 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSD-Score: Multi-Scale Distributional Scoring for Reference-Free Image Caption Evaluation
May 07, 2026Evaluating image captions without references remains challenging because global embedding similarity often misses fine-grained mismatches such as hallucinated objects, missing attributes, or incorrect relations. We propose MSD-Score, a reference-free metric that models image patch and text token embeddings as von Mises-Fisher mixtures on the unit hypersphere. Instead of treating each modality as a single point, MSD-Score formulates image-text matching as a multi-scale distributional scoring problem. Semantic discrepancies are quantified via a weighted bi-directional KL divergence and combined with global similarity in a multi-scale framework for both single- and multi-candidate evaluations. Extensive experiments show that MSD-Score achieves state-of-the-art correlation with human judgments among reference-free metrics. Beyond accuracy, its probabilistic formulation yields transparent and decomposable diagnostics of local grounding errors, providing a deterministic complementary signal to holistic similarity metrics and judge-based evaluators.
Dynamic Residual Encoding with Slide-Level Contrastive Learning for End-to-End Whole Slide Image Representation
Nov 07, 2025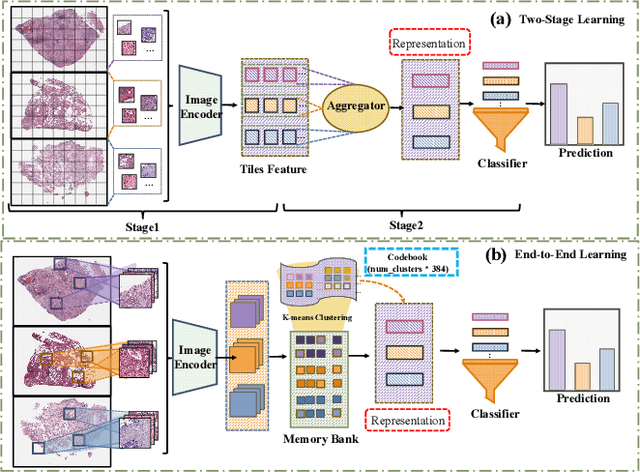

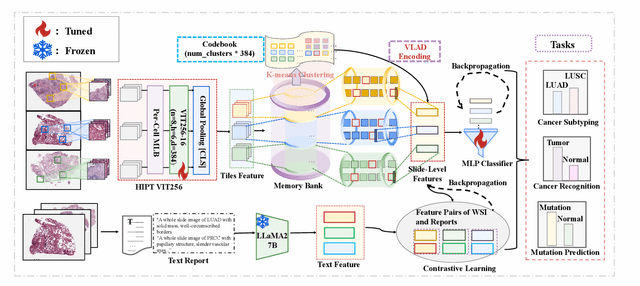
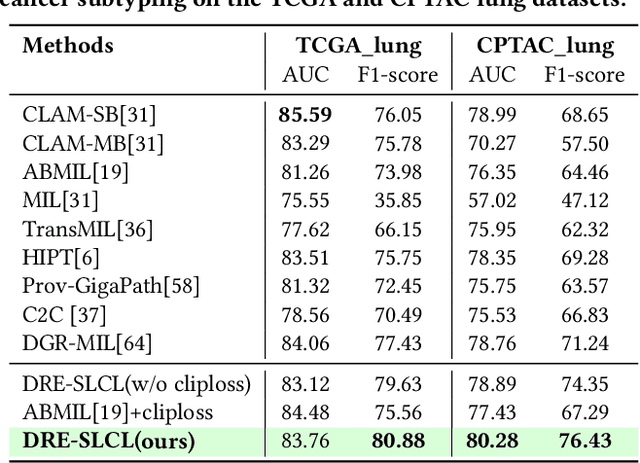
Whole Slide Image (WSI) representation is critical for cancer subtyping, cancer recognition and mutation prediction.Training an end-to-end WSI representation model poses significant challenges, as a standard gigapixel slide can contain tens of thousands of image tiles, making it difficult to compute gradients of all tiles in a single mini-batch due to current GPU limitations. To address this challenge, we propose a method of dynamic residual encoding with slide-level contrastive learning (DRE-SLCL) for end-to-end WSI representation. Our approach utilizes a memory bank to store the features of tiles across all WSIs in the dataset. During training, a mini-batch usually contains multiple WSIs. For each WSI in the batch, a subset of tiles is randomly sampled and their features are computed using a tile encoder. Then, additional tile features from the same WSI are selected from the memory bank. The representation of each individual WSI is generated using a residual encoding technique that incorporates both the sampled features and those retrieved from the memory bank. Finally, the slide-level contrastive loss is computed based on the representations and histopathology reports ofthe WSIs within the mini-batch. Experiments conducted over cancer subtyping, cancer recognition, and mutation prediction tasks proved the effectiveness of the proposed DRE-SLCL method.
