 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Covariate Selection for Average Causal Effect Estimation without Pretreatment and Causal Sufficiency Assumptions
May 20, 2026We study the problem of selecting covariates for unbiased estimation of the total causal effect.Existing approaches typically rely on global causal structure learning over all variables, or on strong assumptions such as causal sufficiency - where observed variables share no latent confounders - or the pretreatment assumption, which limits covariates to those unaffected by the treatment or outcome. These requirements are often unrealistic in practice, and global learning becomes computationally prohibitive in high-dimensional settings.To address these challenges, we propose a novel local learning method for covariate selection in nonparametric causal effect estimation that avoids both the pretreatment and causal sufficiency assumptions. We first characterize a local boundary that contains at least one valid adjustment set whenever one exists for identifying the causal effect, and then develop local identification procedures to efficiently search within this boundary.We prove that the proposed method is sound and complete. Experiments on multiple synthetic datasets and two real-world datasets show that our approach achieves accurate causal effect estimation while substantially improving computational efficiency.
A Recursive Decomposition Framework for Causal Structure Learning in the Presence of Latent Variables
May 11, 2026Constraint-based causal discovery is widely used for learning causal structures, but heavy reliance on conditional independence (CI) testing makes it computationally expensive in high-dimensional settings. To mitigate this limitation, many divide-and-conquer frameworks have been proposed, but most assume causal sufficiency, i.e., no latent variables. In this paper, we show that divide-and-conquer strategies can be theoretically generalized beyond causal sufficiency to settings with latent variables. Specifically, we propose a recursive decomposition framework, termed DiCoLa, that enables divide-and-conquer causal discovery in the presence of latent variables. It recursively decomposes the global learning task into smaller subproblems and integrates their solutions through a principled reconstruction step to recover the global structure. We theoretically establish the soundness and completeness of the proposed framework. Extensive experiments on synthetic data demonstrate that our approach significantly improves computational efficiency across a range of causal discovery algorithms, while experiments on a real-world dataset further illustrate its practical effectiveness.
PRIME: Prototype-Driven Multimodal Pretraining for Cancer Prognosis with Missing Modalities
Apr 05, 2026Multimodal self-supervised pretraining offers a promising route to cancer prognosis by integrating histopathology whole-slide images, gene expression, and pathology reports, yet most existing approaches require fully paired and complete inputs. In practice, clinical cohorts are fragmented and often miss one or more modalities, limiting both supervised fusion and scalable multimodal pretraining. We propose PRIME, a missing-aware multimodal self-supervised pretraining framework that learns robust and transferable representations from partially observed cohorts. PRIME maps heterogeneous modality embeddings into a unified token space and introduces a shared prototype memory bank for latent-space semantic imputation via patient-level consensus retrieval, producing structurally aligned tokens without reconstructing raw signals. Two complementary pretraining objectives: inter-modality alignment and post-fusion consistency under structured missingness augmentation, jointly learn representations that remain predictive under arbitrary modality subsets. We evaluate PRIME on The Cancer Genome Atlas with label-free pretraining on 32 cancer types and downstream 5-fold evaluation on five cohorts across overall survival prediction, 3-year mortality classification, and 3-year recurrence classification. PRIME achieves the best macro-average performance among all compared methods, reaching 0.653 C-index, 0.689 AUROC, and 0.637 AUROC on the three tasks, respectively, while improving robustness under test-time missingness and supporting parameter-efficient and label-efficient adaptation. These results support missing-aware multimodal pretraining as a practical strategy for prognosis modeling in fragmented clinical data settings.
EpiScreen: Early Epilepsy Detection from Electronic Health Records with Large Language Models
Mar 30, 2026Epilepsy and psychogenic non-epileptic seizures often present with similar seizure-like manifestations but require fundamentally different management strategies. Misdiagnosis is common and can lead to prolonged diagnostic delays, unnecessary treatments, and substantial patient morbidity. Although prolonged video-electroencephalography is the diagnostic gold standard, its high cost and limited accessibility hinder timely diagnosis. Here, we developed a low-cost, effective approach, EpiScreen, for early epilepsy detection by utilizing routinely collected clinical notes from electronic health records. Through fine-tuning large language models on labeled notes, EpiScreen achieved an AUC of up to 0.875 on the MIMIC-IV dataset and 0.980 on a private cohort of the University of Minnesota. In a clinician-AI collaboration setting, EpiScreen-assisted neurologists outperformed unaided experts by up to 10.9%. Overall, this study demonstrates that EpiScreen supports early epilepsy detection, facilitating timely and cost-effective screening that may reduce diagnostic delays and avoid unnecessary interventions, particularly in resource-limited regions.
