proposed DRE-SLCL method.
* 8pages, 3figures, published to ACM Digital Library
Towards Reasoning Era: A Survey of Long Chain-of-Thought for Reasoning Large Language Models
Mar 13, 2025Recent advancements in reasoning with large language models (RLLMs), such as OpenAI-O1 and DeepSeek-R1, have demonstrated their impressive capabilities in complex domains like mathematics and coding. A central factor in their success lies in the application of long chain-of-thought (Long CoT) characteristics, which enhance reasoning abilities and enable the solution of intricate problems. However, despite these developments, a comprehensive survey on Long CoT is still lacking, limiting our understanding of its distinctions from traditional short chain-of-thought (Short CoT) and complicating ongoing debates on issues like "overthinking" and "test-time scaling." This survey seeks to fill this gap by offering a unified perspective on Long CoT. (1) We first distinguish Long CoT from Short CoT and introduce a novel taxonomy to categorize current reasoning paradigms. (2) Next, we explore the key characteristics of Long CoT: deep reasoning, extensive exploration, and feasible reflection, which enable models to handle more complex tasks and produce more efficient, coherent outcomes compared to the shallower Short CoT. (3) We then investigate key phenomena such as the emergence of Long CoT with these characteristics, including overthinking, and test-time scaling, offering insights into how these processes manifest in practice. (4) Finally, we identify significant research gaps and highlight promising future directions, including the integration of multi-modal reasoning, efficiency improvements, and enhanced knowledge frameworks. By providing a structured overview, this survey aims to inspire future research and further the development of logical reasoning in artificial intelligence.