* 8pages, 3figures, published to ACM Digital Library
TMCIR: Token Merge Benefits Composed Image Retrieval
Apr 15, 2025Composed Image Retrieval (CIR) retrieves target images using a multi-modal query that combines a reference image with text describing desired modifications. The primary challenge is effectively fusing this visual and textual information. Current cross-modal feature fusion approaches for CIR exhibit an inherent bias in intention interpretation. These methods tend to disproportionately emphasize either the reference image features (visual-dominant fusion) or the textual modification intent (text-dominant fusion through image-to-text conversion). Such an imbalanced representation often fails to accurately capture and reflect the actual search intent of the user in the retrieval results. To address this challenge, we propose TMCIR, a novel framework that advances composed image retrieval through two key innovations: 1) Intent-Aware Cross-Modal Alignment. We first fine-tune CLIP encoders contrastively using intent-reflecting pseudo-target images, synthesized from reference images and textual descriptions via a diffusion model. This step enhances the encoder ability of text to capture nuanced intents in textual descriptions. 2) Adaptive Token Fusion. We further fine-tune all encoders contrastively by comparing adaptive token-fusion features with the target image. This mechanism dynamically balances visual and textual representations within the contrastive learning pipeline, optimizing the composed feature for retrieval. Extensive experiments on Fashion-IQ and CIRR datasets demonstrate that TMCIR significantly outperforms state-of-the-art methods, particularly in capturing nuanced user intent.
How Does the Smoothness Approximation Method Facilitate Generalization for Federated Adversarial Learning?
Dec 11, 2024



Federated Adversarial Learning (FAL) is a robust framework for resisting adversarial attacks on federated learning. Although some FAL studies have developed efficient algorithms, they primarily focus on convergence performance and overlook generalization. Generalization is crucial for evaluating algorithm performance on unseen data. However, generalization analysis is more challenging due to non-smooth adversarial loss functions. A common approach to addressing this issue is to leverage smoothness approximation. In this paper, we develop algorithm stability measures to evaluate the generalization performance of two popular FAL algorithms: \textit{Vanilla FAL (VFAL)} and {\it Slack FAL (SFAL)}, using three different smooth approximation methods: 1) \textit{Surrogate Smoothness Approximation (SSA)}, (2) \textit{Randomized Smoothness Approximation (RSA)}, and (3) \textit{Over-Parameterized Smoothness Approximation (OPSA)}. Based on our in-depth analysis, we answer the question of how to properly set the smoothness approximation method to mitigate generalization error in FAL. Moreover, we identify RSA as the most effective method for reducing generalization error. In highly data-heterogeneous scenarios, we also recommend employing SFAL to mitigate the deterioration of generalization performance caused by heterogeneity. Based on our theoretical results, we provide insights to help develop more efficient FAL algorithms, such as designing new metrics and dynamic aggregation rules to mitigate heterogeneity.