HeartAgent: An Autonomous Agent System for Explainable Differential Diagnosis in Cardiology
Mar 11, 2026Heart diseases remain a leading cause of morbidity and mortality worldwide, necessitating accurate and trustworthy differential diagnosis. However, existing artificial intelligence-based diagnostic methods are often limited by insufficient cardiology knowledge, inadequate support for complex reasoning, and poor interpretability. Here we present HeartAgent, a cardiology-specific agent system designed to support a reliable and explainable differential diagnosis. HeartAgent integrates customized tools and curated data resources and orchestrates multiple specialized sub-agents to perform complex reasoning while generating transparent reasoning trajectories and verifiable supporting references. Evaluated on the MIMIC dataset and a private electronic health records cohort, HeartAgent achieved over 36% and 20% improvements over established comparative methods, in top-3 diagnostic accuracy, respectively. Additionally, clinicians assisted by HeartAgent demonstrated gains of 26.9% in diagnostic accuracy and 22.7% in explanatory quality compared with unaided experts. These results demonstrate that HeartAgent provides reliable, explainable, and clinically actionable decision support for cardiovascular care.
Confounded Causal Imitation Learning with Instrumental Variables
Jul 23, 2025Imitation learning from demonstrations usually suffers from the confounding effects of unmeasured variables (i.e., unmeasured confounders) on the states and actions. If ignoring them, a biased estimation of the policy would be entailed. To break up this confounding gap, in this paper, we take the best of the strong power of instrumental variables (IV) and propose a Confounded Causal Imitation Learning (C2L) model. This model accommodates confounders that influence actions across multiple timesteps, rather than being restricted to immediate temporal dependencies. We develop a two-stage imitation learning framework for valid IV identification and policy optimization. In particular, in the first stage, we construct a testing criterion based on the defined pseudo-variable, with which we achieve identifying a valid IV for the C2L models. Such a criterion entails the sufficient and necessary identifiability conditions for IV validity. In the second stage, with the identified IV, we propose two candidate policy learning approaches: one is based on a simulator, while the other is offline. Extensive experiments verified the effectiveness of identifying the valid IV as well as learning the policy.
Continually Evolved Multimodal Foundation Models for Cancer Prognosis
Jan 30, 2025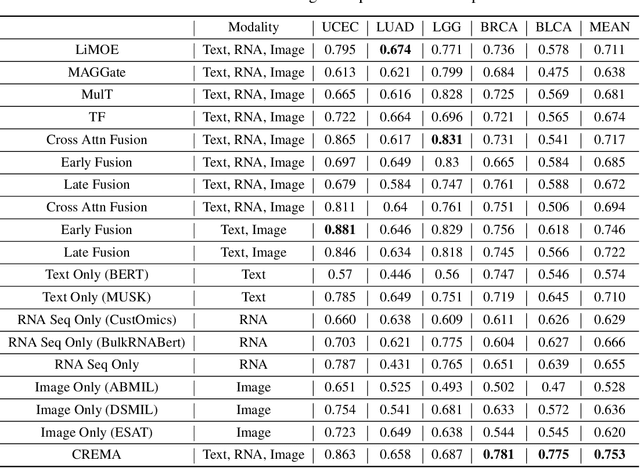
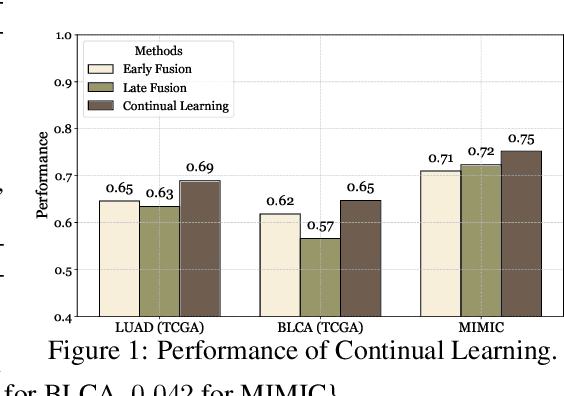
Cancer prognosis is a critical task that involves predicting patient outcomes and survival rates. To enhance prediction accuracy, previous studies have integrated diverse data modalities, such as clinical notes, medical images, and genomic data, leveraging their complementary information. However, existing approaches face two major limitations. First, they struggle to incorporate newly arrived data with varying distributions into training, such as patient records from different hospitals, thus rendering sub-optimal generalizability and limited utility in real-world applications. Second, most multimodal integration methods rely on simplistic concatenation or task-specific pipelines, which fail to capture the complex interdependencies across modalities. To address these, we propose a continually evolving multi-modal foundation model. Extensive experiments on the TCGA dataset demonstrate the effectiveness of our approach, highlighting its potential to advance cancer prognosis by enabling robust and adaptive multimodal integration.