HRDecoder: High-Resolution Decoder Network for Fundus Image Lesion Segmentation
Nov 06, 2024High resolution is crucial for precise segmentation in fundus images, yet handling high-resolution inputs incurs considerable GPU memory costs, with diminishing performance gains as overhead increases. To address this issue while tackling the challenge of segmenting tiny objects, recent studies have explored local-global fusion methods. These methods preserve fine details using local regions and capture long-range context information from downscaled global images. However, the necessity of multiple forward passes inevitably incurs significant computational overhead, adversely affecting inference speed. In this paper, we propose HRDecoder, a simple High-Resolution Decoder network for fundus lesion segmentation. It integrates a high-resolution representation learning module to capture fine-grained local features and a high-resolution fusion module to fuse multi-scale predictions. Our method effectively improves the overall segmentation accuracy of fundus lesions while consuming reasonable memory and computational overhead, and maintaining satisfying inference speed. Experimental results on the IDRID and DDR datasets demonstrate the effectiveness of our method. Code is available at https://github.com/CVIU-CSU/HRDecoder.
An efficient framework based on large foundation model for cervical cytopathology whole slide image screening
Jul 16, 2024



Current cervical cytopathology whole slide image (WSI) screening primarily relies on detection-based approaches, which are limited in performance due to the expense and time-consuming annotation process. Multiple Instance Learning (MIL), a weakly supervised approach that relies solely on bag-level labels, can effectively alleviate these challenges. Nonetheless, MIL commonly employs frozen pretrained models or self-supervised learning for feature extraction, which suffers from low efficacy or inefficiency. In this paper, we propose an efficient framework for cervical cytopathology WSI classification using only WSI-level labels through unsupervised and weakly supervised learning. Given the sparse and dispersed nature of abnormal cells within cytopathological WSIs, we propose a strategy that leverages the pretrained foundation model to filter the top$k$ high-risk patches. Subsequently, we suggest parameter-efficient fine-tuning (PEFT) of a large foundation model using contrastive learning on the filtered patches to enhance its representation ability for task-specific signals. By training only the added linear adapters, we enhance the learning of patch-level features with substantially reduced time and memory consumption. Experiments conducted on the CSD and FNAC 2019 datasets demonstrate that the proposed method enhances the performance of various MIL methods and achieves state-of-the-art (SOTA) performance. The code and trained models are publicly available at https://github.com/CVIU-CSU/TCT-InfoNCE.
Unsupervised Collaborative Metric Learning with Mixed-Scale Groups for General Object Retrieval
Mar 16, 2024



The task of searching for visual objects in a large image dataset is difficult because it requires efficient matching and accurate localization of objects that can vary in size. Although the segment anything model (SAM) offers a potential solution for extracting object spatial context, learning embeddings for local objects remains a challenging problem. This paper presents a novel unsupervised deep metric learning approach, termed unsupervised collaborative metric learning with mixed-scale groups (MS-UGCML), devised to learn embeddings for objects of varying scales. Following this, a benchmark of challenges is assembled by utilizing COCO 2017 and VOC 2007 datasets to facilitate the training and evaluation of general object retrieval models. Finally, we conduct comprehensive ablation studies and discuss the complexities faced within the domain of general object retrieval. Our object retrieval evaluations span a range of datasets, including BelgaLogos, Visual Genome, LVIS, in addition to a challenging evaluation set that we have individually assembled for open-vocabulary evaluation. These comprehensive evaluations effectively highlight the robustness of our unsupervised MS-UGCML approach, with an object level and image level mAPs improvement of up to 6.69% and 10.03%, respectively. The code is publicly available at https://github.com/dengyuhai/MS-UGCML.
POAR: Towards Open-World Pedestrian Attribute Recognition
Mar 26, 2023



Pedestrian attribute recognition (PAR) aims to predict the attributes of a target pedestrian in a surveillance system. Existing methods address the PAR problem by training a multi-label classifier with predefined attribute classes. However, it is impossible to exhaust all pedestrian attributes in the real world. To tackle this problem, we develop a novel pedestrian open-attribute recognition (POAR) framework. Our key idea is to formulate the POAR problem as an image-text search problem. We design a Transformer-based image encoder with a masking strategy. A set of attribute tokens are introduced to focus on specific pedestrian parts (e.g., head, upper body, lower body, feet, etc.) and encode corresponding attributes into visual embeddings. Each attribute category is described as a natural language sentence and encoded by the text encoder. Then, we compute the similarity between the visual and text embeddings of attributes to find the best attribute descriptions for the input images. Different from existing methods that learn a specific classifier for each attribute category, we model the pedestrian at a part-level and explore the searching method to handle the unseen attributes. Finally, a many-to-many contrastive (MTMC) loss with masked tokens is proposed to train the network since a pedestrian image can comprise multiple attributes. Extensive experiments have been conducted on benchmark PAR datasets with an open-attribute setting. The results verified the effectiveness of the proposed POAR method, which can form a strong baseline for the POAR task.
Contrastive Bayesian Analysis for Deep Metric Learning
Oct 10, 2022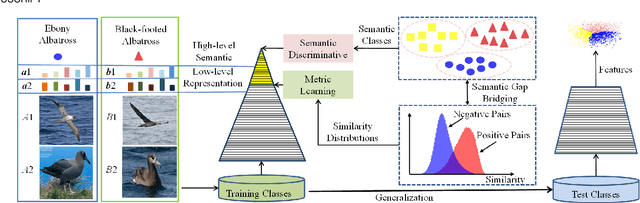
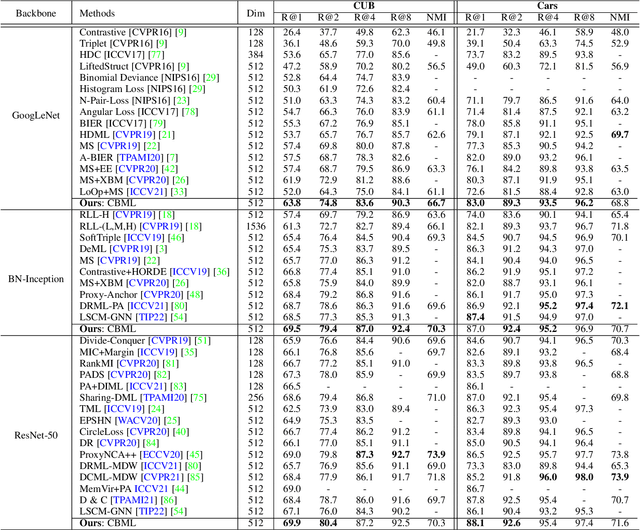
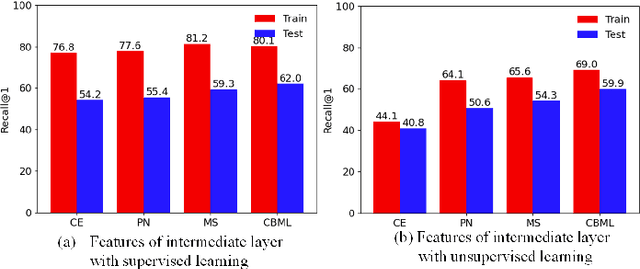
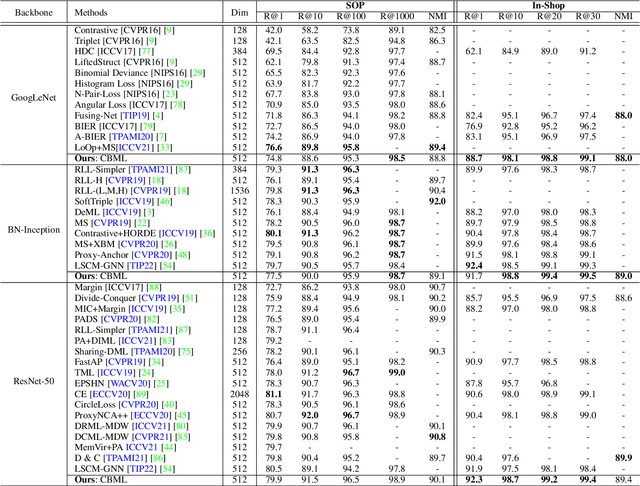
Recent methods for deep metric learning have been focusing on designing different contrastive loss functions between positive and negative pairs of samples so that the learned feature embedding is able to pull positive samples of the same class closer and push negative samples from different classes away from each other. In this work, we recognize that there is a significant semantic gap between features at the intermediate feature layer and class labels at the final output layer. To bridge this gap, we develop a contrastive Bayesian analysis to characterize and model the posterior probabilities of image labels conditioned by their features similarity in a contrastive learning setting. This contrastive Bayesian