Local Learning for Covariate Selection in Nonparametric Causal Effect Estimation with Latent Variables
Nov 25, 2024



Estimating causal effects from nonexperimental data is a fundamental problem in many fields of science. A key component of this task is selecting an appropriate set of covariates for confounding adjustment to avoid bias. Most existing methods for covariate selection often assume the absence of latent variables and rely on learning the global network structure among variables. However, identifying the global structure can be unnecessary and inefficient, especially when our primary interest lies in estimating the effect of a treatment variable on an outcome variable. To address this limitation, we propose a novel local learning approach for covariate selection in nonparametric causal effect estimation, which accounts for the presence of latent variables. Our approach leverages testable independence and dependence relationships among observed variables to identify a valid adjustment set for a target causal relationship, ensuring both soundness and completeness under standard assumptions. We validate the effectiveness of our algorithm through extensive experiments on both synthetic and real-world data.
Testability of Instrumental Variables in Additive Nonlinear, Non-Constant Effects Models
Nov 19, 2024



We address the issue of the testability of instrumental variables derived from observational data. Most existing testable implications are centered on scenarios where the treatment is a discrete variable, e.g., instrumental inequality (Pearl, 1995), or where the effect is assumed to be constant, e.g., instrumental variables condition based on the principle of independent mechanisms (Burauel, 2023). However, treatments can often be continuous variables, such as drug dosages or nutritional content levels, and non-constant effects may occur in many real-world scenarios. In this paper, we consider an additive nonlinear, non-constant effects model with unmeasured confounders, in which treatments can be either discrete or continuous, and propose an Auxiliary-based Independence Test (AIT) condition to test whether a variable is a valid instrument. We first show that if the candidate instrument is valid, then the AIT condition holds. Moreover, we illustrate the implications of the AIT condition and demonstrate that, in certain conditions, AIT conditions are necessary and sufficient to detect all invalid IVs. We also extend the AIT condition to include covariates and introduce a practical testing algorithm. Experimental results on both synthetic and three different real-world datasets show the effectiveness of our proposed condition.
Learning to Move Like Professional Counter-Strike Players
Aug 25, 2024



In multiplayer, first-person shooter games like Counter-Strike: Global Offensive (CS:GO), coordinated movement is a critical component of high-level strategic play. However, the complexity of team coordination and the variety of conditions present in popular game maps make it impractical to author hand-crafted movement policies for every scenario. We show that it is possible to take a data-driven approach to creating human-like movement controllers for CS:GO. We curate a team movement dataset comprising 123 hours of professional game play traces, and use this dataset to train a transformer-based movement model that generates human-like team movement for all players in a "Retakes" round of the game. Importantly, the movement prediction model is efficient. Performing inference for all players takes less than 0.5 ms per game step (amortized cost) on a single CPU core, making it plausible for use in commercial games today. Human evaluators assess that our model behaves more like humans than both commercially-available bots and procedural movement controllers scripted by experts (16% to 59% higher by TrueSkill rating of "human-like"). Using experiments involving in-game bot vs. bot self-play, we demonstrate that our model performs simple forms of teamwork, makes fewer common movement mistakes, and yields movement distributions, player lifetimes, and kill locations similar to those observed in professional CS:GO match play.
* The project website is at https://davidbdurst.com/mlmove/