analysis leads to a new loss function for deep metric learning. To improve the generalization capability of the proposed method onto new classes, we further extend the contrastive Bayesian loss with a metric variance constraint. Our experimental results and ablation studies demonstrate that the proposed contrastive Bayesian metric learning method significantly improves the performance of deep metric learning in both supervised and pseudo-supervised scenarios, outperforming existing methods by a large margin.
Coded Residual Transform for Generalizable Deep Metric Learning
Oct 09, 2022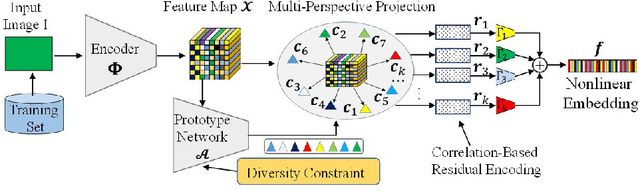

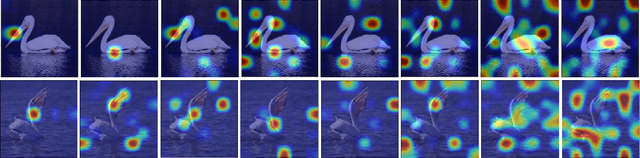
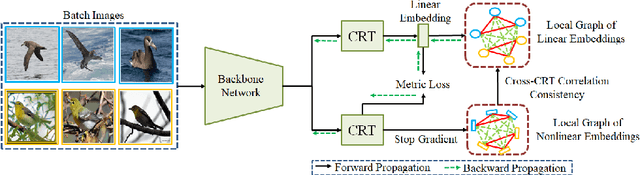
A fundamental challenge in deep metric learning is the generalization capability of the feature embedding network model since the embedding network learned on training classes need to be evaluated on new test classes. To address this challenge, in this paper, we introduce a new method called coded residual transform (CRT) for deep metric learning to significantly improve its generalization capability. Specifically, we learn a set of diversified prototype features, project the feature map onto each prototype, and then encode its features using their projection residuals weighted by their correlation coefficients with each prototype. The proposed CRT method has the following two unique characteristics. First, it represents and encodes the feature map from a set of complimentary perspectives based on projections onto diversified prototypes. Second, unlike existing transformer-based feature representation approaches which encode the original values of features based on global correlation analysis, the proposed coded residual transform encodes the relative differences between the original features and their projected prototypes. Embedding space density and spectral decay analysis show that this multi-perspective projection onto diversified prototypes and coded residual representation are able to achieve significantly improved generalization capability in metric learning. Finally, to further enhance the generalization performance, we propose to enforce the consistency on their feature similarity matrices between coded residual transforms with different sizes of projection prototypes and embedding dimensions. Our extensive experimental results and ablation studies demonstrate that the proposed CRT method outperform the state-of-the-art deep metric learning methods by large margins and improving upon the current best method by up to 4.28% on the CUB dataset.